- COVID-19 Tracker
- Biochemistry
- Anatomy & Physiology
- Microbiology
- Neuroscience
- Animal Kingdom
- NGSS High School
- Latest News
- Editors’ Picks
- Weekly Digest
- Quotes about Biology

Protein Synthesis
Reviewed by: BD Editors
Protein synthesis is process in which polypeptide chains are formed from coded combinations of single amino acids inside the cell. The synthesis of new polypeptides requires a coded sequence, enzymes, and messenger, ribosomal, and transfer ribonucleic acids (RNAs). Protein synthesis takes place within the nucleus and ribosomes of a cell and is regulated by DNA and RNA.

Protein Synthesis Steps
Protein synthesis steps are twofold. Firstly, the code for a protein (a chain of amino acids in a specific order) must be copied from the genetic information contained within a cell’s DNA. This initial protein synthesis step is known as transcription.
Transcription produces an exact copy of a section of DNA. This copy is known as messenger RNA (mRNA) which must then be transported outside of the cell nucleus before the next step of protein synthesis can begin.

The second protein synthesis step is translation. Translation occurs within a cell organelle called a ribosome. Messenger RNA makes its way to and connects with the ribosome under the influence of ribosomal RNA and enzymes. Transfer RNA (tRNA) is a molecule that carries a single amino acid and a coded sequence that acts like a key. This key fits into a specific sequence of three codes on the mRNA, bringing the correct amino acid into place. Each set of three mRNA nitrogenous bases is called a codon.
Translation and transcription will be explained in much more detail further on. In order to keep protein synthesis simple, we first need to know the basics.
Polypeptides and Proteins
The result of protein synthesis is a chain of amino acids that have been attached, link by link, in a specific order. This chain is called a polymer or polypeptide and is constructed according to a DNA-based code. You can picture a polypeptide chain as a string of beads, with each bead playing the part of an amino acid. The order in which the beads are strung are copied from instructions in our DNA.

When speaking of protein synthesis it is important to make a distinction between polypeptide chains and proteins. All proteins are polypeptides but not all polypeptides are proteins; however, both proteins and polypeptides are composed of amino acid monomers.
The difference between a protein and a polypeptide is the form. Smaller chains of amino acids – usually less than forty – remain as single-chain strands and are called polypeptides. Larger chains must package themselves more tightly; they fold into fixed structures – secondary, tertiary, and quaternary. When a polypeptide chain folds, it is called a protein.
Polypeptide chains are formed during the translation process of protein synthesis. These polypeptides may or may not fold into proteins at a later stage. However, the term ‘protein synthesis’ is used even in the scientific community and is not incorrect.

Understanding protein synthesis is easy when we imagine our DNA as a recipe book. This book lists the instructions that show a cell how to make every tiny part of every system, organ, and tissue within our bodies. All of these individual parts are polypeptides. From the keratin in your hair and fingernails to the hormones that run through your bloodstream, polypeptides and proteins are the foundation stones of every structure. Our DNA does not code for lipids or carbohydrates – it only codes for polypeptides.
The enzyme RNA polymerase opens the DNA recipe book that sits inside the cell nucleus. It uses certain pieces of code as bookmarks to find the right page. This recipe book is written in a foreign language – mRNA copies what is written without understanding it. The recipes are translated into a language that other molecules can decipher at a later stage. The translators are ribosomes and tRNA. They read the recipe and can collect the right ingredients and, in the correct order, make the finished polypeptide product.

DNA Sequences
In the nucleus, two strands of DNA are held together by nitrogenous bases (also called nucleobases or bases). Four bases – cytosine, guanine, adenine, and thymine – form the letters of the words in the DNA recipe book.
One strand of DNA holds the original code. If the instructions of this code are carefully followed, a specific correct polypeptide can be assembled outside the nucleus. The second DNA strand – the template strand – is a mirror image of the original strand. It must be a mirror image as nucleobases can only attach to complementary partners. For example, cytosine only ever pairs with guanine and thymine only pairs with adenine.

You will probably have seen codes such as CTA, ATA, TAA, and CCC in various biology textbooks. If these are the codons (sets of three bases) of the original strand of DNA, the template strand will attach to these using their partners. So using the given examples, template DNA will attach to the original DNA strand using GAT, TAT, ATT, and GGG.
Messenger RNA then copies the template strand. This means it ends up creating an exact copy of the original strand. The only difference is that mRNA replaces thymine with a base called uracil. The mRNA copy of the template strand using the given examples would read CUA, AUA, UAA, and CCC.

These codes can be read by transfer RNA outside the nucleus; the recipe can be understood by a molecule that does not fully understand the language used in the original (it does not understand thymine, only uracil). Transfer RNA helps to bring the right parts to the assembly line of the ribosome. There, a protein chain is constructed that matches the instructions in the original DNA strand.
Protein Synthesis Contributors
To make the copied stretch of code (transcription) we need enzymes called RNA polymerases. These enzymes gather free-floating messenger RNA (mRNA) molecules inside the nucleus and assemble them to form the letters of the code. Each letter of DNA code has its own key and each new letter formed by mRNA carries a lock that suits this key, a little like tRNA.
Notice that we are talking about letters. This is important. Inside the nucleus, the DNA code is not understood, simply copied down – transcribed. Understanding the code by spelling out the words formed by these letters – translating – happens at a later stage.

RNA polymerase must find and bring over the appropriate mRNA molecule for each nitrogenous base on the template strand. Selected mRNA molecules link together to form a chain of letters. Eventually, these letters will spell out the equivalent of a phrase. Each phrase represents a specific (polypeptide) product. If the recipe is not exactly followed, the final product might be completely different or not work as well as it should.
Messenger RNA has now become the code. It travels to the next group of important contributors that work as manufacturing plants. Ribosomes are found outside the cell nucleus, either in the cell cytoplasm or attached to the rough endoplasmic reticulum; it is ribosomes that make the endoplasmic reticulum ‘rough’.
A ribosome is split into two parts and the strand of mRNA runs through it like ribbon through an old-fashioned typewriter. The ribosome recognizes and connects to a special code at the start of the translated phrase – the start codon. Transfer RNA molecules enter the ribosome, bringing with them individual ingredients. As with all of these processes, enzymes are required to make the connections.

If each mRNA codon has a lock, tRNA possesses the keys. The tRNA key for an mRNA codon is called an anticodon. When a tRNA molecule holds the key that matches a three-nucleobase code it can open the door, drop off its load (an amino acid), and leave the ribosome factory to collect another amino acid load. This will always be the same type of amino acid as the anticodon.
Messenger RNA shifts along the ribosome as if on a conveyor belt. At the next codon another tRNA molecule (with the right key) brings the next amino acid. This amino acid bonds to the previous one. A chain of bonded amino acids begins to form– a polypeptide chain. When completed, this polypeptide chain is an accurate final product manufactured according to the instructions in the DNA recipe book. Not a pie or a cake but a polypeptide chain.

The end of the mRNA code translation process is signaled by a stop codon. Start and stop codons do not code for amino acids but tell the tRNA and ribosome where a polypeptide chain should begin and end.
The finished product – the newly synthesized polypeptide – is released into the cytoplasm. From there it can travel to wherever it is needed.
Site of Protein Synthesis
The site of protein synthesis is twofold. Transcription (copying the code) occurs within the cell nucleus where DNA is located. Once the mRNA copy of a small section of DNA has been made it travels through the nuclear pores and into the cell cytoplasm. In the cytoplasm, the strand of mRNA will move towards a free ribosome or one attached to the rough endoplasmic reticulum. Then the next step of protein synthesis – translation – can begin.
New Roles for Ribosomes
The average mammalian cell contains more than ten million ribosomes. Cancer cells can produce up to 7,500 ribosomal subunits (small and large) every minute. As a polypeptide-producing factory, the existence, development, and function of every living organism depends on the ribosome.

It was previously thought that eukaryotic ribosomes only played effector roles in protein synthesis (caused an effect – a new protein). However, recent research now shows that ribosomes also regulate the translation process. They play a part in deciding which proteins are manufactured and in what quantities. The success and results of translation depend on more than the availability of free amino acids and enzymes – they also depend on the quality of the ribosomes.
Transcription in Protein Synthesis
The transcription process is the first step of protein synthesis. This step transfers genetic information from DNA to the ribosomes of the cytoplasm or rough endoplasmic reticulum. Transcription is divided into three phases: initiation, elongation and termination.

Initiation requires two special protein groups. The first group is transcription factors – these recognize promoter sequences in the DNA. A promoter sequence is a section of code found at the start of a single gene that shows where the copying process should begin and in which direction this code should be read. A promoter works a little like the start codon on mRNA.
The second protein group necessary for transcription initiation consists of DNA-dependent RNA polymerases (RNAPs). An RNA polymerase molecule binds to the promoter. Once this connection has been made, the double-stranded DNA unwinds and opens (unzips).

Connected bases keep the two strands of DNA in a double-helix form. When the two strands unzip, the individual and now unpartnered bases are left exposed. The unzipping process is repeated along the stretch of DNA by RNAPs until the transcription stop point or terminator is reached. Intitiation, therefore, involves the recognition of a promotor sequence and the unzipping of a section of DNA under the influence of transcription factors and RNA polymerases.

The next phase in the transcription process is elongation. With the coded sequence exposed, RNAPs can read each individual adenine, guanine, cytosine, or thymine base on the template strand and connect the correct partner base to it. It is important to remember that RNA is unable to replicate thymine and replaces this with the nucleobase known as uracil.
If, for example, a short DNA sequence on the template strand is represented by C-A-G-T-T-A or cytosine-adenine-guanine-thymine-thymine-adenine, RNAP will connect the correct partner bases obtained from populations of free-floating bases within the nucleus. In this example, RNA polymerase will attach a guanine base to cytosine, uracil to adenine, cytosine to guanine, and adenine to thymine to form a strand of messenger RNA with the coded nitrogenous base sequence G-U-C-A-A-U. This process repeats until the RNAP enzyme detects a sequence of genetic code that terminates it – the terminator.

Termination
When the RNAPs detect a terminator sequence, the final phase of transcription – termination – takes place. The string of RNAPs disconnect from the DNA and the result is a strand of messenger RNA. This mRNA carries the code that will eventually instruct tRNA which amino acids to bring to a ribosome.
Messenger RNA leaves the nucleus via nuclear pores primarily through diffusion but sometimes needs help from transporter enzymes and ATP to reach its destination.
Translation Process in Protein Synthesis
During the translation process, the small and large subunits of a ribosome close over a strand of mRNA, trapping it loosely inside. Ribosomes arrange the strand into codons or sets of three nitrogenous base letters. This is because the code for a single amino acid – the most basic form of a protein – is a three-letter nucleobase code.
As ribosomes recognize parts of code, we can say they understand it. The jumble of copied letters made during the transcription phase can be read and understood in the translation phase.

For example, GGU, GGC, GGA, and GGG code for the amino acid known as glycine. Most amino acids have multiple codes as this lowers the chance of mistakes – if RNA polymerase accidently connects adenine instead of cytosine to GG, it doesn’t matter. Both GGC and GGA code for the same amino acid. You can see a list of mRNA codons for the twenty non-essential amino acids here .
There is only one start codon code – AUG. Three codons – TAA, TAG, and TGA – represent stop codons. Neither start nor stop codons match the code for an amino acid; they are non-coding. The single start and three stop codons are clearly marked on this codon wheel.

When a codon becomes visible – once the previous codon has been linked to an amino acid – a section of a transfer RNA molecule fits into the mRNA codon. This ‘key’ is called the anticodon. Transfer RNA has two roles – to attach to an amino acid outside of the ribosome and to deploy this amino acid at the right time and in the right position on an mRNA strand within the ribosome.
Tens to thousands of transfer RNA molecules produce a polypeptide chain. Titin or connectin is the largest protein molecule and contains around 33,000 amino acids. The smallest functional polypeptide is glutathione – just three amino acids. To produce glutathione, first the ribosome and tRNA must read the start codon (three bases), then read the first protein-coding codon (three bases), the second (three bases), the third (three bases), and the stop codon (three bases). The coding DNA and mRNA recipes (sequences) for glutathione contain nine bases. There may or may not be additional sections of non-coding DNA within this recipe. Non-coding sequences do not produce amino acids .
As with the process of transcription, translation within the ribosome is also split into the three stages of initiation, elongation, and termination.

Initiation involves the recognition by the ribosome of the mRNA start codon. Elongation refers to the process whereby the ribosome moves along the mRNA transcript, recognizing and exposing individual codons so that tRNA can bring the right amino acids. The anticodon arm of tRNA attaches to the appropriate mRNA codon under the influence of ribosomal enzymes.
Finally, termination occurs when the ribosome recognizes the mRNA stop codon; the completed polypeptide chain is then released into the cytoplasm. It is sent wherever it is needed – inside the cell or to other tissues, exiting the cell membrane via exocytosis.

1. What are promotor sequences?
2. Which mRNA nitrogenous base is partner to the DNA base adenine?
3. RNAPs do what during translation initiation?
4. How many amino acids make up the protein glutathione?
Enter your email to receive results:
Bibliography
- Barna M. (2013). Ribosomes take control. Proceedings of the National Academy of Sciences of the United States of America , 110 (1), 9–10. https://doi.org/10.1073/pnas.1218764110
- Hatfield DL, Lee JL, Pirtle RM (Ed). (2018). Transfer RNA in Protein Synthesis.Boca Raton (FL), CRC Press.
- Rodwell, VW, Bender DA, Botham KM, Kennelly PJ, Weil PA. (2018). Harper’s Illustrated Biochemistry Thirty-First Edition. New York, McGraw Hill Professional.
- Vargas DY, Raj A, Marras SAE, Kramer FR, Tyagi S. (2005). Mechanism of mRNA transport in the nucleus. Proceedings of the National Academy of Sciences . Nov 2005, 102 (47) 17008-17013; DOI: 10.1073/pnas.0505580102
Cite This Article
Subscribe to our newsletter, privacy policy, terms of service, scholarship, latest posts, white blood cell, t cell immunity, satellite cells, embryonic stem cells, popular topics, photosynthesis, scientific method, endocrine system, mitochondria.

- DNA Replication
- Active Transport
- Cellular Receptors
- Endocytosis and Exocytosis
- Enzyme Inhibition
- Enzyme Kinetics
- Protein Structure
Transcription of DNA
- Translation of DNA
- Anaerobic Respiration
- Electron Transport Chain
- Gluconeogenesis
- Calcium Regulation
- External Balance of Potassium
- Internal Balance of Potassium
- Sodium Regulation
- Cell Membrane
- Endoplasmic Reticulum
- Golgi Apparatus
- Mitochondria
- Blood Vessels
- Cellular Adaptations
- Epithelial Cells
- Muscle Histology
- Structure of Glands
- Control of Stroke Volume
- Control of Heart Rate
- Cardiac Cycle
- Cardiac Pacemaker Cells
- Conduction System
- Contraction of Cardiac Muscle
- Ventricular Action Potentials
- Blood Flow in Vessels
- Control of Blood Pressure
- Capillary Exchange
- Flow In Peripheral Circulation
- Venous Return
- Cardiac Muscle
- Hepatic Circulation
- Skeletal Muscle
- Airway Resistance
- Lung Volumes
- Mechanics of Breathing
- Gas Exchange
- Oxygen Transport in The Blood
- Transport of Carbon Dioxide in the Blood
- Ventilation-Perfusion Matching
- Chemoreceptors
- Cough Reflex
- Neural Control of Ventilation
- Respiratory Regulation of Acid-Base Balance
- Responses of The Respiratory System to Stress
- Regulation of Saliva
- Secretion of Saliva
- Gastric Acid Production
- Gastric Mucus Production
- Digestion and Absorption
- Histology and Cellular Function of the Small Intestine
- Absorption in the Large Intestine
- Large Intestinal Motility
- Bilirubin Metabolism
- Carbohydrate Metabolism in the Liver
- Lipid Metabolism in the Liver
- Protein and Ammonia Metabolism in the Liver
- Storage Functions of the Liver
- Bile Production
- Function of The Spleen
- Exocrine Pancreas
- Somatostatin
- Proximal Convoluted Tubule
- Loop of Henle
- Distal Convoluted Tubule and Collecting Duct
- Storage Phase of Micturition
- Voiding Phase of Micturition
- Antidiuretic Hormone
- Renin-Angiotensin-Aldosterone System
- Urinary Regulation of Acid-Base Balance
- Water Filtration and Reabsorption
- Development of the Reproductive System
- Gametogenesis
- Gonadotropins and the Hypothalamic Pituitary Axis
- Menstrual Cycle
- Placental Development
- Fetal Circulation
- Maternal Adaptations in Pregnancy
- Cells of the Nervous System
- Central Nervous System
- Cerebrospinal Fluid
- Neurotransmitters
- Peripheral Nervous System
- Action Potential
- Excitatory and Inhibitory Synaptic Signalling
- Resting Membrane Potential
- Synaptic Plasticity
- Synaptic Transmission
- Ascending Tracts
- Auditory Pathway
- Consciousness and Sleep
- Modalities of Sensation
- Pain Pathways
- Sensory Acuity
- Visual Pathway
- Descending Tracts
- Lower Motor Neurones
- Muscle Stretch Reflex
- Upper Motor Neurones
- Aqueous Humour
- Ocular Accommodation
- Thyroid Gland
- Parathyroid Glands
- Adrenal Medulla
- Zona Glomerulosa
- Zona Fasciculata
- Zona Reticularis
- Endocrine Pancreas
- The Hypothalamus
- Anterior Pituitary
- Posterior Pituitary
- White Blood Cells – Summary
- Barriers to Infection
- Infection Recognition Molecules
- Phagocytosis
- The Complement System
- Antigen Processing and Presentation
- Primary and Secondary Immune Responses
- T Cell Memory
- Acute Inflammation
- Autoimmunity
- Chronic Inflammation
- Hypersensitivity Reactions
- Immunodeficiency
- Types of Immunity
- Antibiotics
- Viral Infection
- Blood Groups
- Coagulation
- Erythropoiesis
- Iron Metabolism
- Mononuclear Phagocyte System
Original Author(s): Aradhya Vijayakumar Last updated: 8th April 2024 Revisions: 68
- 1 RNA Vs DNA
- 2.1 Initiation
- 2.2 Elongation
- 2.3 Termination
- 3.1 5′ Capping
- 3.2 Polyadenylation
- 3.3 Splicing
- 4 Clinical Relevance – Phenylketonuria (PKU)
DNA transcription is the process by which the genetic information contained within DNA is re-written into messenger RNA (mRNA) by RNA polymerase . This mRNA then exits the nucleus, where it acts as the basis for the translation of DNA. By controlling the production of mRNA within the nucleus, the cell regulates the rate of gene expression.
In this article, we will look at the process of DNA transcription, including the post-transcriptional modification of mRNA and its importance.
RNA, like DNA, is a polymer of three subunits joined by phosphodiester bonds . However, as detailed in the table below, there are key differences in the monomer units for each compound.
| Deoxyribose | Ribose | |
| Adenine, guanine, cytosine, thymine | Adenine, guanine, cytosine, uracil | |
| Double-stranded helix | Single-stranded helix |
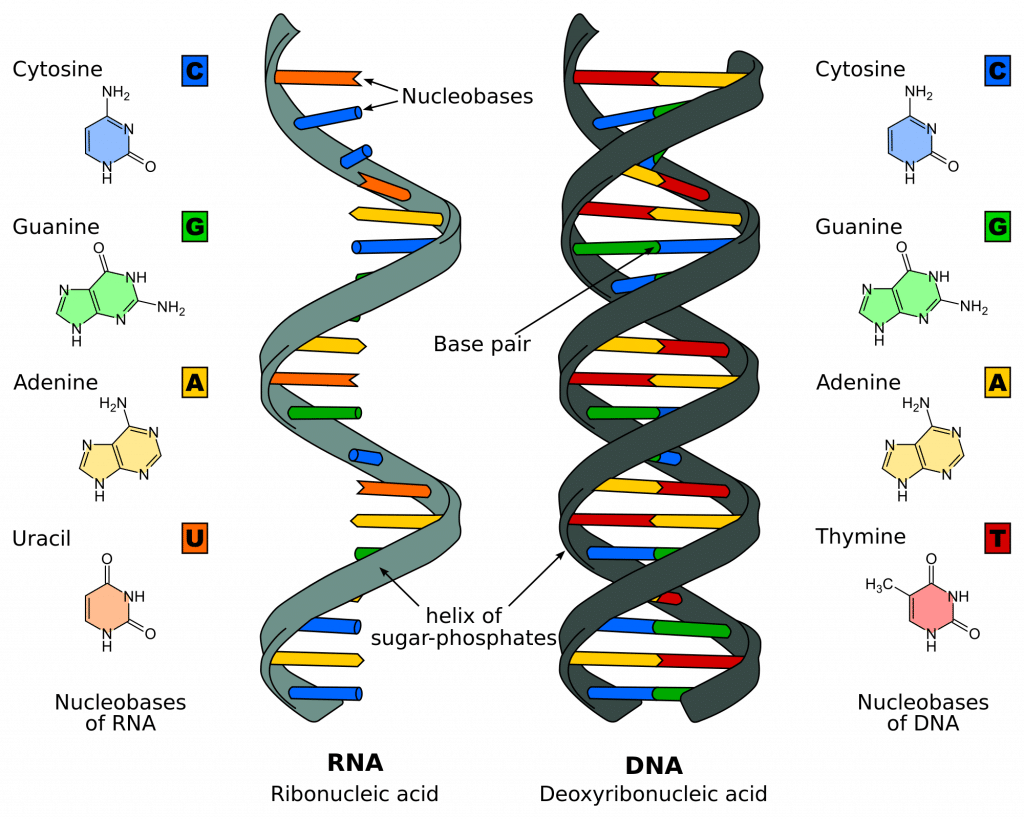
Figure 1 – Comparison of DNA and RNA
Stages of Transcription
The process of DNA transcription can be split into 3 main stages: initiation, elongation & termination. These steps are also involved in DNA replication .
Transcription is catalysed by the enzyme RNA polymerase , which attaches to and moves along the DNA molecule until it recognises a promoter sequence . This area of DNA indicates the starting point of transcription, and there may be multiple promoter sequences within a DNA molecule. Transcription factors are proteins that control the rate of transcription; they too bind to the promoter sequences with RNA polymerase.
Once bound to the promoter sequence, RNA polymerase unwinds a portion of the DNA double helix, exposing the bases on each of the two DNA strands.
One DNA strand (the template strand ) is read in a 3′ to 5′ (three-prime to five-prime) direction, and so provides the template for the new mRNA molecule. The other DNA strand is referred to as the coding strand. This is because its base sequence is identical to the synthesised mRNA, except for the replacement of thiamine bases with uracil .
RNA polymerase uses incoming ribonucleotides to form the new mRNA strand. It does this by catalysing the formation of phosphodiester bonds between adjacent ribonucleotides, using complementary base pairing (A to U, T to A, C to G, and G to C). Bases can only be added to the 3′ end, so the strand elongates in a 5’ to 3’ direction.
Termination
Elongation continues until the RNA polymerase encounters a stop sequence. At this point, transcription stops, and the RNA polymerase releases the DNA template.
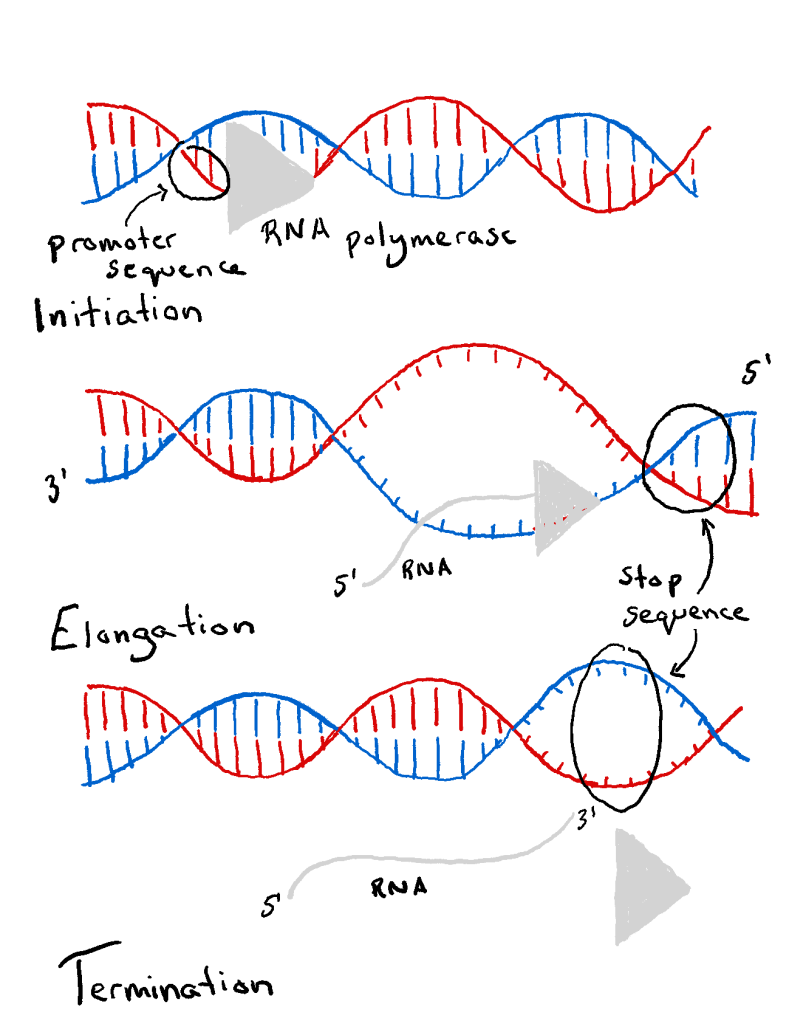
Fig 2 – The stages of DNA transcription
Pre-translational mRNA processing
The mRNA which has been transcribed up to this point is referred to as pre-mRNA . Processing must occur to convert this into mature mRNA. This includes:
Capping describes the addition of a methylated guanine cap to the 5′ end of mRNA. Its presence is vital for the recognition of the molecule by ribosomes, and to protect the immature molecule from degradation by RNAases.
Polyadenylation
Polyadenylation describes the addition of a poly(A) tail to the 3′ end of mRNA. The poly(A) tail consists of multiple molecules of adenosine monophosphate. This helps to stabilise RNA, which is necessary as RNA is much more unstable than DNA.
Splicing allows the genetic sequence of a single pre-mRNA to code for many different proteins, conserving genetic material. This process is sequence-dependent and occurs within the transcript. It involves:
- Removal of introns (non-coding sequences) via spliceosome excision
- Joining together of exons (coding sequence) by ligation

Fig 3 – Post-transcriptional modification of pre-mRNA
By the end of transcription, mature mRNA has been made. This acts as the messaging system to allow translation and protein synthesis to occur.
Within the mature mRNA, is the open reading frame (ORF). This region will be translated into protein. It is translated in blocks of three nucleotides, called codons. At the 5’ and 3’ ends, there are also untranslated regions (UTRs). These are not translated during protein synthesis.
Clinical Relevance – Phenylketonuria (PKU)
PKU occurs due to a single base pair substitution (G to A) in the enzyme phenylalanine hydroxylase. This results in intron skipping, producing unstable mRNA. PKU is one of several genetic conditions tested for in babies via the newborn blood spot (heel prick) test.
Individuals with phenylketonuria accumulate phenylalanine in their tissues, plasma, and urine. Phenylketones are also found in their urine. This results in intellectual disability, developmental delay, microcephaly, seizures, and hypopigmentation.
Treatment includes consuming diets low in phenylalanine and avoiding high-protein foods such as meat, milk, and eggs.
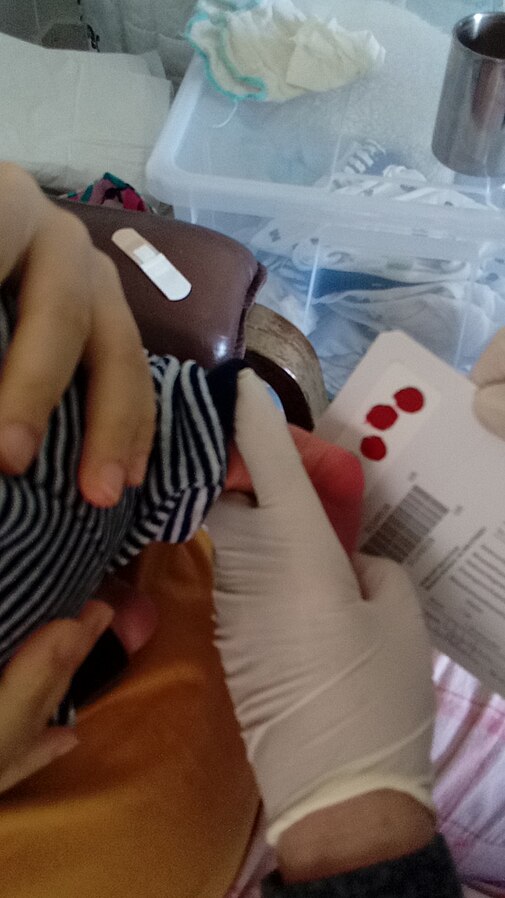
Fig 4 – Neonatal heel prick testing
| Deoxyribose | Ribose | |
| Adenine, guanine, cytosine, thymine | Adenine, guanine, cytosine, uracil | |
| Double-stranded helix | Single-stranded helix |
One DNA strand (the template strand ) is read in a 3' to 5' (three-prime to five-prime) direction, and so provides the template for the new mRNA molecule. The other DNA strand is referred to as the coding strand. This is because its base sequence is identical to the synthesised mRNA, except for the replacement of thiamine bases with uracil .
RNA polymerase uses incoming ribonucleotides to form the new mRNA strand. It does this by catalysing the formation of phosphodiester bonds between adjacent ribonucleotides, using complementary base pairing (A to U, T to A, C to G, and G to C). Bases can only be added to the 3' end, so the strand elongates in a 5’ to 3’ direction.
Capping describes the addition of a methylated guanine cap to the 5' end of mRNA. Its presence is vital for the recognition of the molecule by ribosomes, and to protect the immature molecule from degradation by RNAases.
Polyadenylation describes the addition of a poly(A) tail to the 3' end of mRNA. The poly(A) tail consists of multiple molecules of adenosine monophosphate. This helps to stabilise RNA, which is necessary as RNA is much more unstable than DNA.
[start-clinical]
Clinical Relevance - Phenylketonuria (PKU)
[end-clinical]
Found an error? Is our article missing some key information? Make the changes yourself here!
Once you've finished editing, click 'Submit for Review', and your changes will be reviewed by our team before publishing on the site.
We use cookies to improve your experience on our site and to show you relevant advertising. To find out more, read our privacy policy .
Privacy Overview
| Cookie | Duration | Description |
|---|---|---|
| cookielawinfo-checkbox-analytics | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics". |
| cookielawinfo-checkbox-functional | 11 months | The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional". |
| cookielawinfo-checkbox-necessary | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary". |
| cookielawinfo-checkbox-others | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other. |
| cookielawinfo-checkbox-performance | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance". |
| viewed_cookie_policy | 11 months | The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data. |
- Why Does Water Expand When It Freezes
- Gold Foil Experiment
- Faraday Cage
- Oil Drop Experiment
- Magnetic Monopole
- Why Do Fireflies Light Up
- Types of Blood Cells With Their Structure, and Functions
- The Main Parts of a Plant With Their Functions
- Parts of a Flower With Their Structure and Functions
- Parts of a Leaf With Their Structure and Functions
- Why Does Ice Float on Water
- Why Does Oil Float on Water
- How Do Clouds Form
- What Causes Lightning
- How are Diamonds Made
- Types of Meteorites
- Types of Volcanoes
- Types of Rocks
Protein Synthesis
Protein synthesis, as the name implies, is the process by which every cell produces specific proteins in its ribosome. In this process, polypeptide chains are formed from varying amounts of 20 different amino acids. It is one of the fundamental biological processes in both prokaryotes and eukaryotes. This is a vital process, as the proteins formed take part in every major cellular activities, ranging from catalysis to forming various structural elements of the cell.
In 1958, Francis Crick proposed a theory called central dogma to describe the flow of genetic information from DNA to RNA to protein. According to this framework, protein is formed from RNA via translation , which in turn, is formed from DNA through transcription.
DNA → RNA → Protein
i. DNA → RNA (Transcription)
ii. RNA → Protein (Translation)
Where and When does Protein Synthesis Take Place
In both prokaryotes and eukaryotes, protein synthesis occurs in the ribosome. That’s why the ribosome is called the ‘protein factory’ of the cell.
However, in eukaryotes , the ribosomes remain scattered in the cytoplasm and are also attached to the Endoplasmic reticulum (RER). So, generally, it is said that, in eukaryotes, the process occurs in the cytoplasm and RER.
On the other hand, in prokaryotes , the ribosomes are scattered throughout the cell cytoplasm. So, commonly, it is said that, in prokaryotes, it takes place in the cytoplasm.
Process: How does it Work
The process of protein synthesis occurs in two steps: transcription and translation. In the first step, DNA is used as a template to make a messenger RNA molecule (mRNA). The mRNA thus formed, exits the nucleus through a nuclear pore and travels to the ribosome for the next step, translation. Upon reaching the ribosome, the genetic code in mRNA is read and used for polypeptide synthesis.
Below is a flowchart of the overall process:
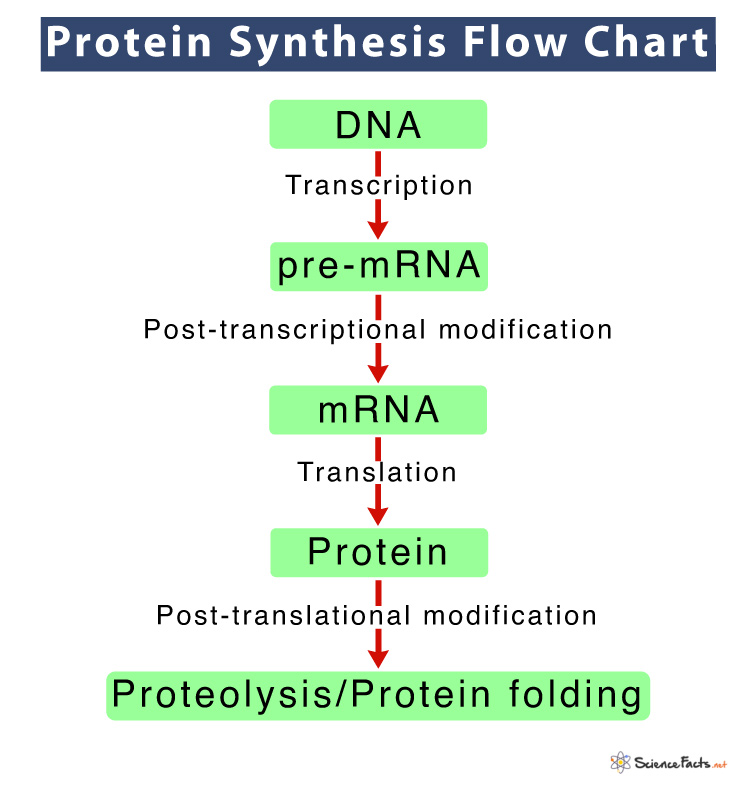
Now, let us discuss these two steps of protein synthesis in detail:
1) Transcription: The First Step of Protein Synthesis
In this process, a single-stranded mRNA molecule is transcribed from a double-stranded DNA molecule. The mRNA thus formed is used as a template for the next step, translation.
The three steps of transcription are: initiation, elongation, and termination.
i) Initiation
The process of transcription begins when the enzyme RNA polymerase binds to a region of a gene called the promoter sequence with the assistance of certain transcription factors. Due to this binding, the double-stranded DNA starts to unwind at the promoter region, forming a transcription bubble. Among the two strands of DNA, one that is used as a template to produce mRNA is called the template, noncoding, or antisense strand. On the other hand, the other one is called the coding or sense strand.
ii) Elongation
After the opening of DNA, the attached RNA polymerase moves along the template strand of the DNA, creating complementary base pairing of that strand to form mRNA. As a result of this, an mRNA transcript containing a copy of the coding strand of DNA is formed. The only exception is, in the mRNA, the nitrogenous base thymine gets replaced by uracil. The sugar-phosphate backbone forms through RNA polymerase.
iii) Termination
Once the mRNA strand is complete, the hydrogen bonds between the RNA-DNA helix break. As a result, the mRNA detaches from the DNA and undergoes further processing.
Post Transcriptional Modification: mRNA Processing
The mRNA formed at the end of the transcription process is called pre-mRNA, as it is not fully ready prepared to enter translation. So, before leaving the nucleus, it needs to undergo some modifications or processing to transform into a mature mRNA. Following these modifications a single gene can produce more than one protein.
a. Splicing
The pre-mRNA is comprised of introns and exons. Introns are the regions that do not code for the protein, whereas exons are the regions that code for the protein.In splicing, noncoding regions or introns of the mRNA get removed under the influence of ribonucleoproteins.
Here, the mRNA gets edited, that is, its some of the nucleotides get changed. For instance, a human protein called Apolipoprotein B (APOB), which helps in lipid transportation in the blood, comes in two different forms due to this editing. One form is smaller than the other because an earlier stop signal gets added in mRNA due to editing.
c. 5’ Capping
In this process, a methylated cap is added to the 5′ end or ‘head’ of the mRNA, replacing the triphosphate group. This cap helps with mRNA recognition by the ribosome during translation, and also protects the mRNA from breaking down.
d. Polyadenylation
At the opposite end of the RNA transcript, that is, to the 3′ end of the RNA chain 30-500 adenines are added, forming the poly A tail. It signals the end of mRNA, and is involved in exporting mRNA from the nucleus.
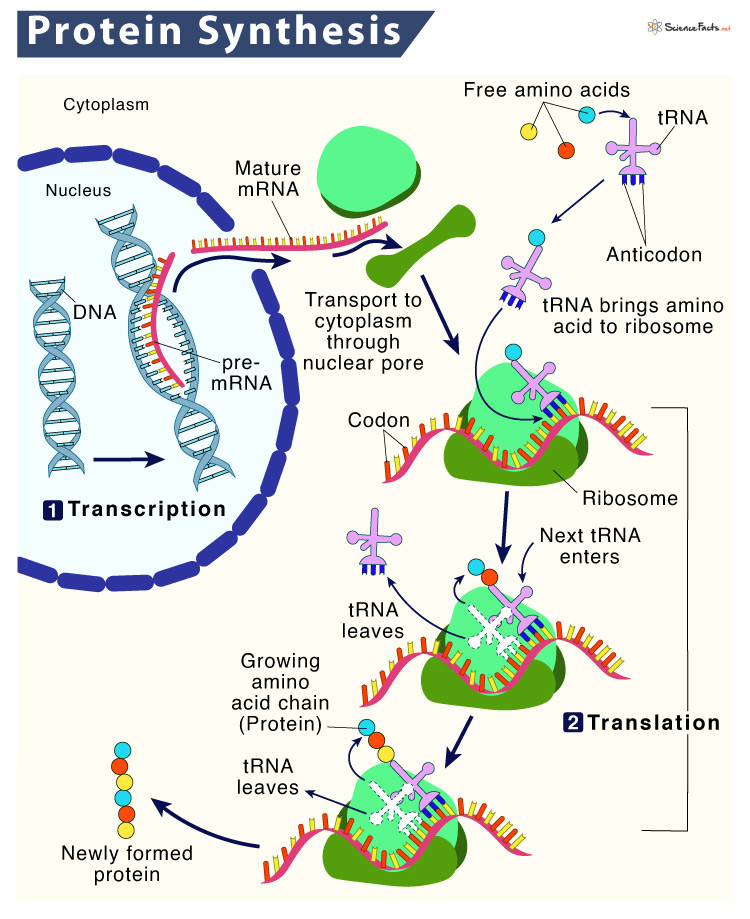
2) Translation: The Second Step of Protein Synthesis
Translation, the next major step of protein synthesis is the process in which the genetic code in mRNA is read to make the amino acids, which are linked together in a particular order based on the genetic code, forming protein.
Similar to transcription, translation also occurs in three stages: initiation, elongation, and termination.
After the mature mRNA leaves the nucleus, it travels to a ribosome. The 5′ methylated cap of the mRNA, containing the strat codon binds to the small ribosomal subunit of the ribosome consisting rRNA. Next, a tRNA containing anticodons complementary to the start codon on the mRNA attaches to the ribosome. These mRNA, ribosome, and tRNA together form an initiation complex.The ribosome reads the sequence of codons in mRNA, and tRNA bring amino acids to the ribosome in the proper sequence.
Once the initiation complex is formed, the large ribosomal subunit of ribosome binds to this complex, releasing initiation factors (IFs). The large subunit of the ribosome has three sites for tRNA binding; A site, P site, and E site. The A (amino acid) site is the region, where the complementary anticodons of aminoacyl-tRNA (tRNA with amino acid) pairs up with the mRNA codon. This ensures that correct amino acid is added to the growing polypeptide chain at the P (polypeptide) site. Once this transfer is complete, the tRNA leaves the ribosome at the E (exit) site and returns to the cytoplasm to bind another amino acid. The whole process gets repeated continuously and the polypeptide chain gets elongated. The rRNA binds the newly formed amino acids via peptide bond, forming the polypeptide chains.
The 3′ poly A tail of the mRNA holds a stop codon that signals to end the elongation stage. A specialized protein called release factor gets attached to the tail o mRNA, causing the entire initiation complex along with the polypeptide chain to break down. As a result, all the components are released.
What Happens Next
After translation, the newly formed polypeptide chain undergoes either of the two post-translational modifications discussed below:
- Proteolysis : Here, the proteins get cleaved, that is, their N-terminal, C-terminal, or the internal amino-acid residues are removed from the polypeptide by the action of proteases.
- Protein folding : In this stage, the nascent proteins get folded to achieve the secondary and tertiary structures.
After these modifications, the protein may bind with other polypeptides or with different types of molecules, such as lipids or carbohydrates, forming lipoproteins or glycoproteins, respectively. Many proteins travel to the Golgi apparatus where they are modified according to their role in cell.
Why is Protein Synthesis Important
As we can see, this complex process of protein synthesis leads to the formation of proteins that plays several crucial roles in cells, including formation of structural components of cell, like cell membrane , cell repair, producing hormones, enzymes, and many more.
Why is it Different in Prokaryotes and Eukaryotes
The speed of protein synthesis is different in prokaryotes and eukaryotes. In prokaryotes, the process is faster, as the whole process takes place in the cytoplasm. On the other hand, in eukaryotes it is slower, as the pre- mRNA is first synthesized in the nucleus and after splicing, the mature mRNA comes to the cytoplasm for translation.
Ans. mRNA carries the coding sequences for protein synthesis from DNA to ribosome. tRNA decodes a specific codon of mRNA and transfers a specific amino acid to the ribosome.
Ans. Three types of RNAs are involved in protein synthesis: messenger RNA (mRNA), transfer RNA (tRNA), and ribosomal RNA (rRNA).
Ans. Deoxyribonucleic acid (DNA) provides the master code for protein synthesis.
Ans . The codon AUG, coding for methionine starts protein synthesis.
Ans . The two organelles that are involved in protein synthesis are: nucleus and ribosome.
Ans . Well defined reading frames are critical in protein synthesis, because without a well-defined reading frame, the peptide made from a given sequence could be completely different.
Ans . Yes, protein synthesis requires energy.
Ans . Protein synthesis is the process of producing a functional protein molecule based on the information in the genes. On the contrary, DNA replication produces a replica of an existing DNA molecule.
- Protein Synthesis – Flexbooks.ck12.org
- Translation: DNA to mRNA to Protein – Nature.com
- What is protein synthesis – Proteinsynthesis.org
- Translation: Making Protein Synthesis Possible – Thoughtco.com
- Protein Synthesis in the Cell and the Central Dogma – Study.com
Article was last reviewed on Friday, February 17, 2023
Related articles

Leave a Reply Cancel reply
Your email address will not be published. Required fields are marked *
Save my name, email, and website in this browser for the next time I comment.
Popular Articles
Join our Newsletter
Fill your E-mail Address
Related Worksheets
- Privacy Policy
© 2024 ( Science Facts ). All rights reserved. Reproduction in whole or in part without permission is prohibited.

- $ 0.00 0 items

Transcription and translation
Genes provide information for building proteins . They don’t however directly create proteins. The production of proteins is completed through two processes: transcription and translation.
Transcription and translation take the information in DNA and use it to produce proteins. Transcription uses a strand of DNA as a template to build a molecule called RNA.
The RNA molecule is the link between DNA and the production of proteins. During translation, the RNA molecule created in the transcription process delivers information from the DNA to the protein-building machines.
DNA → RNA → Protein
DNA and RNA are similar molecules and are both built from smaller molecules called nucleotides. Proteins are made from a sequence of amino acids rather than nucleotides. Transcription and translation are the two processes that convert a sequence of nucleotides from DNA into a sequence of amino acids to build the desired protein.
These two processes are essential for life. They are found in all organisms – eukaryotic and prokaryotic . Converting genetic information into proteins has kept life in existence for billions of years.
DNA and RNA
RNA and DNA are very similar molecules. They are both nucleic acids (one of the four molecules of life ), they are both built on a foundation of nucleotides and they both contain four nitrogenous bases that pair up.
A strand of DNA contains a chain of connecting nucleotides. Each nucleotide contains a sugar, and a nitrogenous base and a phosphate group. There is a total of four different nitrogenous bases in DNA: adenine (A), thymine (T), guanine (G), and cytosine (C).
A strand of DNA is almost always found bonded to another strand of DNA in a double helix. Two strands of DNA are bonded together by their nitrogenous bases. The bases form what are called ‘base pairs’ where adenine and thymine bond together and guanine and cytosine bond together.
Adenine and thymine are complementary bases and do not bond with the guanine and cytosine. Guanine and cytosine only bond with each other and not adenine or thymine.
There are a couple of key differences between the structure of DNA and RNA molecules. They contain different sugars. DNA has a deoxyribose sugar while RNA has a ribose sugar.
While three of their four nitrogenous bases are the same, RNA molecules the have a base called uracil (U) instead of a thymine base. During transcription, uracil replaces the position of thymine and forms complementary pairs with adenine.
Transcription
Transcription is the process of producing a strand of RNA from a strand of DNA. Similar to the way DNA is used as a template in DNA replication , it is again used as a template during transcription. The information that is stored in DNA molecules is rewritten or ‘transcribed’ into a new RNA molecule.
Sequence of nitrogenous bases and the template strand
Each nitrogenous base of a DNA molecule provides a piece of information for protein production. A strand of DNA has a specific sequence of bases. The specific sequence provides the information for the production of a specific protein.
Through transcription, the sequence of bases of the DNA is transcribed into the reciprocal sequence of bases in a strand of RNA. Through transcription, the information of the DNA molecule is passed onto the new strand of RNA which can then carry the information to where proteins are produced. RNA molecules used for this purpose are known as messenger RNA (mRNA).
A gene is a particular segment of DNA. The sequence of bases in for a gene determines the sequence of nucleotides along an RNA molecule.
Only one strand of a DNA double helix is transcribed for each gene. This strand is known as the ‘template strand’. The same template strand of DNA is used every time that particular gene is transcribed. The opposite strand of the DNA double helix may be transcribed for other genes.
RNA polymerase
An enzyme called ‘RNA polymerase’ is responsible for separating the two strands of DNA in a double helix. As it separates the two strands, RNA polymerase builds a strand of mRNA by adding the complementary nucleotides (A, U, G, C) to the template strand of DNA.
A specific set of nucleotides along the template strand of DNA indicates where the gene starts and where the RNA polymerase should attach and begin unravelling the double helix. The section of DNA or the gene that is transcribed is known as the ‘transcription unit’.
Rather than RNA polymerase moving along the DNA strand, the DNA moves through the RNA polymerase enzyme. As the template strand moves through the enzyme, it is unravelled and RNA nucleotides are added to the growing mRNA molecule.
As the RNA molecule grows it is separated from the template strand. The DNA template strand reforms the bonds with its complementary DNA strand to reform a double helix.
In prokaryotic cells, such as bacteria , once a specific sequence of nucleotides has been transcribed then transcription is completed. This specific sequence of nucleotides is called the ‘terminator sequence’.
Once the terminator sequence is transcribed, RNA polymerase detaches from the DNA template strand and releases the RNA molecule. No further modifications are required for the mRNA molecule and it is possible for translation to begin immediately. Translation can begin in bacteria while transcription is still occurring.
Modification of mRNA in eukaryotic cells
Creating a completed mRNA molecule isn’t quite as simple in eukaryotic cells. Like prokaryotic cells, the end of a transcription unit is signalled by a certain sequence of nucleotides. Unlike prokaryotic cells, however, RNA polymerase continues to add nucleotides after transcribing the terminator sequence.
Proteins are required to release the RNA polymerase from the template DNA strand and the RNA molecule is modified to remove the extra nucleotides along with certain unwanted sections of the RNA strand. The remaining sections are spliced together and the final mRNA strand is ready for translation.
In eukaryotic cells, transcription of a DNA strand must be complete before translation can begin. The two processes are separated by the membrane of the nucleus so they cannot be performed on the same strand at the same time as they are in prokaryotic cells.
Rate of transcription
If a certain protein is required in large numbers, one gene can be transcribed by several RNA polymerase enzymes at one time. This makes it possible for a large number of proteins to be produced from multiple RNA molecules in a short time.
Translation
Translation is the process where the information carried in mRNA molecules is used to create proteins. The specific sequence of nucleotides in the mRNA molecule provides the code for the production of a protein with a specific sequence of amino acids.
Much like how RNA is built from many nucleotides, a protein is formed from many amino acids. A chain of amino acids is called a ‘polypeptide chain’ and a polypeptide chain bends and folds on itself to form a protein.
During translation, the information of the strand of RNA is ‘translated’ from RNA language into polypeptide language i.e. the sequence of nucleotides is translated into a sequence of amino acids.
Translation occurs in ribosomes
Ribosomes are small cellular machines that control the production of proteins in cells. They are made from proteins and RNA molecules and provide a platform for mRNA molecules to couple with complimentary transfer RNA (tRNA) molecules.
Each tRNA molecule is bound to an amino acid and delivers the necessary amino acid to the ribosome. The tRNA molecules bind to the complementary bases of the mRNA molecule.
The bonded mRNA and tRNA are fed through the ribosome and the amino acid attached to the tRNA molecule is added to the growing polypeptide chain as it moves through the ribosome.
Nucleotide bases are translated into 20 different amino acids
RNA molecules only contain four different types of nitrogenous bases but there are 20 different amino acids that are used to build proteins. In order to turn four into 20, a combination of three nitrogenous bases provides the information for one amino acid.

A strand of mRNA obviously has multiple codons which provide the information for multiple amino acids. A tRNA molecule reads along one codon of the mRNA strand and collects the necessary amino acid from the cytoplasm.
The tRNA returns to the ribosome with the amino acid, binds to the complementary bases of the mRNA codon, and the amino acid is added to the end of polypeptide chain as the RNA molecules move through the ribosome.
There is a different tRNA molecule for each of the different codons of the mRNA strand. Each tRNA molecule contains three nitrogenous bases that are complementary to the three bases of a codon on the mRNA strand.
The three bases of the tRNA molecule are known as an anticodon. For example, an mRNA codon with bases UGU would have a complementary tRNA with an anticodon AGA.
The opposite end of the tRNA molecule has a site where a specific amino acid can bind to. When the tRNA recognises its complementary codon in the mRNA strand, it goes to collects its specific amino acid. The amino acid is bonded to the tRNA molecule by enzymes in the cytoplasm.
As the tRNA molecule returns with the amino acid, the anticodon of the tRNA binds to the codon of the mRNA and moves through the ribosome. Each tRNA molecule can collect and deliver multiple amino acids. One codon at a time, amino acids are brought to the ribosome and the polypeptide chain is built.
Ribosome binding sites
Ribosomes have three sites for different stages of interaction with tRNA and mRNA: the P site, A site and E site. The P site is where the ribosome holds the polypeptide chain and where the tRNA adds its amino acid to the growing chain.
The A site is where tRNA molecules bind to the codons of the mRNA strand and the E site or exit site is where the tRNA is released from the ribosome and the mRNA strand.
Translation begins when a ribosome binds to an mRNA strand and an initiator tRNA. The initiator tRNA delivers an amino acid called ‘methionine’ directly to the P site and keeps the A site open for the second tRNA molecule to bind to.
The strand of mRNA moves through the ribosome from the A site to the P site and exits at the E site. Molecules of tRNA bind to the codons of the mRNA at the A site before moving to the P site where their amino acid is attached to the end of the growing polypeptide chain.
Once tRNA molecules have released their amino acids they move into the E site and are released from the mRNA and ribosome. As one tRNA molecule moves from the P site into the E site another tRNA molecule moves from the A site into the P site and delivers the next amino acid to the polypeptide chain.
Termination of translation and modification of the polypeptide
Translation ends when a stop codon on the mRNA strand reaches the A site in the ribosome. The stop codon doesn’t have a complementary tRNA or anticodon.
Instead, a protein called a ‘release factor’ binds to the stop codon and adds a water molecule to the polypeptide chain when it moves into the P site. Once the water molecule is added to the polypeptide, the polypeptide is released from the ribosome.
It is common for multiple strands of mRNA to be translated simultaneously by multiple ribosomes. This greatly increases the rate of protein production.
A polypeptide chain must fold on itself to create its final shape as a protein. As the polypeptide is being made it is already folding into a protein. Other proteins are used to guide the polypeptide to fold into the correct shape.
Often a polypeptide chain will need to be modified before it is able to perform properly. A range of molecules, such as sugars and lipids , can be added to the polypeptide. Likewise, the polypeptide chain may be split into smaller chains or have amino acids removed.
Last edited: 31 August 2020

eBook - $2.95
Also available from Amazon , Book Depository and all other good bookstores.
What does DNA stand for?
Know the answer? Why not test yourself with our quick 20 question quiz
Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.
5.7 Protein Synthesis
Created by: CK-12/Adapted by Christine Miller
The Art of Protein Synthesis
This amazing artwork (Figure 5.7.1) shows a process that takes place in the cells of all living things: the production of proteins. This process is called protein synthesis , and it actually consists of two processes — transcription and translation . In eukaryotic cells, transcription takes place in the nucleus . During transcription, DNA is used as a template to make a molecule of messenger RNA ( mRNA ). The molecule of mRNA then leaves the nucleus and goes to a ribosome in the cytoplasm , where translation occurs. During translation, the genetic code in mRNA is read and used to make a polypeptide. These two processes are summed up by the central dogma of molecular biology: DNA → RNA → Protein .
Transcription
Transcription is the first part of the central dogma of molecular biology: DNA → RNA . It is the transfer of genetic instructions in DNA to mRNA. During transcription, a strand of mRNA is made to complement a strand of DNA. You can see how this happens in Figure 5.7.2.
Transcription begins when the enzyme RNA polymerase binds to a region of a gene called the promoter sequence. This signals the DNA to unwind so the enzyme can “read” the bases of DNA. The two strands of DNA are named based on whether they will be used as a template for RNA or not. The strand that is used as a template is called the template strand, or can also be called the a ntisense strand. The sequence of bases on the opposite strand of DNA is called the coding or sense strand. Once the DNA has opened, and RNA polymerase has attached, the RNA polymerase moves along the DNA, adding RNA nucleotides to the growing mRNA strand. The template strand of DNA is used as to create mRNA through complementary base pairing. Once the mRNA strand is complete, and it detaches from DNA. The result is a strand of mRNA that is nearly identical to the coding strand DNA – the only difference being that DNA uses the base thymine, and the mRNA uses uracil in the place of thymine
Processing mRNA
In eukaryotes , the new mRNA is not yet ready for translation. At this stage, it is called pre-mRNA, and it must go through more processing before it leaves the nucleus as mature mRNA. The processing may include splicing, editing, and polyadenylation. These processes modify the mRNA in various ways. Such modifications allow a single gene to be used to make more than one protein.
- Splicing removes introns from mRNA, as shown in Figure 5.7.3. Introns are regions that do not code for the protein. The remaining mRNA consists only of regions called exons that do code for the protein. The ribonucleoproteins in the diagram are small proteins in the nucleus that contain RNA and are needed for the splicing process.
- Editing changes some of the nucleotides in mRNA. For example, a human protein called APOB, which helps transport lipids in the blood, has two different forms because of editing. One form is smaller than the other because editing adds an earlier stop signal in mRNA.
- 5′ Capping adds a methylated cap to the “head” of the mRNA. This cap protects the mRNA from breaking down, and helps the ribosomes know where to bind to the mRNA
- Polyadenylation adds a “tail” to the mRNA. The tail consists of a string of As (adenine bases). It signals the end of mRNA. It is also involved in exporting mRNA from the nucleus, and it protects mRNA from enzymes that might break it down.
Translation
Translation is the second part of the central dogma of molecular biology: RNA → Protein . It is the process in which the genetic code in mRNA is read to make a protein . Translation is illustrated in Figure 5.7.4. After mRNA leaves the nucleus , it moves to a ribosome , which consists of rRNA and proteins. The ribosome reads the sequence of codons in mRNA, and molecules of tRNA bring amino acids to the ribosome in the correct sequence.
Translation occurs in three stages: Initiation, Elongation and Termination.
Initiation:
After transcription in the nucleus, the mRNA exits through a nuclear pore and enters the cytoplasm. At the region on the mRNA containing the methylated cap and the start codon, the small and large subunits of the ribosome bind to the mRNA. These are then joined by a tRNA which contains the anticodons matching the start codon on the mRNA. This group of molecues (mRNA, ribosome, tRNA) is called an initiation complex.
Elongation:
tRNA keep bringing amino acids to the growing polypeptide according to complementary base pairing between the codons on the mRNA and the anticodons on the tRNA. As a tRNA moves into the ribosome, its amino acid is transferred to the growing polypeptide. Once this transfer is complete, the tRNA leaves the ribosome, the ribosome moves one codon length down the mRNA, and a new tRNA enters with its corresponding amino acid. This process repeats and the polypeptide grows.
Termination :
At the end of the mRNA coding is a stop codon which will end the elongation stage. The stop codon doesn’t call for a tRNA, but instead for a type of protein called a release factor, which will cause the entire complex (mRNA, ribosome, tRNA, and polypeptide) to break apart, releasing all of the components.
Watch this video “Protein Synthesis (Updated) with the Amoeba Sisters” to see this process in action:
Protein Synthesis (Updated), Amoeba Sisters, 2018.
What Happens Next?
After a polypeptide chain is synthesized, it may undergo additional processes. For example, it may assume a folded shape due to interactions between its amino acids. It may also bind with other polypeptides or with different types of molecules, such as lipids or carbohydrates . Many proteins travel to the Golgi apparatus within the cytoplasm to be modified for the specific job they will do. 7 Summary
5.7 Summary
- Protein synthesis is the process in which cells make proteins. It occurs in two stages: transcription and translation.
- Transcription is the transfer of genetic instructions in DNA to mRNA in the nucleus. It includes three steps: initiation, elongation, and termination. After the mRNA is processed, it carries the instructions to a ribosome in the cytoplasm.
- Translation occurs at the ribosome, which consists of rRNA and proteins. In translation, the instructions in mRNA are read, and tRNA brings the correct sequence of amino acids to the ribosome. Then, rRNA helps bonds form between the amino acids, producing a polypeptide chain.
- After a polypeptide chain is synthesized, it may undergo additional processing to form the finished protein.
5.7 Review Questions
- Relate protein synthesis and its two major phases to the central dogma of molecular biology.
- Explain how mRNA is processed before it leaves the nucleus.
- What additional processes might a polypeptide chain undergo after it is synthesized?
- Where does transcription take place in eukaryotes?
- Where does translation take place?
5.7 Explore More
Protein Synthesis, Teacher’s Pet, 2014.
Attributions
Figure 5.7.1
How proteins are made by Nicolle Rager, National Science Foundation on Wikimedia Commons is released into the public domain (https://en.wikipedia.org/wiki/Public_domain) .
Figure 5.7.2
Transcription by National Human Genome Research Institute , (reworked and vectorized by Sulai) on Wikimedia Commons is released into the public domain (https://en.wikipedia.org/wiki/Public_domain) .
Figure 5.7.3
Pre mRNA processing by Christine Miller is used under a CC BY-NC-SA 4.0 (https://creativecommons.org/licenses/by-nc-sa/4.0/) license.
Figure 5.7.4
Translation by CNX OpenStax on Wikimedia Commons is used under a CC BY 4.0 (https://creativecommons.org/licenses/by/4.0) license.
Amoeba Sisters. (2018, January 18) Protein synthesis (Updated). YouTube. https://www.youtube.com/watch?v=oefAI2x2CQM&feature=youtu.be
Parker, N., Schneegurt, M., Thi Tu, A-H., Lister, P., Forster, B.M. (2016, November 1). Microbiology [online]. Figure 11.15 Translation in bacteria begins with the formation of the initiation complex. In Microbiology (Section 11-4). OpenStax. https://openstax.org/books/microbiology/pages/11-4-protein-synthesis-translation
Teacher’s Pet. (2014, December 7). Protein synthesis. YouTube. https://www.youtube.com/watch?v=2zAGAmTkZNY&feature=youtu.be
The process of creating protein molecules.
The process by which DNA is copied (transcribed) to mRNA in order transfer the information needed for protein synthesis.
The process in which mRNA along with transfer RNA (tRNA) and ribosomes work together to produce polypeptides.
Cells which have a nucleus enclosed within membranes, unlike prokaryotes, which have no membrane-bound organelles.
A central organelle containing hereditary material.
Deoxyribonucleic acid - the molecule carrying genetic instructions for the development, functioning, growth and reproduction of all known organisms and many viruses.
A large family of RNA molecules that convey genetic information from DNA to the ribosome, where they specify the amino acid sequence of the protein products of gene expression.
A large complex of RNA and protein which acts as the site of RNA translation, building proteins from amino acids using messenger RNA as a template.
The jellylike material that makes up much of a cell inside the cell membrane, and, in eukaryotic cells, surrounds the nucleus. The organelles of eukaryotic cells, such as mitochondria, the endoplasmic reticulum, and (in green plants) chloroplasts, are contained in the cytoplasm.
A nucleic acid of which many different kinds are now known, including messenger RNA, transfer RNA and ribosomal RNA.
A class of biological molecule consisting of linked monomers of amino acids and which are the most versatile macromolecules in living systems and serve crucial functions in essentially all biological processes.
The addition of a poly(A) tail to a messenger RNA. The poly(A) tail consists of multiple adenosine monophosphates.
A sequence of 3 DNA or RNA nucleotides that corresponds with a specific amino acid or stop signal during protein synthesis.
A small RNA molecule that participates in protein synthesis. Each tRNA molecule has two important areas: an anticodon and a region for attaching a specific amino acid.
Amino acids are organic compounds that combine to form proteins.
A substance that is insoluble in water. Examples include fats, oils and cholesterol. Lipids are made from monomers such as glycerol and fatty acids.
A biomolecule consisting of carbon (C), hydrogen (H) and oxygen (O) atoms, usually with a hydrogen–oxygen atom ratio of 2:1. Complex carbohydrates are polymers made from monomers of simple carbohydrates, also termed monosaccharides.
A membrane-bound organelle found in eukaryotic cells made up of a series of flattened stacked pouches with the purpose of collecting and dispatching protein and lipid products received from the endoplasmic reticulum (ER). Also referred to as the Golgi complex or the Golgi body.
Human Biology Copyright © 2020 by Christine Miller is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License , except where otherwise noted.
Share This Book
DNA, RNA and protein synthesis
Mistakes in dna replication, formation of pre-messenger rna, rna splicing, alternative splicing, reverse transcription, translation, transfer rna, an exercise in the use of the genetic code, the wobble hypothesis, transcription, translation and replication.
The genetic material is stored in the form of DNA in most organisms. In humans, the nucleus of each cell contains 3 × 10 9 base pairs of DNA distributed over 23 pairs of chromosomes, and each cell has two copies of the genetic material. This is known collectively as the human genome. The human genome contains around 30 000 genes, each of which codes for one protein.
Large stretches of DNA in the human genome are transcribed but do not code for proteins. These regions are called introns and make up around 95% of the genome. The nucleotide sequence of the human genome is now known to a reasonable degree of accuracy but we do not yet understand why so much of it is non-coding. Some of this non-coding DNA controls gene expression but the purpose of much of it is not yet understood. This is a fascinating subject that is certain to advance rapidly over the next few years.
The Central Dogma of Molecular Biology states that DNA makes RNA makes proteins ( Figure 1 ).
The process by which DNA is copied to RNA is called transcription , and that by which RNA is used to produce proteins is called translation .
DNA replication
Each time a cell divides, each of its double strands of DNA splits into two single strands. Each of these single strands acts as a template for a new strand of complementary DNA. As a result, each new cell has its own complete genome. This process is known as DNA replication . Replication is controlled by the Watson-Crick pairing of the bases in the template strand with incoming deoxynucleoside triphosphates, and is directed by DNA polymerase enzymes. It is a complex process, particularly in eukaryotes, involving an array of enzymes. A simplified version of bacterial DNA replication is described in Figure 2 .
DNA biosynthesis proceeds in the 5'- to 3'-direction. This makes it impossible for DNA polymerases to synthesize both strands simultaneously. A portion of the double helix must first unwind, and this is mediated by helicase enzymes.
The leading strand is synthesized continuously but the opposite strand is copied in short bursts of about 1000 bases, as the lagging strand template becomes available. The resulting short strands are called Okazaki fragments (after their discoverers, Reiji and Tsuneko Okazaki). Bacteria have at least three distinct DNA polymerases: Pol I, Pol II and Pol III; it is Pol III that is largely involved in chain elongation. Strangely, DNA polymerases cannot initiate DNA synthesis de novo , but require a short primer with a free 3'-hydroxyl group. This is produced in the lagging strand by an RNA polymerase (called DNA primase) that is able to use the DNA template and synthesize a short piece of RNA around 20 bases in length. Pol III can then take over, but it eventually encounters one of the previously synthesized short RNA fragments in its path. At this point Pol I takes over, using its 5'- to 3'-exonuclease activity to digest the RNA and fill the gap with DNA until it reaches a continuous stretch of DNA. This leaves a gap between the 3'-end of the newly synthesized DNA and the 5'-end of the DNA previously synthesized by Pol III. The gap is filled by DNA ligase, an enzyme that makes a covalent bond between a 5'-phosphate and a 3'-hydroxyl group ( Figure 3 ). The initiation of DNA replication at the leading strand is more complex and is discussed in detail in more specialized texts.
DNA replication is not perfect. Errors occur in DNA replication, when the incorrect base is incorporated into the growing DNA strand. This leads to mismatched base pairs, or mispairs . DNA polymerases have proofreading activity, and a DNA repair enzymes have evolved to correct these mistakes. Occasionally, mispairs survive and are incorporated into the genome in the next round of replication. These mutations may have no consequence, they may result in the death of the organism, they may result in a genetic disease or cancer; or they may give the organism a competitive advantage over its neighbours, which leads to evolution by natural selection.
Transcription
Transcription is the process by which DNA is copied ( transcribed ) to mRNA, which carries the information needed for protein synthesis. Transcription takes place in two broad steps. First, pre-messenger RNA is formed, with the involvement of RNA polymerase enzymes. The process relies on Watson-Crick base pairing, and the resultant single strand of RNA is the reverse-complement of the original DNA sequence. The pre-messenger RNA is then "edited" to produce the desired mRNA molecule in a process called RNA splicing .
The mechanism of transcription has parallels in that of DNA replication . As with DNA replication, partial unwinding of the double helix must occur before transcription can take place, and it is the RNA polymerase enzymes that catalyze this process.
Unlike DNA replication, in which both strands are copied, only one strand is transcribed. The strand that contains the gene is called the sense strand, while the complementary strand is the antisense strand. The mRNA produced in transcription is a copy of the sense strand, but it is the antisense strand that is transcribed.
Ribonucleoside triphosphates (NTPs) align along the antisense DNA strand, with Watson-Crick base pairing (A pairs with U). RNA polymerase joins the ribonucleotides together to form a pre-messenger RNA molecule that is complementary to a region of the antisense DNA strand.wxh Transcription ends when the RNA polymerase enzyme reaches a triplet of bases that is read as a "stop" signal. The DNA molecule re-winds to re-form the double helix.
The pre-messenger RNA thus formed contains introns which are not required for protein synthesis. The pre-messenger RNA is chopped up to remove the introns and create messenger RNA (mRNA) in a process called RNA splicing ( Figure 5 ).
In alternative splicing, individual exons are either spliced or included, giving rise to several different possible mRNA products. Each mRNA product codes for a different protein isoform; these protein isoforms differ in their peptide sequence and therefore their biological activity. It is estimated that up to 60% of human gene products undergo alternative splicing. Several different mechanisms of alternative splicing are known, two of which are illustrated in Figure 6 .
Alternative splicing contributes to protein diversity - a single gene transcript (RNA) can have thousands of different splicing patterns, and will therefore code for thousands of different proteins: a diverse proteome is generated from a relatively limited genome. Splicing is important in genetic regulation (alteration of the splicing pattern in response to cellular conditions changes protein expression). Perhaps not surprisingly, abnormal splicing patterns can lead to disease states including cancer.
In reverse transcription, RNA is "reverse transcribed" into DNA. This process, catalyzed by reverse transcriptase enzymes, allows retroviruses, including the human immunodeficiency virus (HIV), to use RNA as their genetic material. Reverse transcriptase enzymes have also found applications in biotechnology, allowing scientists to convert RNA to DNA for techniques such as PCR .
The mRNA formed in transcription is transported out of the nucleus, into the cytoplasm, to the ribosome (the cell's protein synthesis factory). Here, it directs protein synthesis. Messenger RNA is not directly involved in protein synthesis - transfer RNA (tRNA) is required for this. The process by which mRNA directs protein synthesis with the assistance of tRNA is called translation .
The ribosome is a very large complex of RNA and protein molecules. Each three-base stretch of mRNA (triplet) is known as a codon , and one codon contains the information for a specific amino acid. As the mRNA passes through the ribosome, each codon interacts with the anticodon of a specific transfer RNA (tRNA) molecule by Watson-Crick base pairing. This tRNA molecule carries an amino acid at its 3'-terminus, which is incorporated into the growing protein chain. The tRNA is then expelled from the ribosome. Figure 7 shows the steps involved in protein synthesis.
Transfer RNA adopts a well defined tertiary structure which is normally represented in two dimensions as a cloverleaf shape, as in Figure 7 . The structure of tRNA is shown in more detail in Figure 8 .
Each amino acid has its own special tRNA (or set of tRNAs). For example, the tRNA for phenylalanine (tRNAPhe) is different from that for histidine (tRNAHis). Each amino acid is attached to its tRNA through the 3'-OH group to form an ester which reacts with the α-amino group of the terminal amino-acid of the growing protein chain to form a new amide bond (peptide bond) during protein synthesis ( Figure 9 ). The reaction of esters with amines is generally favourable but the rate of reaction is increased greatly in the ribosome.
Each transfer RNA molecule has a well defined tertiary structure that is recognized by the enzyme aminoacyl tRNA synthetase, which adds the correct amino acid to the 3'-end of the uncharged tRNA. The presence of modified nucleosides is important in stabilizing the tRNA structure. Some of these modifications are shown in Figure 10 .
The Genetic code
The genetic code is almost universal. It is the basis of the transmission of hereditary information by nucleic acids in all organisms. There are four bases in RNA (A,G,C and U), so there are 64 possible triplet codes (4 3 = 64). In theory only 22 codes are required: one for each of the 20 naturally occurring amino acids, with the addition of a start codon and a stop codon (to indicate the beginning and end of a protein sequence). Many amino acids have several codes ( degeneracy ), so that all 64 possible triplet codes are used. For example Arg and Ser each have 6 codons whereas Trp and Met have only one. No two amino acids have the same code but amino acids whose side-chains have similar physical or chemical properties tend to have similar codon sequences, e.g. the side-chains of Phe, Leu, Ile, Val are all hydrophobic, and Asp and Glu are both carboxylic acids (see genetic code ). This means that if the incorrect tRNA is selected during translation (owing to mispairing of a single base at the codon-anticodon interface) the misincorporated amino acid will probably have similar properties to the intended tRNA molecule. Although the resultant protein will have one incorrect amino acid it stands a high probability of being functional. Organisms show "codon bias" and use certain codons for a particular amino acid more than others. For example, the codon usage in humans is different from that in bacteria; it can sometimes be difficult to express a human protein in bacteria because the relevant tRNA might be present at too low a concentration.
| First base (5'-end) | Middle base | Third Base ('3-end) | |||
|---|---|---|---|---|---|
| U | C | A | G | ||
| U | U | Phe | Phe | Leu | Leu |
| C | Ser | Ser | Ser | Ser | |
| A | Tyr | Tyr | |||
| G | Cys | Cys | Trp | ||
| C | U | Leu | Leu | Leu | Leu |
| C | Pro | Pro | Pro | Pro | |
| A | His | His | Gln | Gln | |
| G | Arg | Arg | Arg | Arg | |
| A | U | lle | lle | lle | |
| C | Thr | Thr | Thr | Thr | |
| A | Asn | Asn | Lys | Lys | |
| G | Ser | Ser | Arg | Arg | |
| G | U | Val | Val | Val | Val |
| C | Ala | Ala | Ala | Ala | |
| A | Asp | Asp | Glu | Glu | |
| G | Gly | Gly | Gly | Gly | |
One strand of genomic DNA (strand A, coding strand) contains the following sequence reading from 5' to 3':
TCGTCGACGATGATCATCGGCTACTCGA
This strand will form the duplex
5'-TCGTCGACGATGATCATCGGCTACTCGA-3' 3'-AGCAGCTGCTACTAGTAGCCGATGAGCT-5'
The sequence of bases in the other strand of DNA (strand B) written 5' to 3' is therefore
TCGAGTAGCCGATGATCATCGTCGACGA
In the mRNA transcribed from strand A of DNA, the sequence of bases written 5' to 3' is
UCGAGUAGCCGAUGAUCAUCGUCGACGA
resulting in an amino acid sequence
Ser-Ser-Ser-Arg-STOP
However, if DNA strand B is the coding strand the mRNA sequence will be
UCGUCGACGAUGAUCAUCGGCUACUCGA
and the amino-acid sequence will be
Ser-Ser-Thr-Met-Ile-Ile-Gly-Tyr-Ser-
Close inspection of all of the available codons for a particular amino acid reveals that the variation is greatest in the third position (for example, the codons for alanine are GCU, GCC, GCA and GCG). Crick and Brenner proposed that a single tRNA molecule can recognize codons with different bases at the 3'-end owing to non-Watson-Crick base pair formation with the third base in the codon-anticodon interaction. These non-standard base pairs are different in shape from A·U and G·C and the term wobble hypothesis indicates that a certain degree of flexibility or "wobbling" is allowed at this position in the ribosome. Not all combinations are possible; examples of "allowed" pairings are shown in Figure 11 .
The ability of DNA bases to form wobble base pairs as well as Watson-Crick base pairs can result in mismatches occurring during DNA replication. If not repaired by DNA repair enzymes, these mismatches can lead to genetic diseases and cancer.
This page has been archived and is no longer updated
Translation: DNA to mRNA to Protein
The genes in DNA encode protein molecules, which are the "workhorses" of the cell , carrying out all the functions necessary for life. For example, enzymes, including those that metabolize nutrients and synthesize new cellular constituents, as well as DNA polymerases and other enzymes that make copies of DNA during cell division , are all proteins.
In the simplest sense, expressing a gene means manufacturing its corresponding protein, and this multilayered process has two major steps. In the first step, the information in DNA is transferred to a messenger RNA ( mRNA ) molecule by way of a process called transcription . During transcription , the DNA of a gene serves as a template for complementary base-pairing , and an enzyme called RNA polymerase II catalyzes the formation of a pre-mRNA molecule, which is then processed to form mature mRNA (Figure 1). The resulting mRNA is a single-stranded copy of the gene, which next must be translated into a protein molecule.
Where Translation Occurs
Within all cells, the translation machinery resides within a specialized organelle called the ribosome . In eukaryotes, mature mRNA molecules must leave the nucleus and travel to the cytoplasm , where the ribosomes are located. On the other hand, in prokaryotic organisms, ribosomes can attach to mRNA while it is still being transcribed. In this situation, translation begins at the 5' end of the mRNA while the 3' end is still attached to DNA.
In all types of cells, the ribosome is composed of two subunits: the large (50S) subunit and the small (30S) subunit (S, for svedberg unit, is a measure of sedimentation velocity and, therefore, mass). Each subunit exists separately in the cytoplasm, but the two join together on the mRNA molecule. The ribosomal subunits contain proteins and specialized RNA molecules—specifically, ribosomal RNA ( rRNA ) and transfer RNA ( tRNA ) . The tRNA molecules are adaptor molecules—they have one end that can read the triplet code in the mRNA through complementary base-pairing, and another end that attaches to a specific amino acid (Chapeville et al. , 1962; Grunberger et al. , 1969). The idea that tRNA was an adaptor molecule was first proposed by Francis Crick, co-discoverer of DNA structure, who did much of the key work in deciphering the genetic code (Crick, 1958).
Within the ribosome, the mRNA and aminoacyl-tRNA complexes are held together closely, which facilitates base-pairing. The rRNA catalyzes the attachment of each new amino acid to the growing chain.
The Beginning of mRNA Is Not Translated
Interestingly, not all regions of an mRNA molecule correspond to particular amino acids. In particular, there is an area near the 5' end of the molecule that is known as the untranslated region (UTR) or leader sequence. This portion of mRNA is located between the first nucleotide that is transcribed and the start codon (AUG) of the coding region, and it does not affect the sequence of amino acids in a protein (Figure 3).
So, what is the purpose of the UTR? It turns out that the leader sequence is important because it contains a ribosome-binding site. In bacteria , this site is known as the Shine-Dalgarno box (AGGAGG), after scientists John Shine and Lynn Dalgarno, who first characterized it. A similar site in vertebrates was characterized by Marilyn Kozak and is thus known as the Kozak box. In bacterial mRNA, the 5' UTR is normally short; in human mRNA, the median length of the 5' UTR is about 170 nucleotides. If the leader is long, it may contain regulatory sequences, including binding sites for proteins, that can affect the stability of the mRNA or the efficiency of its translation.
Translation Begins After the Assembly of a Complex Structure
Table 1 shows the N-terminal sequences of proteins in prokaryotes and eukaryotes, based on a sample of 170 prokaryotic and 120 eukaryotic proteins (Flinta et al. , 1986). In the table, M represents methionine, A represents alanine, K represents lysine, S represents serine, and T represents threonine.
Table 1: N-Terminal Sequences of Proteins
* Methionine was removed in all of these proteins
** Methionine was not removed from any of these proteins
Once the initiation complex is formed on the mRNA, the large ribosomal subunit binds to this complex, which causes the release of IFs (initiation factors). The large subunit of the ribosome has three sites at which tRNA molecules can bind. The A (amino acid) site is the location at which the aminoacyl-tRNA anticodon base pairs up with the mRNA codon, ensuring that correct amino acid is added to the growing polypeptide chain. The P (polypeptide) site is the location at which the amino acid is transferred from its tRNA to the growing polypeptide chain. Finally, the E (exit) site is the location at which the "empty" tRNA sits before being released back into the cytoplasm to bind another amino acid and repeat the process. The initiator methionine tRNA is the only aminoacyl-tRNA that can bind in the P site of the ribosome, and the A site is aligned with the second mRNA codon. The ribosome is thus ready to bind the second aminoacyl-tRNA at the A site, which will be joined to the initiator methionine by the first peptide bond (Figure 5).
The Elongation Phase
Next, peptide bonds between the now-adjacent first and second amino acids are formed through a peptidyl transferase activity. For many years, it was thought that an enzyme catalyzed this step, but recent evidence indicates that the transferase activity is a catalytic function of rRNA (Pierce, 2000). After the peptide bond is formed, the ribosome shifts, or translocates, again, thus causing the tRNA to occupy the E site. The tRNA is then released to the cytoplasm to pick up another amino acid. In addition, the A site is now empty and ready to receive the tRNA for the next codon.
This process is repeated until all the codons in the mRNA have been read by tRNA molecules, and the amino acids attached to the tRNAs have been linked together in the growing polypeptide chain in the appropriate order. At this point, translation must be terminated, and the nascent protein must be released from the mRNA and ribosome.
Termination of Translation
There are three termination codons that are employed at the end of a protein-coding sequence in mRNA: UAA, UAG, and UGA. No tRNAs recognize these codons. Thus, in the place of these tRNAs, one of several proteins, called release factors, binds and facilitates release of the mRNA from the ribosome and subsequent dissociation of the ribosome.
Comparing Eukaryotic and Prokaryotic Translation
The translation process is very similar in prokaryotes and eukaryotes. Although different elongation, initiation, and termination factors are used, the genetic code is generally identical. As previously noted, in bacteria, transcription and translation take place simultaneously, and mRNAs are relatively short-lived. In eukaryotes, however, mRNAs have highly variable half-lives, are subject to modifications, and must exit the nucleus to be translated; these multiple steps offer additional opportunities to regulate levels of protein production, and thereby fine-tune gene expression.
References and Recommended Reading
Chapeville, F., et al. On the role of soluble ribonucleic acid in coding for amino acids. Proceedings of the National Academy of Sciences 48 , 1086–1092 (1962)
Crick, F. On protein synthesis. Symposia of the Society for Experimental Biology 12 , 138–163 (1958)
Flinta, C., et al . Sequence determinants of N-terminal protein processing. European Journal of Biochemistry 154 , 193–196 (1986)
Grunberger, D., et al . Codon recognition by enzymatically mischarged valine transfer ribonucleic acid. Science 166 , 1635–1637 (1969) doi:10.1126/science.166.3913.1635
Kozak, M. Point mutations close to the AUG initiator codon affect the efficiency of translation of rat preproinsulin in vivo . Nature 308 , 241–246 (1984) doi:10.1038308241a0 ( link to article )
---. Point mutations define a sequence flanking the AUG initiator codon that modulates translation by eukaryotic ribosomes. Cell 44 , 283–292 (1986)
---. An analysis of 5'-noncoding sequences from 699 vertebrate messenger RNAs. Nucleic Acids Research 15 , 8125–8148 (1987)
Pierce, B. A. Genetics: A conceptual approach (New York, Freeman, 2000)
Shine, J., & Dalgarno, L. Determinant of cistron specificity in bacterial ribosomes. Nature 254 , 34–38 (1975) doi:10.1038/254034a0 ( link to article )
- Add Content to Group
Article History
Flag inappropriate.


Email your Friend

- | Lead Editor: Bob Moss

Within this Subject (34)
- Applications in Biotechnology (4)
- Discovery of Genetic Material (4)
- DNA Replication (6)
- Gene Copies (5)
- Jumping Genes (4)
- RNA (7)
- Transcription & Translation (4)
Other Topic Rooms
- Gene Inheritance and Transmission
- Gene Expression and Regulation
- Nucleic Acid Structure and Function
- Chromosomes and Cytogenetics
- Evolutionary Genetics
- Population and Quantitative Genetics
- Genes and Disease
- Genetics and Society
- Cell Origins and Metabolism
- Proteins and Gene Expression
- Subcellular Compartments
- Cell Communication
- Cell Cycle and Cell Division
© 2014 Nature Education
- Press Room |
- Terms of Use |
- Privacy Notice |

Visual Browse
3.4 Protein Synthesis
Learning objectives.
Main Objective
- Explain the process by which a cell builds proteins using the DNA code
By the end of this section, you will be able to:
- Explain how the genetic code within DNA determines the proteins formed
- Describe the process of transcription
- Explain the process of translation
- Discuss the function of ribosomes
It was mentioned earlier that DNA provides a “blueprint” for the cell structure and physiology. This refers to the fact that DNA contains the information necessary for the cell to build one very important type of molecule: the protein. Most structural components of the cell are made up, at least in part, by proteins and virtually all the functions that a cell carries out are completed with the help of proteins. One of the most important classes of proteins is enzymes, which help speed up necessary biochemical reactions that take place inside the cell. Some of these critical biochemical reactions include building larger molecules from smaller components (such as what occurs during DNA replication or synthesis of microtubules) and breaking down larger molecules into smaller components (such as when harvesting chemical energy from nutrient molecules). Whatever the cellular process may be, it is almost sure to involve proteins. Just as the cell’s genome describes its full complement of DNA, a cell’s proteome is its full complement of proteins. Protein synthesis begins with genes. A gene is a functional segment of DNA that provides the genetic information necessary to build a protein. Each particular gene provides the code necessary to construct a particular protein. Gene expression , which transforms the information coded in a gene to a final gene product, ultimately dictates the structure and function of a cell by determining which proteins are made.
The interpretation of genes works in the following way. Recall that proteins are polymers, or chains, of many amino acid building blocks. The sequence of bases in a gene (that is, its sequence of A, T, C, G nucleotides) translates to an amino acid sequence. A triplet is a section of three DNA bases in a row that codes for a specific amino acid. For example, the DNA triplet CAC (cytosine, adenine, and cytosine) specifies the amino acid valine. Therefore, a gene, which is composed of multiple triplets in a unique sequence, provides the code to build an entire protein, with multiple amino acids in the proper sequence ( Figure 3.4.1 ). The mechanism by which cells turn the DNA code into a protein product is a two-step process, with an RNA molecule as the intermediate.

From DNA to RNA: Transcription
DNA is housed within the nucleus, and protein synthesis takes place in the cytoplasm, thus there must be some sort of intermediate messenger that leaves the nucleus and manages protein synthesis. This intermediate messenger is messenger RNA (mRNA) , (Figure 3.29), a single-stranded nucleic acid that carries a copy of the genetic code for a single gene out of the nucleus and into the cytoplasm where it is used to produce proteins.
There are several different types of RNA, each having different functions in the cell. The structure of RNA is similar to DNA with a few small exceptions. For one thing, unlike DNA, most types of RNA, including mRNA, are single-stranded and contain no complementary strand. Second, the ribose sugar in RNA contains an additional oxygen atom compared with DNA. Finally, instead of the base thymine, RNA contains the base uracil. This means that adenine will always pair up with uracil during the protein synthesis process.
Gene expression begins with the process called transcription , which is the synthesis of a strand of mRNA that is complementary to the gene of interest. This process is called transcription because the mRNA is like a transcript, or copy, of the gene’s DNA code. Transcription begins in a fashion somewhat like DNA replication, in that a region of DNA unwinds and the two strands separate, however, only that small portion of the DNA will be split apart. The triplets within the gene on this section of the DNA molecule are used as the template to transcribe the complementary strand of RNA ( Figure 3.4.2 ). A codon is a three-base sequence of mRNA, so-called because they directly encode amino acids. Like DNA replication, there are three stages to transcription: initiation, elongation, and termination.

In the first of the two stages of making protein from DNA, a gene on the DNA molecule is transcribed into a complementary mRNA molecule.
Stage 1: Initiation. A region at the beginning of the gene called a promoter—a particular sequence of nucleotides—triggers the start of transcription.
Stage 2: Elongation. Transcription starts when RNA polymerase unwinds the DNA segment. One strand, referred to as the coding strand, becomes the template with the genes to be coded. The polymerase then aligns the correct nucleic acid (A, C, G, or U) with its complementary base on the coding strand of DNA. RNA polymerase is an enzyme that adds new nucleotides to a growing strand of RNA. This process builds a strand of mRNA.
Stage 3: Termination. When the polymerase has reached the end of the gene, one of three specific triplets (UAA, UAG, or UGA) codes a “stop” signal, which triggers the enzymes to terminate transcription and release the mRNA transcript.
The transcription process is regulated by a class of proteins called transcription factors , which bind to the gene sequence and either promote or inhibit their transcription. (move Figure 3.35 here).
Before the mRNA molecule leaves the nucleus and proceeds to protein synthesis, it is modified in a number of ways. For this reason, it is often called a pre-mRNA at this stage. For example, your DNA, and thus complementary mRNA, contains long regions called non-coding regions that do not code for amino acids. Their function is still a mystery, but the process called splicing removes these non-coding regions from the pre-mRNA transcript ( Figure 3.4.3 ). A spliceosome —a structure composed of various proteins and other molecules—attaches to the mRNA and “splices” or cuts out the non-coding regions. The removed segment of the transcript is called an intron . The remaining exons are pasted together. An exon is a segment of RNA that remains after splicing. Interestingly, some introns that are removed from mRNA are not always non-coding. When different coding regions of mRNA are spliced out, different variations of the protein will eventually result, with differences in structure and function. This process results in a much larger variety of possible proteins and protein functions. When the mRNA transcript is ready, it travels out of the nucleus and into the cytoplasm.
External Website
This video will show you the important enzymes and biomolecules involved in the process of transcription, the process of making an mRNA molecule from DNA.

From RNA to Protein: Translation
Like translating a book from one language into another, the codons on a strand of mRNA must be translated into the amino acid alphabet of proteins. Translation is the process of synthesizing a chain of amino acids called a polypeptide. Translation requires two major aids: first, a “translator,” the molecule that will conduct the translation, and second, a substrate on which the mRNA strand is translated into a new protein, like the translator’s “desk.” Both of these requirements are fulfilled by other types of RNA. The substrate on which translation takes place is the ribosome.
Remember that many of a cell’s ribosomes are found associated with the rough ER, and carry out the synthesis of proteins destined for the Golgi apparatus. Ribosomal RNA (rRNA) is a type of RNA that, together with proteins, composes the structure of the ribosome. Ribosomes exist in the cytoplasm as two distinct components, a small and a large subunit. When an mRNA molecule is ready to be translated, the two subunits come together and attach to the mRNA. The ribosome provides a substrate for translation, bringing together and aligning the mRNA molecule with the molecular “translators” that must decipher its code.
The other major requirement for protein synthesis is the translator molecules that physically “read” the mRNA codons. Transfer RNA (tRNA) is a type of RNA that ferries the appropriate corresponding amino acids to the ribosome, and attaches each new amino acid to the last, building the polypeptide chain one-by-one. Thus tRNA transfers specific amino acids from the cytoplasm to a growing polypeptide. The tRNA molecules must be able to recognize the codons on mRNA and match them with the correct amino acid. The tRNA is modified for this function. On one end of its structure is a binding site for a specific amino acid. On the other end is a base sequence that matches the codon specifying its particular amino acid. This sequence of three bases on the tRNA molecule is called an anticodon . For example, a tRNA responsible for shuttling the amino acid glycine contains a binding site for glycine on one end. On the other end it contains an anticodon that complements the glycine codon (GGA is a codon for glycine, and so the tRNAs anticodon would read CCU). Equipped with its particular cargo and matching anticodon, a tRNA molecule can read its recognized mRNA codon and bring the corresponding amino acid to the growing chain ( Figure 3.4.4 ).

Much like the processes of DNA replication and transcription, translation consists of three main stages: initiation, elongation, and termination. Initiation takes place with the binding of a ribosome to an mRNA transcript. The elongation stage involves the recognition of a tRNA anticodon with the next mRNA codon in the sequence. Once the anticodon and codon sequences are bound (remember, they are complementary base pairs), the tRNA presents its amino acid cargo and the growing polypeptide strand is attached to this next amino acid. This attachment takes place with the assistance of various enzymes and requires energy. The tRNA molecule then releases the mRNA strand, the mRNA strand shifts one codon over in the ribosome, and the next appropriate tRNA arrives with its matching anticodon. This process continues until the final codon on the mRNA is reached which provides a “stop” message that signals termination of translation and triggers the release of the complete, newly synthesized protein. Thus, a gene within the DNA molecule is transcribed into mRNA, which is then translated into a protein product ( Figure 3.4.5 ).
This video will show you the important enzymes and biomolecules involved in the process of translation, which uses mRNA to code for a protein.

Commonly, an mRNA transcription will be translated simultaneously by several adjacent ribosomes. This increases the efficiency of protein synthesis. A single ribosome might translate an mRNA molecule in approximately one minute; so multiple ribosomes aboard a single transcript could produce multiple times the number of the same protein in the same minute. A polyribosome is a string of ribosomes translating a single mRNA strand.

Watch this video to learn about ribosomes. The ribosome binds to the mRNA molecule to start translation of its code into a protein. What happens to the small and large ribosomal subunits at the end of translation?
Chapter Review
DNA stores the information necessary for instructing the cell to perform all of its functions. Cells use the genetic code stored within DNA to build proteins, which ultimately determines the structure and function of the cell. This genetic code lies in the particular sequence of nucleotides that make up each gene along the DNA molecule. To “read” this code, the cell must perform two sequential steps. In the first step, transcription, the DNA code is converted into a RNA code. A molecule of messenger RNA that is complementary to a specific gene is synthesized in a process similar to DNA replication. The molecule of mRNA provides the code to synthesize a protein. In the process of translation, the mRNA attaches to a ribosome. Next, tRNA molecules shuttle the appropriate amino acids to the ribosome, one-by-one, coded by sequential triplet codons on the mRNA, until the protein is fully synthesized. When completed, the mRNA detaches from the ribosome, and the protein is released. Typically, multiple ribosomes attach to a single mRNA molecule at once such that multiple proteins can be manufactured from the mRNA concurrently.
Review Questions
Critical thinking questions.
Briefly explain the similarities between transcription and DNA replication.
Transcription and DNA replication both involve the synthesis of nucleic acids. These processes share many common features—particularly, the similar processes of initiation, elongation, and termination. In both cases the DNA molecule must be untwisted and separated, and the coding (i.e., sense) strand will be used as a template. Also, polymerases serve to add nucleotides to the growing DNA or mRNA strand. Both processes are signaled to terminate when completed.
Contrast transcription and translation. Name at least three differences between the two processes.
Transcription is really a “copy” process and translation is really an “interpretation” process, because transcription involves copying the DNA message into a very similar RNA message whereas translation involves converting the RNA message into the very different amino acid message. The two processes also differ in their location: transcription occurs in the nucleus and translation in the cytoplasm. The mechanisms by which the two processes are performed are also completely different: transcription utilizes polymerase enzymes to build mRNA whereas translation utilizes different kinds of RNA to build protein.
This work, Anatomy & Physiology, is adapted from Anatomy & Physiology by OpenStax , licensed under CC BY . This edition, with revised content and artwork, is licensed under CC BY-SA except where otherwise noted.
Images, from Anatomy & Physiology by OpenStax , are licensed under CC BY except where otherwise noted.
Access the original for free at https://openstax.org/books/anatomy-and-physiology/pages/1-introduction .
Anatomy & Physiology Copyright © 2019 by Lindsay M. Biga, Staci Bronson, Sierra Dawson, Amy Harwell, Robin Hopkins, Joel Kaufmann, Mike LeMaster, Philip Matern, Katie Morrison-Graham, Kristen Oja, Devon Quick, Jon Runyeon, OSU OERU, and OpenStax is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License , except where otherwise noted.
- History & Society
- Science & Tech
- Biographies
- Animals & Nature
- Geography & Travel
- Arts & Culture
- Games & Quizzes
- On This Day
- One Good Fact
- New Articles
- Lifestyles & Social Issues
- Philosophy & Religion
- Politics, Law & Government
- World History
- Health & Medicine
- Browse Biographies
- Birds, Reptiles & Other Vertebrates
- Bugs, Mollusks & Other Invertebrates
- Environment
- Fossils & Geologic Time
- Entertainment & Pop Culture
- Sports & Recreation
- Visual Arts
- Demystified
- Image Galleries
- Infographics
- Top Questions
- Britannica Kids
- Saving Earth
- Space Next 50
- Student Center

transcription
Our editors will review what you’ve submitted and determine whether to revise the article.
- TeachMePhysiology - Transcription of DNA
- BCcampus Open Publishing - Transcription
- Pressbooks at Virginia Tech - Cell Biology, Genetics, and Biochemistry for Pre-Clinical Students - Transcription and Translation
- University of Minnesota Pressbooks - Transcription
- Projects at Harvard - Transcription
- Iowa State University Digital Press - Gene Expression: Transcription
- Biology LibreTexts - Overview of Transcription
- National Center for Biotechnology Information - PubMed Central - Transcription: the epicenter of gene expression
transcription , the synthesis of RNA from DNA . Genetic information flows from DNA into protein , the substance that gives an organism its form. This flow of information occurs through the sequential processes of transcription (DNA to RNA) and translation (RNA to protein). Transcription occurs when there is a need for a particular gene product at a specific time or in a specific tissue.
During transcription, only one strand of DNA is usually copied. This is called the template strand, and the RNA molecules produced are single-stranded messenger RNAs (mRNAs). The DNA strand that would correspond to the mRNA is called the coding or sense strand. In eukaryotes (organisms that possess a nucleus ) the initial product of transcription is called a pre-mRNA. Pre-mRNA is extensively edited through splicing before the mature mRNA is produced and ready for translation by the ribosome , the cellular organelle that serves as the site of protein synthesis. Transcription of any one gene takes place at the chromosomal location of that gene, which is a relatively short segment of the chromosome . The active transcription of a gene depends on the need for the activity of that particular gene in a specific cell or tissue or at a given time.

Small segments of DNA are transcribed into RNA by the enzyme RNA polymerase , which achieves this copying in a strictly controlled process. The first step is to recognize a specific sequence on DNA called a promoter that signifies the start of the gene. The two strands of DNA become separated at this point, and RNA polymerase begins copying from a specific point on one strand of the DNA using a special type of sugar -containing nucleoside called ribonucleoside 5’-triphosphate to begin the growing chain. Additional ribonucleoside triphosphates are used as the substrate, and, by cleavage of their high-energy phosphate bond, ribonucleoside monophosphates are incorporated into the growing RNA chain. Each successive ribonucleotide is directed by the complementary base pairing rules of DNA. For example, a C ( cytosine ) in DNA directs the incorporation of a G ( guanine ) into RNA. Likewise, a G in DNA is copied into a C in RNA, a T ( thymine ) into an A ( adenine ), and an A into a U ( uracil ; RNA contains U in place of the T of DNA). Synthesis continues until a termination signal is reached, at which point the RNA polymerase drops off the DNA, and the RNA molecule is released.

Ahead of many genes in prokaryotes (organisms that lack a nucleus), there are signals called “operators” ( see operons ) where specialized proteins called repressors bind to the DNA just upstream of the start point of transcription and prevent access to the DNA by RNA polymerase. These repressor proteins thus prevent transcription of the gene by physically blocking the action of the RNA polymerase. Typically, repressors are released from their blocking action when they receive signals from other molecules in the cell indicating that the gene needs to be expressed. Ahead of some prokaryotic genes are signals to which activator proteins bind to stimulate transcription.
Transcription in eukaryotes is more complicated than in prokaryotes. First, the RNA polymerase of higher organisms is a more complicated enzyme than the relatively simple five-subunit enzyme of prokaryotes. In addition, there are many more accessory factors that help to control the efficiency of the individual promoters. These accessory proteins are called transcription factors and typically respond to signals from within the cell that indicate whether transcription is required. In many human genes, several transcription factors may be needed before transcription can proceed efficiently. A transcription factor can cause either repression or activation of gene expression in eukaryotes.
Warning: The NCBI web site requires JavaScript to function. more...

An official website of the United States government
The .gov means it's official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you're on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
- Browse Titles
NCBI Bookshelf. A service of the National Library of Medicine, National Institutes of Health.
Cooper GM. The Cell: A Molecular Approach. 2nd edition. Sunderland (MA): Sinauer Associates; 2000.
By agreement with the publisher, this book is accessible by the search feature, but cannot be browsed.

The Cell: A Molecular Approach. 2nd edition.
Chapter 7 protein synthesis, processing, and regulation.
Transcription and RNA processing are followed by translation, the synthesis of proteins as directed by mRNA templates. Proteins are the active players in most cell processes, implementing the myriad tasks that are directed by the information encoded in genomic DNA. Protein synthesis is thus the final stage of gene expression. However, the translation of mRNA is only the first step in the formation of a functional protein. The polypeptide chain must then fold into the appropriate three-dimensional conformation and, frequently, undergo various processing steps before being converted to its active form. These processing steps, particularly in eukaryotes, are intimately related to the sorting and transport of different proteins to their appropriate destinations within the cell.
Although the expression of most genes is regulated primarily at the level of transcription (see Chapter 6), gene expression can also be controlled at the level of translation, and this control is an important element of gene regulation in both prokaryotic and eukaryotic cells. Of even broader significance, however, are the mechanisms that control the activities of proteins within cells. Once synthesized, most proteins can be regulated in response to extracellular signals by either covalent modifications or by association with other molecules. In addition, the levels of proteins within cells can be controlled by differential rates of protein degradation. These multiple controls of both the amounts and activities of intracellular proteins ultimately regulate all aspects of cell behavior.
- Translation of mRNA
- Protein Folding and Processing
- Regulation of Protein Function
- Protein Degradation
- References and Further Reading
- Cite this Page Cooper GM. The Cell: A Molecular Approach. 2nd edition. Sunderland (MA): Sinauer Associates; 2000. Chapter 7, Protein Synthesis, Processing, and Regulation.
Related Items in Bookshelf
- All Textbooks
Recent Activity
- Protein Synthesis, Processing, and Regulation - The Cell Protein Synthesis, Processing, and Regulation - The Cell
Your browsing activity is empty.
Activity recording is turned off.
Turn recording back on
Connect with NLM
National Library of Medicine 8600 Rockville Pike Bethesda, MD 20894
Web Policies FOIA HHS Vulnerability Disclosure
Help Accessibility Careers

Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.
16 Protein Synthesis Overview
Andrea Bierema
Learning Objectives
Students will be able to:
- Describe the structure and purpose of DNA and RNA.
- Describe the general process of protein synthesis.
- Describe the molecular anatomy of genes and genomes.
- Identify DNA and mRNA bases and binding patterns.
- Interpret a codon-amino acid chart.
- Given a DNA sequence, determine the corresponding mRNA sequence and amino acid sequence.
Central Dogma
The central dogma of molecular biology is that DNA codes for RNA and RNA codes for protein. In addition to DNA coding for RNA, much of the DNA regulates the synthesis of RNA- which ultimately means that it regulates the synthesis of protein. We will learn about protein synthesis regulation in a later chapter.

Protein synthesis consists of two main processes: transcription and translation. During the process of transcription —which occurs in the nucleus—an mRNA molecule is created by reading the DNA. Note that DNA never “becomes” RNA; rather, the DNA is “read” to make an RNA molecule. The mRNA leaves the nucleus and then, through the process of translation , the mRNA is read to create an amino acid sequence which folds into a protein.
Consider what the terms “transcribe” and “translate” mean in relation to language. To “transcribe” something means to rewrite text again in the same language while to “translate” something means to rewrite the text in a different language. Similar to these meanings, in biology, DNA is transcribed into RNA: both DNA and RNA are made of nucleic acid (i.e., the same “language”). With the assistance of proteins, DNA is “read” and transcribed into an mRNA sequence. To read RNA and create protein, though, we refer to it as being translated: RNA is made of nucleic acid and protein is made of amino acid (i.e., different “languages”). Therefore, DNA is transcribed to create an mRNA sequence, and then the mRNA sequence is translated to make a protein.
DNA and RNA
The two main types of nucleic acids are deoxyribonucleic acid (DNA) and ribonucleic acid (RNA) . DNA is the genetic material in all living organisms, ranging from single-celled bacteria to multicellular mammals. It is in the nucleus of eukaryotes and in the organelles, chloroplasts, and mitochondria. In prokaryotes, the DNA is not enclosed in a membranous envelope.
The cell’s entire genetic content is its genome, and the study of genomes is genomics. In eukaryotic cells but not in prokaryotes, a DNA molecule may contain tens of thousands of genes. Many genes contain information to make protein products (e.g., mRNA). Other genes code for RNA products. DNA controls all of the cellular activities by turning the genes “on” or “off.”
The other type of nucleic acid, RNA, is mostly involved in protein synthesis. The DNA molecules never leave the nucleus but instead use an intermediary to communicate with the rest of the cell. This intermediary is the messenger RNA (mRNA) . Other types of RNA—like rRNA, tRNA, and microRNA—are involved in protein synthesis and its regulation.
DNA and RNA are comprised of monomers that scientists call nucleotides . The nucleotides combine with each other to form a polynucleotide , DNA or RNA. Three components comprise each nucleotide: a nitrogenous base, a pentose (five-carbon) sugar, and a phosphate group. Each nitrogenous base in a nucleotide is attached to a sugar molecule, which is attached to one or more phosphate groups. Therefore, although the terms “base” and “nucleotide” are sometimes used interchangeably, a nucleotide contains a base as well as part of the sugar-phosphate backbone.

Comparison of RNA (left molecule) and DNA (right molecule). The color of the bases in RNA and DNA aligns with the colored boxes next to each base molecule.
Examine the image above and then answer the following questions:
What is a Gene?
The gene is the basic physical unit of inheritance. Genes are passed from parents to offspring and contain the information needed to specify traits. Genes are arranged, one after another, on structures called chromosomes. A chromosome contains a single, long DNA molecule, only a portion of which corresponds to a single gene. Humans have approximately 20,000 genes arranged on their chromosomes. Watch the following video for an animated view on the relationship between chromosomes and genes.
Protein Synthesis Overview
The two main processes in protein synthesis are transcription and translation. The following is an overview of each of these processes. Each process will be described in more detail in future chapters.
Transcription
A gene is complex: it contains not only the code for the resulting protein but also several regulatory factors that determine if and when the region that codes for a protein are read to create protein. What follows is a diagram of the components of a gene that are used in transcription.
For this chapter, we focus on the DNA and the ending product of transcription: mRNA.
Given a specific DNA strand, what is the sequence of the resulting mRNA molecule? We will learn about how mRNA is created in a later chapter.
Translation
Translation involves different types of RNA, and we will explain them in more detail in a later chapter: rRNA, tRNA, mRNA, and microRNA.
After an mRNA is created, it leaves the nucleus and is attracted to or attracts a ribosome, which is a molecule made of rRNA and polypeptides. Then, in the ribosome, and with the assistance of tRNAs, the mRNA is read and an amino acid sequence is created.
DNA and mRNA create sequences with just four types of bases; yet, these bases code for 20 unique amino acids (the makeup of protein). How is this possible? Watch the following video to find out!
The mRNA is read in sets of three bases known as codons. Each codon codes for a single amino acid. In this way, the mRNA is read and the protein product is made.
Below is a chart showing which codons code for which bases. There are two representations; move to the next slide for the second representation.
These charts can be a little confusing at first. Watch the following video to learn how to interpret both chart formats.
This chapter focused on DNA, mRNA, and protein sequences. The next several chapters describe the processes that take place during protein synthesis. Master how sequences are read during protein synthesis (the focus of the current chapter) before moving on to the next chapter. Below are some sources to help further your understanding!
Check out Learn.Genetics’ “How a Firefly’s Tail Makes Light” video for an overview of protein synthesis!
Need a little more practice?
Try out Learn.Genetics’ “Transcribe and Translate a Gene” and The Concord Consortium’s “ DNA to Protein ” interactives for further practice!
Attributions
This chapter is a modified derivative of the following articles:
“ Gene ” by National Human Genome Research Institute, National Institutes of Health, Talking Glossary of Genetic Terms.
“Nucleic Acids” by OpenStax College, Biology 2e , CC BY 4.0. Download the original article at https://openstax.org/books/biology-2e/pages/3-5-nucleic-acids
Media Attributions
- Central Dogma © Andrea Bierema
- DNA and RNA © Sponk is licensed under a CC BY-SA (Attribution ShareAlike) license
An Interactive Introduction to Organismal and Molecular Biology Copyright © 2021 by Andrea Bierema is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License , except where otherwise noted.
Share This Book
11.4 Protein Synthesis (Translation)
Learning objectives.
By the end of this section, you will be able to:
- Describe the genetic code and explain why it is considered almost universal
- Explain the process of translation and the functions of the molecular machinery of translation
- Compare translation in eukaryotes and prokaryotes
The synthesis of proteins consumes more of a cell’s energy than any other metabolic process. In turn, proteins account for more mass than any other macromolecule of living organisms. They perform virtually every function of a cell, serving as both functional (e.g., enzymes) and structural elements. The process of translation , or protein synthesis , the second part of gene expression, involves the decoding by a ribosome of an mRNA message into a polypeptide product.
The Genetic Code
Translation of the mRNA template converts nucleotide-based genetic information into the “language” of amino acids to create a protein product. A protein sequence consists of 20 commonly occurring amino acids . Each amino acid is defined within the mRNA by a triplet of nucleotides called a codon . The relationship between an mRNA codon and its corresponding amino acid is called the genetic code .
The three-nucleotide code means that there is a total of 64 possible combinations (4 3 , with four different nucleotides possible at each of the three different positions within the codon). This number is greater than the number of amino acids and a given amino acid is encoded by more than one codon ( Figure 11.12 ). This redundancy in the genetic code is called degeneracy . Typically, whereas the first two positions in a codon are important for determining which amino acid will be incorporated into a growing polypeptide, the third position, called the wobble position , is less critical. In some cases, if the nucleotide in the third position is changed, the same amino acid is still incorporated.
Whereas 61 of the 64 possible triplets code for amino acids, three of the 64 codons do not code for an amino acid; they terminate protein synthesis, releasing the polypeptide from the translation machinery. These are called stop codon s or nonsense codon s . Another codon, AUG, also has a special function. In addition to specifying the amino acid methionine, it also typically serves as the start codon to initiate translation. The reading frame , the way nucleotides in mRNA are grouped into codons, for translation is set by the AUG start codon near the 5’ end of the mRNA. Each set of three nucleotides following this start codon is a codon in the mRNA message.
The genetic code is nearly universal. With a few exceptions, virtually all species use the same genetic code for protein synthesis, which is powerful evidence that all extant life on earth shares a common origin. However, unusual amino acids such as selenocysteine and pyrrolysine have been observed in archaea and bacteria. In the case of selenocysteine, the codon used is UGA (normally a stop codon). However, UGA can encode for selenocysteine using a stem-loop structure (known as the selenocysteine insertion sequence, or SECIS element), which is found at the 3’ untranslated region of the mRNA. Pyrrolysine uses a different stop codon, UAG. The incorporation of pyrrolysine requires the pylS gene and a unique transfer RNA (tRNA) with a CUA anticodon.
Check Your Understanding
- How many bases are in each codon?
- What amino acid is coded for by the codon AAU?
- What happens when a stop codon is reached?
The Protein Synthesis Machinery
In addition to the mRNA template, many molecules and macromolecules contribute to the process of translation . The composition of each component varies across taxa; for instance, ribosomes may consist of different numbers of ribosomal RNAs (rRNAs) and polypeptides depending on the organism. However, the general structures and functions of the protein synthesis machinery are comparable from bacteria to human cells. Translation requires the input of an mRNA template, ribosomes, tRNAs, and various enzymatic factors.
A ribosome is a complex macromolecule composed of catalytic rRNAs (called ribozyme s) and structural rRNA s, as well as many distinct polypeptides. Mature rRNAs make up approximately 50% of each ribosome. Prokaryotes have 70S ribosomes, whereas eukaryotes have 80S ribosomes in the cytoplasm and rough endoplasmic reticulum, and 70S ribosomes in mitochondria and chloroplasts . Ribosomes dissociate into large and small subunits when they are not synthesizing proteins and reassociate during the initiation of translation . In E. coli , the small subunit is described as 30S (which contains the 16S rRNA subunit), and the large subunit is 50S (which contains the 5S and 23S rRNA subunits), for a total of 70S (Svedberg units are not additive). Eukaryote ribosomes have a small 40S subunit (which contains the 18S rRNA subunit) and a large 60S subunit (which contains the 5S, 5.8S and 28S rRNA subunits), for a total of 80S. The small subunit is responsible for binding the mRNA template, whereas the large subunit binds tRNAs (discussed in the next subsection).
Each mRNA molecule is simultaneously translated by many ribosomes, all synthesizing protein in the same direction: reading the mRNA from 5’ to 3’ and synthesizing the polypeptide from the N terminus to the C terminus. The complete structure containing an mRNA with multiple associated ribosomes is called a polyribosome (or polysome ). In both bacteria and archaea , before transcriptional termination occurs, each protein-encoding transcript is already being used to begin synthesis of numerous copies of the encoded polypeptide(s) because the processes of transcription and translation can occur concurrently, forming polyribosomes ( Figure 11.13 ). The reason why transcription and translation can occur simultaneously is because both of these processes occur in the same 5’ to 3’ direction, they both occur in the cytoplasm of the cell, and because the RNA transcript is not processed once it is transcribed. This allows a prokaryotic cell to respond to an environmental signal requiring new proteins very quickly. In contrast, in eukaryotic cells, simultaneous transcription and translation is not possible. Although polyribosomes also form in eukaryotes, they cannot do so until RNA synthesis is complete and the RNA molecule has been modified and transported out of the nucleus.
Transfer RNAs
Transfer RNAs (tRNAs) are structural RNA molecules and, depending on the species, many different types of tRNAs exist in the cytoplasm. Bacterial species typically have between 60 and 90 types. Serving as adaptors, each tRNA type binds to a specific codon on the mRNA template and adds the corresponding amino acid to the polypeptide chain. Therefore, tRNAs are the molecules that actually “translate” the language of RNA into the language of proteins. As the adaptor molecules of translation, it is surprising that tRNAs can fit so much specificity into such a small package. The tRNA molecule interacts with three factors: aminoacyl tRNA synthetases, ribosomes, and mRNA.
Mature tRNAs take on a three-dimensional structure when complementary bases exposed in the single-stranded RNA molecule hydrogen bond with each other ( Figure 11.14 ). This shape positions the amino-acid binding site, called the CCA amino acid binding end , which is a cytosine-cytosine-adenine sequence at the 3’ end of the tRNA, and the anticodon at the other end. The anticodon is a three-nucleotide sequence that bonds with an mRNA codon through complementary base pairing.
An amino acid is added to the end of a tRNA molecule through the process of tRNA “charging,” during which each tRNA molecule is linked to its correct or cognate amino acid by a group of enzymes called aminoacyl tRNA synthetase s. At least one type of aminoacyl tRNA synthetase exists for each of the 20 amino acids. During this process, the amino acid is first activated by the addition of adenosine monophosphate (AMP) and then transferred to the tRNA, making it a charged tRNA , and AMP is released.
- Describe the structure and composition of the prokaryotic ribosome.
- In what direction is the mRNA template read?
- Describe the structure and function of a tRNA.
The Mechanism of Protein Synthesis
Translation is similar in prokaryotes and eukaryotes. Here we will explore how translation occurs in E. coli , a representative prokaryote, and specify any differences between bacterial and eukaryotic translation.
The initiation of protein synthesis begins with the formation of an initiation complex. In E. coli , this complex involves the small 30S ribosome, the mRNA template, three initiation factors that help the ribosome assemble correctly, guanosine triphosphate (GTP) that acts as an energy source, and a special initiator tRNA carrying N -formyl-methionine (fMet-tRNA fMet ) ( Figure 11.15 ). The initiator tRNA interacts with the start codon AUG of the mRNA and carries a formylated methionine (fMet). Because of its involvement in initiation, fMet is inserted at the beginning (N terminus) of every polypeptide chain synthesized by E. coli . In E. coli mRNA, a leader sequence upstream of the first AUG codon, called the Shine-Dalgarno sequence (also known as the ribosomal binding site AGGAGG), interacts through complementary base pairing with the rRNA molecules that compose the ribosome. This interaction anchors the 30S ribosomal subunit at the correct location on the mRNA template. At this point, the 50S ribosomal subunit then binds to the initiation complex, forming an intact ribosome.
In eukaryotes, initiation complex formation is similar, with the following differences:
- The initiator tRNA is a different specialized tRNA carrying methionine, called Met-tRNAi
- Instead of binding to the mRNA at the Shine-Dalgarno sequence, the eukaryotic initiation complex recognizes the 5’ cap of the eukaryotic mRNA, then tracks along the mRNA in the 5’ to 3’ direction until the AUG start codon is recognized. At this point, the 60S subunit binds to the complex of Met-tRNAi, mRNA, and the 40S subunit.
In prokaryotes and eukaryotes, the basics of elongation of translation are the same. In E. coli , the binding of the 50S ribosomal subunit to produce the intact ribosome forms three functionally important ribosomal sites: The A (aminoacyl) site binds incoming charged aminoacyl tRNAs. The P (peptidyl) site binds charged tRNAs carrying amino acids that have formed peptide bonds with the growing polypeptide chain but have not yet dissociated from their corresponding tRNA. The E (exit) site releases dissociated tRNAs so that they can be recharged with free amino acids. There is one notable exception to this assembly line of tRNAs: During initiation complex formation, bacterial fMet−tRNA fMet or eukaryotic Met-tRNAi enters the P site directly without first entering the A site, providing a free A site ready to accept the tRNA corresponding to the first codon after the AUG.
Elongation proceeds with single-codon movements of the ribosome each called a translocation event. During each translocation event, the charged tRNAs enter at the A site, then shift to the P site, and then finally to the E site for removal. Ribosomal movements, or steps, are induced by conformational changes that advance the ribosome by three bases in the 3’ direction. Peptide bonds form between the amino group of the amino acid attached to the A-site tRNA and the carboxyl group of the amino acid attached to the P-site tRNA. The formation of each peptide bond is catalyzed by peptidyl transferase , an RNA-based ribozyme that is integrated into the 50S ribosomal subunit. The amino acid bound to the P-site tRNA is also linked to the growing polypeptide chain. As the ribosome steps across the mRNA, the former P-site tRNA enters the E site, detaches from the amino acid, and is expelled. Several of the steps during elongation, including binding of a charged aminoacyl tRNA to the A site and translocation, require energy derived from GTP hydrolysis, which is catalyzed by specific elongation factors. Amazingly, the E. coli translation apparatus takes only 0.05 seconds to add each amino acid, meaning that a 200 amino-acid protein can be translated in just 10 seconds.
Termination
The termination of translation occurs when a nonsense codon (UAA, UAG, or UGA) is encountered for which there is no complementary tRNA. On aligning with the A site, these nonsense codons are recognized by release factors in prokaryotes and eukaryotes that result in the P-site amino acid detaching from its tRNA, releasing the newly made polypeptide. The small and large ribosomal subunits dissociate from the mRNA and from each other; they are recruited almost immediately into another translation initiation complex.
In summary, there are several key features that distinguish prokaryotic gene expression from that seen in eukaryotes. These are illustrated in Figure 11.16 and listed in Figure 11.17 .
Protein Targeting, Folding, and Modification
During and after translation, polypeptides may need to be modified before they are biologically active. Post-translational modifications include:
- removal of translated signal sequences—short tails of amino acids that aid in directing a protein to a specific cellular compartment
- proper “folding” of the polypeptide and association of multiple polypeptide subunits, often facilitated by chaperone proteins, into a distinct three-dimensional structure
- proteolytic processing of an inactive polypeptide to release an active protein component, and
- various chemical modifications (e.g., phosphorylation, methylation, or glycosylation) of individual amino acids.
- What are the components of the initiation complex for translation in prokaryotes?
- What are two differences between initiation of prokaryotic and eukaryotic translation?
- What occurs at each of the three active sites of the ribosome?
- What causes termination of translation?
This book may not be used in the training of large language models or otherwise be ingested into large language models or generative AI offerings without OpenStax's permission.
Want to cite, share, or modify this book? This book uses the Creative Commons Attribution License and you must attribute OpenStax.
Access for free at https://openstax.org/books/microbiology/pages/1-introduction
- Authors: Nina Parker, Mark Schneegurt, Anh-Hue Thi Tu, Philip Lister, Brian M. Forster
- Publisher/website: OpenStax
- Book title: Microbiology
- Publication date: Nov 1, 2016
- Location: Houston, Texas
- Book URL: https://openstax.org/books/microbiology/pages/1-introduction
- Section URL: https://openstax.org/books/microbiology/pages/11-4-protein-synthesis-translation
© Jul 18, 2024 OpenStax. Textbook content produced by OpenStax is licensed under a Creative Commons Attribution License . The OpenStax name, OpenStax logo, OpenStax book covers, OpenStax CNX name, and OpenStax CNX logo are not subject to the Creative Commons license and may not be reproduced without the prior and express written consent of Rice University.
What Is Transcription: Understanding the Biological Process
Transcription is the process of converting DNA to RNA in the cell nucleus. This biological process involves RNA polymerase reading the DNA template strand in a 3' to 5' direction , synthesizing complementary RNA in a 5' to 3' direction . Transcription is essential for gene expression and protein production. Understanding what transcription is helps explain how genetic information is transferred from DNA to RNA within cells.
Key aspects of transcription
DNA to RNA conversion : Transcription in biology converts the genetic information in DNA to RNA, specifically messenger RNA (mRNA)
Location : What is transcription? It's a process that occurs in the nucleus of eukaryotic cells
Enzyme involved : RNA polymerase is the primary enzyme responsible for transcription, a key component of the transcription definition
Direction : In transcription, RNA is synthesized in a 5' to 3' direction , while the DNA template is read in a 3' to 5' direction
Types of RNA produced : What is transcription's output? It produces various types of RNA, including mRNA , rRNA , and tRNA
Transcription process
Promoter recognition : In transcription, RNA polymerase, along with transcription factors, recognizes and binds to the promoter region of the gene
Complex formation : The transcription definition in eukaryotes includes a pre-initiation complex (PIC) forming at the promoter, involving various factors like TBP and TAFs
DNA melting : During transcription in biology, the DNA double helix is unwound and separated into single strands at the transcription start site
Nucleotide addition : What is transcription's main action? RNA polymerase adds complementary ribonucleotides to the growing RNA chain
Rate of synthesis : Transcription progresses at a rate of about 50 nucleotides per second in prokaryotes
Proofreading : In transcription, RNA polymerase has some ability to correct errors, though less efficient than DNA polymerase
Termination
Signal recognition : What is transcription's end signal? RNA polymerase recognizes specific termination signals in the DNA sequence
RNA release : In the final step of transcription, the newly synthesized RNA molecule is released from the template DNA strand
Regulation of transcription
Transcription factors : The transcription definition includes proteins that bind to specific DNA sequences to control gene expression
Chromatin structure : In transcription biology, the organization of DNA and proteins affects gene accessibility
Post-transcriptional modifications : What is transcription followed by? RNA can undergo various modifications after transcription, affecting its stability and function
Differences between prokaryotic and eukaryotic transcription
Enzyme complexity : What is transcription like in eukaryotes? They have three different RNA polymerases (I, II, III), while prokaryotes have only one
Transcription factors : The transcription definition for eukaryotes includes more complex transcription factor assemblies compared to prokaryotes
Coupling with translation : In prokaryotic transcription, transcription and translation can occur simultaneously, while in eukaryotes, they are separated by the nuclear membrane
What is transcription in biology?
Transcription in biology is the process of converting DNA to RNA in the cell nucleus. It involves RNA polymerase reading the DNA template strand and synthesizing complementary RNA. This process is essential for gene expression and protein production.
What is the basic transcription definition?
The basic transcription definition is the conversion of genetic information from DNA to RNA. Specifically, it's the synthesis of RNA using DNA as a template, carried out by the enzyme RNA polymerase in the nucleus of eukaryotic cells.
What are the key steps in transcription?
The key steps in transcription are initiation, elongation, and termination. Initiation involves RNA polymerase binding to the promoter region. Elongation is the process of adding complementary ribonucleotides to the growing RNA chain. Termination occurs when the RNA polymerase recognizes specific signals and releases the newly synthesized RNA.
How does transcription differ between prokaryotes and eukaryotes?
In prokaryotes, transcription uses a single RNA polymerase and can occur simultaneously with translation. Eukaryotes have three different RNA polymerases, more complex transcription factor assemblies, and transcription is separated from translation by the nuclear membrane.
What is the role of transcription factors in transcription?
Transcription factors are proteins that bind to specific DNA sequences to control gene expression. They play a crucial role in regulating transcription by either promoting or inhibiting the recruitment of RNA polymerase to specific genes, thus influencing which genes are transcribed and when.
How Many ATP Molecules Are Produced During Glycolysis
What Is RF Channel: Understanding Radio Frequency Channels
What Is a Syllable
What Does ATP Stand For?
What Is Human Trafficking
What Is Urea: Definition, Functions, and Applications
What Is Foot Content: Understanding Foot Fetish Media
Was this article helpful?
- Search Menu
- Sign in through your institution
- Chemical Biology and Nucleic Acid Chemistry
- Computational Biology
- Critical Reviews and Perspectives
- Data Resources and Analyses
- Gene Regulation, Chromatin and Epigenetics
- Genome Integrity, Repair and Replication
- Molecular and Structural Biology
- Nucleic Acid Enzymes
- RNA and RNA-protein complexes
- Synthetic Biology and Bioengineering
- Advance Articles
- Breakthrough Articles
- Molecular Biology Database Collection
- Special Collections
- Scope and Criteria for Consideration
- Author Guidelines
- Data Deposition Policy
- Database Issue Guidelines
- Web Server Issue Guidelines
- Submission Site
- Open Access Charges
- About Nucleic Acids Research
- Editors & Editorial Board
- Information of Referees
- Self-Archiving Policy
- Dispatch Dates
- Advertising and Corporate Services
- Journals Career Network
- Journals on Oxford Academic
- Books on Oxford Academic
Article Contents
Lay summary, introduction, materials and methods, data availability, supplementary data, acknowledgements, enl reads histone β-hydroxybutyrylation to modulate gene transcription.
The first four authors should be regarded as Joint First Authors.
- Article contents
- Figures & tables
- Supplementary Data
Chen Chen, Cong Chen, Aiyuan Wang, Zixin Jiang, Fei Zhao, Yanan Li, Yue Han, Ziping Niu, Shanshan Tian, Xue Bai, Kai Zhang, Guijin Zhai, ENL reads histone β-hydroxybutyrylation to modulate gene transcription, Nucleic Acids Research , Volume 52, Issue 17, 23 September 2024, Pages 10029–10039, https://doi.org/10.1093/nar/gkae504
- Permissions Icon Permissions
Histone modifications are typically recognized by chromatin-binding protein modules (referred to as ‘readers’) to mediate fundamental processes such as transcription. Lysine β-hydroxybutyrylation (Kbhb) is a new type of histone mark that couples metabolism to gene expression. However, the readers that prefer histone Kbhb remain elusive. This knowledge gap should be filled in order to reveal the molecular mechanism of this epigenetic regulation. Herein, we developed a chemical proteomic approach, relying upon multivalent photoaffinity probes to capture binders of the mark, and identified ENL as a novel target of H3K9bhb. Biochemical studies and CUT&Tag analysis further suggested that ENL favorably binds to H3K9bhb, and co-localizes with it on promoter regions to modulate gene expression. Notably, disrupting the interaction between H3K9bhb and ENL via structure-based mutation led to the suppressed expression of genes such MYC that drive cell proliferation. Together, our work offered a chemoproteomics approach and identified ENL as a novel histone β-hydroxybutyrylation effector that regulates gene transcription, providing new insight into the regulation mechanism and function of histone Kbhb.

Elucidating the binding partners of histone post-translational modifications (hPTMs) is key to understanding epigenetic regulatory pathways. Lysine β-hydroxybutyrylation (Kbhb) is a novel hPTM that couples metabolism to transcription. However, the effectors reading this mark are poorly understood as the Kbhb-mediated protein–protein interactions are weak and transient. Here, we presented a quantitative chemical proteomics approach using multivalent photoaffinity probes to robustly capture interactors of this mark. Thus, we identified ENL as a novel binder of Kbhb of histone H3 lysine 9 (H3K9bhb). Biochemical studies and CUT&Tag analysis further revealed that ENL recognizes H3K9bhb and co-localizes with it on gene promoters to modulate transcription and tumorigenesis. This study highlights ENL as a histone Kbhb reader for the regulation of transcription.
Histone post-translational modifications (hPTMs, e.g. lysine acetylation and methylation) are a group of fundamental epigenetic marks found in mammalian chromatin ( 1 , 2 ). With the development of mass spectrometry-based proteomics, a range of novel hPTMs has been reported, including various types of lysine acylation, such as crotonylation (Kcr) ( 3 ), succinylation (Ksucc) ( 4 ), 2-hydroxyisobutyrylation (Khib) ( 5 ), β-hydroxybutyrylation (Kbhb) ( 6 ) and lactylation (Kla) ( 7 ). Emerging evidence suggests that these hPTMs possess important roles in regulating cell processes, including gene transcription, DNA damage repair, replication and chromatin remodeling ( 8–11 ). Moreover, the hPTMs are typically considered as docking sites to execute these functions by recruiting various specific binding partners, referred to as readers ( 12–14 ). Following the first discovery of the bromodomain (BrD) as a reading module of acetyllysine ( 15 ), a number of readers such as YEATS, DPF and ZZ domains have been characterized for type- and site-specific readout of histone acetylation ( 16–20 ). However, downstream effectors capable of interpreting histone non-acetyl acylations such as β-hydroxybutyrylation are poorly understood.
Histone β-hydroxybutyrylation is a novel epigenetic regulatory mark that links metabolism to gene transcription. It is remarkably induced by β-hydroxybutyrate that is derived from starvation or diabetic ketosis of cells where cellular metabolism typically switches and the new steady-state balance exists ( 21 ). The mark may lead to particular transcription events that govern cell growth and development through associating with a set of up-regulated genes that distinguish histone acetylation, corroborating that histone Kbhb has distinct roles from histone Kac ( 6 ). Indeed, Zhang and co-workers ( 22 ) recently reported that BDH1-mediated histone Kbhb up-regulated stemness-associated genes, promoting propagation of hepatocellular carcinoma (HCC) cells. Similarly, the Huang group ( 23 ) uncovered that ketogenesis-generated histone Kbhb enhances gene expression and CD8 + T-cell memory development, coupling epigenetic modification with energy metabolism. In addition, Zheng and colleagues ( 24 ) showed that histone Kbhb regulates ferroptosis-suppressor gene expression in pancreatic acinar cells. However, how histone Kbhb regulates transcription of these gene remains largely elusive. Given the unique structure of Kbhb, traditional histone readers may lack sufficient ability to recognize this hPTM. It is one of the main reasons why readers of Kbhb have been unclear up to now. Thus, identification of readers that specifically recognize histone Kbhb is vital to understand the molecular mechanism of this epigenetic regulation.
Identification of hPTM effector proteins is challenging owing to the fact that the hPTM-mediated protein–protein interactions (PPIs) are weak and transient ( 25 , 26 ). Therefore, an affinity purification approach based on a mimic peptide ( 27 ) may not be applicable for the mining of hPTM readers, whereas photoaffinity probes can be an alternative method ( 28 , 29 ). We recently developed a self-assembled multivalent photoaffinity probe that we used for efficient and selective enrichment of histone Kcr readers and Khib erasers ( 30 , 31 ). In this study, we further design the probe and combine it with a quantitative proteomics approach to selectively profile binders of histone Kbhb. By using this method, the interactomes of β-hydroxybutyrylation of histone H3 lysine 9 (H3K9bhb) were determined, and ENL was identified as a novel H3K9bhb reader. Biochemical and molecular recognition studies and CUT&Tag analysis demonstrate that ENL recognizes H3K9bhb, and co-localizes with this mark on gene promoters. Disrupting the association between ENL and histone Kbhb by structure-guided mutation of Y78A in the YEATS domain reduced the recruitments of ENL to H3K9bhb-enriched peaks, resulting in the down-regulation of genes such as MYC that are responsible for tumorigenesis.
Materials and instruments
Histone peptides with and without lysine trimetylation or β-hydroxybutyrylation modification were synthesized and purified by high-performance liquid chromatography (HPLC) by Beijing SciLight Biotechnology Co Ltd. Thiolated polyethylene glycol (HS-PEG) modified with benzophenone (HS-PEG-Bpa) was obtained from ToYong Biotech Ltd. Gold nanoparticles were purchased from BBI solutions. HPLC solvents used for mass spectrometric analysis of proteins were purchased from Thermo Fisher Scientific Ltd. Antibodies against ENL were obtained from Abcam. Matrix-assisted laser desorption ionization–time of flight mass spectrometry (MALDI-TOF MS) spectra were acquired by an Autoflex III TOF/TOF mass spectrometer (Bruker), and protein samples were identified by a Nano-LC-Q-Exactive Plus mass spectrometer (Thermo Fisher Scientific, Waltham, MA, USA).
Synthesis and characterization of hPTM probes
For the fabrication of the probes, 2 mM peptides with or without PTMs and 1 mM HS-PEG-Bpa were mixed and added to the solution of gold nanoparticles (200 μl), and the mixture was shaken at room temperature for 12 h. Then, the functionalized gold nanoparticles were washed with H 2 O (50 μl) twice and the fabricated probes were stored at 4°C for further use. MALDI-TOF-MS and transmission electron microscopy (TEM) were used to confirm the probes.
Extraction of nuclear proteins
Nuclear proteins were extracted from cells using nuclear extraction reagents (Nucleoprotein Extraction Kit, Sangon Biotech). Briefly, HepG2 cells were washed twice with phosphate-buffered saline (PBS; 0.1 M phosphate, 0.15 M NaCl, pH 7.2) and harvested into a tube (1.5 ml). After removing PBS, hypotonic buffer (protease inhibitor added beforehand) was added and incubated for 10 min on ice. Then, the solution was centrifuged at 800 g for 5 min and the supernatant was discarded. The precipitate was washed with hypotonic buffer in a mixer for 30 s followed by centrifugation at 2500 g for another 5 min. After centrifugation, the supernatant was removed. Next, the precipitate was resuspended in lysis buffer and incubated for 20 min. Finally, nucleoprotein was collected by centrifugation at 20 000 g for 10 min.
Enrichment of endogenous binders by hPTM probes
The functionalized probes H3K9bhb and H3K9 were each incubated with 0.5 mg of nuclear extracts for 12 h at 4°C in a rotation wheel. Then, the mixture was irradiated at 365 nm on ice for 20 min using UVP Crosslinker (Analytik Jena). After centrifugation, the precipitate was washed twice with wash buffer 1 (4 M urea in PBS), followed by washing once with buffer 2 (50 mM Tris–HCl, pH 7.8, 200 mM NaCl, 2.5 mM KCl, 2.5 mM MgCl 2 , 1 mM ZnCl 2 ) and once with wash buffer 3 (100 mM NH 4 HCO 3 ). Next, the pellet was suspended in 50 μl of NH 4 HCO 3 (100 mM), and trypsin (1 μg) was added to digest it overnight at 37°C. Finally, the mixture was centrifuged for 2 min and the supernatant was collected. Then, 5 mM dithiothreitol (DTT) was added and incubated with the obtained solution for 1 h at 65°C, followed by reaction with 15 mM iodoacetamide for 45 min and 30 mM cysteine for 30 min at room temperature. The resulting peptides were desalted with C18 material and further analyzed by HPLC-MS/MS.
HPLC-MS/MS analysis
Each tryptic digest was redissolved in 7 μl of HPLC buffer A [0.1% (v/v) formic acid in water]. After centrifugation at 12 000 g for 2 min, the supernatant (5 μl) was injected into a Nano-LC system (EASY-nLC 1200, Thermo Fisher Scientific). Each sample was separated by a C18 column (50 μm inner diameter × 15 cm, 2 μm C18) with a 60 min HPLC gradient at a flow rate of 300 nl/min. The HPLC eluate was electrosprayed directly into an Orbitrap Q-Exactive Plus mass spectrometer (Thermo Fisher Scientific). The source was operated at 2.2 kV. The mass spectrometric analysis was carried out in a data-dependent mode with an automatic switch between a full MS scan and an MS/MS scan in the orbitrap. For full MS survey scan, the automatic gain control (AGC) target was 1e6, and the scan range was from 350 to 1750 with a resolution of 70 000. The 10 most intense peaks with charge state 2 and above were selected for fragmentation by higher energy collision dissociation (HCD) with a normalized collision energy of 27%. The MS2 spectra were acquired with 17 500 resolution. The exclusion duration for the data-dependent scan was 10 s, and the exclusion window was set at 1.6 Da.
Data processing
The resulting MS/MS data were searched using Proteome Discoverer software (v2.1) with an overall false discovery rate (FDR) for peptides of <1%. Proteins demonstrating an average score ( n = 3) of <4 were removed from the identification list. Peptide sequences were searched using trypsin specificity and allowing a maximum of two missed cleavages. Carbamidomethylation on cysteine was specified as a fixed modification. Oxidation of methionine and acetylation on the protein N-terminus were set as variable modifications. Mass tolerances for precursor ions were set at ±10 ppm for precursor ions and ±0.02 Da for MS/MS.
Western blot analysis
The enriched proteins were loaded and separated on an 8% sodium dodecylsulfate–polyacrylamide electrophoresis (SDS–PAGE) gel and transferred to a nitrocellulose membrane (Pall Corporation, 0.22 μm). The membranes were first blocked with 5% non-fat milk and incubated with primary antibodies (ENL) overnight at 4°C at a dilution of 1:500. After washing, the membranes were incubated with goat anti-rabbit horseradish peroxidase (HRP)-conjugated secondary antibody (1:5000) for 2 h at room temperature.
AutoDock analysis
AutoDock 4.0 was used to dock the peptides H3K9bhb and H3K9ac into the structures of ENL. The structure of ENL was taken from the Protein Data Bank (PDB) (PDB: 5J9S). Before the docking simulation, the peptide was placed into the middle of the ENL surface as the start point of docking. The parameters for docking were set as follows: the Lamarckian genetic algorithm (LGA) runs were set at 100, and the maximum number of energy evaluations was set at 25 million. The simulation box was fixed at the center of the substrate and the box size was set at 80 Å in all three dimensions. The conformation with the highest binding energy of small molecules was considered as the best conformation.
Recombinant protein expression and purification
Recombinant ENL YEATS (residues 1–148) was cloned into the ET28b-SUMO vector and expressed with an N-terminal 6× His-SUMO tag in Escherichia coli strain BL21(DE3) (ZOMANBIO) and induced overnight by 0.5 mM isopropyl-β- d -thiogalactoside at 16°C in LB medium. Overnight-induced cells were collected and suspended in lysis buffer: 50 mM Tris–HCl, pH 8.0, 500 mM NaCl and 1 mM phenylmethylsulfonyl fluoride (PMSF). Then the cells were lysed using an ultrasonic crusher. After centrifugation, the supernatant was applied to a nickel column, and proteins were eluted with 300 mM imidazole. The resultant proteins were treated with ULP enzyme overnight for His-SUMO tag removal. The tag-free ENL YEATS proteins were further concentrated to ∼8 mg/ml, and stored at −80°C. ENL YEATS mutants were generated using QuikChange (Genstar) methods and verified by sequencing. Recombinant mutant ENL YEATS proteins were expressed and purified with essentially the same method as for wild-type (WT) ENL YEATS .
Isothermal titration calorimetry (ITC)
The ITC experiments were carried out on the MicroCal PEAQ ITC instrument (Malvern Instrument) at 15°C. The protein at 100 μM was dropped into the 1000 μM peptide segment for 19 consecutive drops, and the resulting titration curve was drawn using the ‘one set of binding sites’ model and the Origin 7.0 program. The protein concentration was determined by UV absorption at 280 nm. The peptide concentration was measured by nanodrop.
Analytical gel filtration
Analytical gel filtration experiments for the detection of protein–peptide interactions were carried out using an analytical Superdex S200 (Cytiva) gel filtration column with a flow rate of 0.5 ml/min on an Äkta purifier system (GE Healthcare) in a 20 mM HEPES pH 7.5, 150 mM NaCl buffer at 4°C. The protein and peptide H3K9bhb were incubated at a ratio of 1:1.5 at 4°C and the total applied sample volumes were 300 μl in both cases. Protein elution was followed by recording the UV adsorption at 280 nm.
Fluorescence microscopy
After transfecting with WT-ENL or its mutants, and growth for 48 h, cells were washed in PBS in triplicate followed by being fixed for 15 min in PBS containing 4% (w/v) paraformaldehyde. After washing, the HepG2 cells were then permeabilized for 30 min with PBS containing 0.25% Triton X-100, blocked with 3% bovine serum albumin (BSA) in PBS for 2 h in room temperature, and incubated with mouse anti-DDDDK-Tag monoclonal antibody (Abclonal, AE005) and H3K9bhb (PTMBio, PTM-1250RM) antibody overnight at 4°C. After washing with PBS, cells were incubated with secondary antibodies coupled to AlexaFluor 488 or 647 for 1.5 h in room temperature, and then stained with 4′,6-diamidino-2-phenylindole (DAPI) for 5 min. Finally, cells were imaged using a Zeiss LSM 800 microscope with a ×63 oil objective. Images were merged using Adobe Photoshop and analyzed by ImageJ.
CUT&Tag
CUT&Tag is operated according to the manufacturer's instructions for the Hyperactive Universal CUT&Tag Assay Kit for Illumina (TD903, Vazyme Biotech). In brief, HepG2 cells expressing WT-ENL or Mutant-ENL were collected and counted for incubation with pre-treated concanavalin A (ConA) beads. Subsequently, cells were resuspended in an antibody buffer and incubated overnight at 4°C with the corresponding primary antibody of Flag or anti-H3K9bhb. The secondary antibodies were diluted in appropriate proportions and incubated with the cells at room temperature. Subsequently, pA/G-Tnp transposons were rotated and incubated with the samples for 1 h to activate the translocase fragment DNA and extract the DNA. The DNA library was constructed with the TruePreP Index Kit V2 for Illumina (TD202, Vazyme Biotech). The library was purified by VAHTS DNA Clean Beads (N411, Vazyme Biotech) and sequenced by Illumina novaseq 150PE.
ChIP-qPCR analysis
Chromatin precipitation (ChIP) analysis was performed essentially as described below. Briefly, HepG2 cells were cross-linked with 1% formaldehyde for 10 min and stopped with 125 mM glycine. The isolated nuclei were resuspended in nuclei lysis buffer and sonicated using a Bioruptor Sonicator (Diagenode). The samples were immunoprecipitated with 2–4 μg of the appropriate antibodies overnight at 4°C. Protein A/G beads were added and incubated for 1 h, and the immunoprecipitates were washed twice each with low-salt, high-salt and LiCl buffers. Eluted DNA was reverse-cross-linked, purified using a polymerase chain reaction (PCR) purification kit (Genestar) and analyzed by quantitative real-time PCR on the ABI 7500-FAST System using the Power SYBR Green PCR Master Mix (Genestar). Statistical differences were calculated using a two-way unpaired Student's t -test. The primers used for qPCR are listed in Supplementary Table S3 .
RNA-seq analysis
RNA-seq samples were sequenced using the Illumina Hiseq 2500, and raw reads were mapped to the human reference genome (hg19) and transcriptome using the RNA-seq unified mapper. Read counts for each transcript were calculated using HTseq v0.6.1 employing default parameters 54. Differential gene expression analyses were performed using the ‘exactTest’ function in edgeR v3.055. Gene Ontology (GO) analysis was performed using the DAVID Bioinformatics Resource 6.756. The volcano plot was drawn by using the ggplot2 package ( https://cran.r-project.org/package=ggplot2 ) in the R computing environment.
Cell Counting Kit-8 (CCK-8) assay
Cell Counting Kit-8 (CCK-8) was used to measure cell proliferation. HepG2 cells were seeded into 96-well plates at a density of 3000 cells per well. Every 24 h for 7 days, 10 μl of the CCK-8 solution was added to each well with incubation for 2 h at 37°C. The absorbance of each well was then measured at 450 nm using a microplate reader (Thermo Fisher Scientific). Finally, the numbers of living cells over 5 days were plotted in a graph to calculate the cell proliferation rate.
Cell migration assay
The migration assays were performed using a transwell chamber. After transfection for 24 h, HepG2 cells were seeded in transwell chambers at 7 × 10 4 cells per well. Forty hours later, the cells which had migrated through the filter were fixed and stained with 2% crystal violet. For each chamber, the mean of the migrated cell number from five randomly fields was calculated and displayed in the plot.
Development of a quantitative chemical proteomics approach for mapping hPTM binders
In order to selectively and robustly identify hPTM interactors, we envisaged a chemoproteomics strategy that coupled a multivalent photoaffinity probe with quantitative proteomics. We designed probe H3K9bhb that contains Kbhb-installed peptide (mimic histone Kbhb) and photo-cross-linker-linked PEG, based on the spacer of the cross-linker and the mark, leading to improvement in the efficiency of target identification. Furthermore, the multivalent effect of the photo-cross-linker produces multiple labeling events contributing to capture of weak PPIs. Based on the above, we prepared probe H3K9bhb through a self-assembled technique while a control probe H3K9, containing lysine 9 instead of Kbhb, was also synthesized to minimize non-specific binders and improve the determination of H3K9bhb interatomes (Figure 1A , B ).

Proteomic profiling of hPTM interactors using photoaffinity probes. ( A ) Schematic workflow for enrichment and identification of hPTM target proteins by comparative proteomics along with self-assembly multivalent photoaffinity probes. ( B ) Structure of lysine β-hydroxybutyrylation. AuNPs, gold nanoparticles; PEG, polyethylene glycol. ( C ) Volcano plot of protein enrichment ratio and statistical analysis from proteomic experiments ( n = 3) by using probes H3K4me3 and H3K4. Blue hits indicate that proteins meet the criteria (ratio ≥ 2.0 and P -value ≤ 0.05). ( D ) Several known H3K4me3 reader proteins identified with high confidence.
To test whether the strategy could be used to identify hPTM readers, we first set up comparative proteomic experiments to capture target proteins of H3K4me3, a well-established histone mark associated with actively transcribed genes ( 32 ). Similar to H3K9bhb, probe H3K4me3 and probe H3K4 were, respectively, prepared and incubated with cell lysate, and subsequently subjected to UV irradiation by which cross-linking between the probe and its targets could occur. After removing non-specific binders by stringent washing, the captured proteins were enriched by centrifugation and digested by on-bead trypsinization, followed by detection with HPLC-MS/MS to quantify protein abundance. Finally, the spectral counts ( 33 , 34 ) detected for each protein were used to calculate the enrichment ratios for proteins identified by probes H3K4me3 and H3K4 (Figure 1A ). We performed three biological replicates to reliably identify binders enriched by probe H3K4me3, and proteins with a maximal mean of < 2.0 spectral counts were discarded. For the remaining proteins, we used an averaged enrichment ratio (H3K4me3/H3K4) of 2.0 ( n = 3) as the cut-off to exclude non-specific binding proteins. Furthermore, a t -test between probe H3K4me3 and H3K4 was conducted to generate a set of proteins meeting a P -value < 0.05 as high-confidence targets. The identified proteins were then displayed by volcano plots as (log 2 ) of the enrichment ratio against their statistical significance [–log 10 ( P -value)] (Figure 1C ; Supplementary Table S1 ).
As a result, 43 protein hits that meet the above criteria were identified, and the GO analysis on these proteins demonstrated that prominent among them are those enriched in chromatin binding, transcription factor binding and transcription regulator activity ( Supplementary Figure S1 ), demonstrating that these proteins may be read by H3K4me3 to mediate cell functions such as gene expression. As expected, our analysis of proteins identified by the probe found several known readers of H3K4me3, such as TAF3 ( 35 ), PHF8 ( 36 ) and CHD1 ( 37 ), displaying 2.5- to 64.3-fold preference for the probe H3K4me3 over probe H3K4 (Figure 1D ). The result demonstrates that our approach is capable of identifying endogenous HPTM readers from cell lysates.
Identification of ENL as an H3K9bhb binder through the chemoproteomic approach
We next applied this validated chemoproteomics strategy to identify targets of H3K9bhb, a histone mark associated with gene transcription ( 22 ). Recently, the enzymes that are responsible for removing or installing this modification have been discovered ( 38 , 39 ), while readers which prefer this mark remain largely unknown. Thus, it is of great importance to mine readers of H3K9bhb in order to decipher its biological effects. Herein, we developed probe H3K9bhb and H3K9, confirmed by MS and TEM data ( Supplementary Figures S2 and S3 ), to uncover putative binders of the mark in cellular lysates. The probe H3K9bhb or H3K9 was first incubated with cell extracts, followed by UV-irradiation and stringent washing to remove non-specific binding proteins. Then, the enriched proteins were digested and subjected to LC-MS/MS analysis. Similarly, to exclude the false-positive binders, we also generated a volcano plot and screened proteins with a fold enrichment (probe H3K9bhb/H3K9) ≥2 and a P -value ≤ 0.05. As shown in Figure 2A and Supplementary Table S2 , 43 proteins, identified from the pulldowns by probe H3K9bhb, satisfied the criteria. We next employed GO analysis on these potential binding proteins regarding their molecular function distributions, and found that major proteins are enriched with nucleic acid binding, catalytic activity and transcription regulator activity (Figure 2B ).

Identification of ENL as a H3K9hbb-binding protein using a chemoproteomics approach. ( A ) Volcano plot of protein fold enrichment and P -value from proteomic experiments ( n = 3) by using probes H3K9hbb and H3K9. Red hits are proteins with a ratio ≥ 2.0 and P -value ≤ 0.05.( B ) Molecular function analysis of H3K9bhb targets (red hits in A) by GO. ( C ) Parallel reaction monitoring (PRM) mass spectrometry and ( D ) western blotting analysis for the captured binders by probes H3K9hbb and H3K9. ( E ) ITC fitting curves of the ENL titrated with unmodified (H3K9un) or β-hydroxybutyryl histone H31-17 peptides (H3K9bhb). ( F and G ) Molecular recognition analysis of H3K9bhb read by ENL. Electrostatic potential surface view of the ENL space filled by H3K9bhb peptide. Bottom right, close-up view of the H3K9bhb-binding pocket of ENL (F). ( G ) The bonding network between H3K9bhb peptide and ENL. Hydrogen bonds are shown as green dashes. Key residues of ENL are depicted as blue sticks and labeled in orange; the H3K9bhb peptide is shown as yellow sticks and labeled in black.
Considering that nucleic acid binding was the top-ranked pathway and the related proteins may function through binding to histones, we continued to focus on the proteins involved in this cluster. After ruling out several RNA-binding proteins, we further concentrated on four targets (ZNF787, TFCP2, ENL and GTF2H4) that are associated with chromatin binding. Further domain analysis indicated that only ENL possesses the binding modules of acetylated histone ( 40 ); we therefore speculated that the H3K9bhb mark may be recognized by ENL, and selected it for further investigation.
ENL efficiently binds to H3K9bhb through its YEATS domain in vitro
We next decided to investigate the putative interaction between ENL and the mark by using parallel reaction monitoring (PRM) MS, which has been reported as a targeted proteomic method for accurate quantitative measurement of proteins ( 41 ). Our result revealed that ENL exhibits a 3.9-fold enrichment for probe H3K9bhb compared with probe H3K9 (Figure 2C ), which is in line with the proteomics profiling data. In addition, analytical gel filtration of ENL with or without peptide H3K9bhb showed two obvious separating peaks ( Supplementary Figure S4 ), suggesting the binding of ENL and H3K9bhb. Next, to further confirm ENL–H3K9bhb interaction, we performed photoaffinity enrichment from a cell lysate followed by western blotting analysis of proteins isolated by probes H3K9bhb and H3K9, respectively. As expected, probe H3K9bhb captured ENL more efficiently than probe H3K9, validating that ENL could directly and selectively interact with H3K9bhb (Figure 2D ).
In light of the ENL YEATS domain being a reader of histone acetylation ( 40 ), we proposed that ENL might recognize H3K9bhb via its YEATS domain. To test this hypothesis, we recombinantly expressed the YEATS domain of ENL (ENL YEATS ), and performed an ITC assay using histone H3K14 (1–17) peptides, with binding dissociation constants ( K d ) of 0.71 μM, 8.44 μM and not detected (ND) for H3K9bhb, H3K9ac and unmodified peptides, respectively (Figure 2E ; Supplementary Figure S5A ). Notably, compared with H3K9ac, ENL YEATS revealed an ∼12-fold increase in affinity for H3K9bhb. Furthermore, pulldown assays using biotinylated peptides showed that the YEATS domain of ENL exhibited a higher binding affinity toward H3K9bhb than H3K9ac ( Supplementary Figure S5B ). In addition, we also implemented ITC detection using H3K9bhb peptide with other YEATS domain-containing proteins (AF9, GAS41 and YEATS2), and measured a K d of 11.0 μM, 6.7 μM and ND, respectively ( Supplementary Figure S5C ), which indicated that H3K9bhb may selectively recognize YEATS module proteins. Together, these results established that ENL favorably bound to H3K9bhb via its YEATS domain.
Moreover, to decipher the molecular basis for how ENL recognizes the H3K9bhb mark, we docked the binding of ENL YEATS (PDB: 5J9S) with H3K9bhb peptide. As shown in Figure 2F and G , H3K9bhb inserts into the binding pocket formed with ENL YEATS residues, such as H56, S58, F59 and Y78, in which an aromatic sandwich cage for K9bhb recognition is clamped by aromatic residues such as F59 and Y78. In addition to electrostatic and hydrophobic contacts, the recognition of H3K9bhb peptide by ENL is stabilized through a hydrogen bond of the Y78 residue and the hydroxyl group within β-hydroxybutyrylamide, differing from H3K9ac that is facilitated by a hydrogen bond between acetylamide and the Y78 main chain. This suggested that there may be different mechanisms for recognizing H3K9bhb and H3K9ac, thereby contributing to distinct affinities for ENL ( Supplementary Figures S5D and S6 ). Collectively, these findings demonstrate that ENL is able to preferably recognize H3K9bhb relying on some key residues such as Y78, as a potential reader of this histone mark.
ENL is intracellularly associated with H3K9bhb
To assess the association of ENL with H3K9bhb in cells, we set up ENL mutagenesis and immunofluorescence (IF) assay. Structure-guided mutagenesis was designed to alanine mutation of the Khbb-surrounding residues including S58, F59 and Y78. Subsequently, ITC assays revealed that the affinity of H3K9bhb binding for all mutations (S58A, F59A and Y78A) dramatically dropped in comparison with WT-ENL (Figure 3A ). We then performed IF imaging determination to investigate their co-localization in cells transfected with WT-ENL or FLAG-tagged mutants, followed by reaction with antibodies against FLAG or H3K9bhb. As shown in Figure 3B and C , FLAG-tagged ENL and H3K9bhb rendered an even distribution pattern in the nucleus, and the signals resulting from them were merged with a high Pearson correlation coefficient of 0.76, thereby validating their co-localization in cells. By contrast, the value was significantly reduced in the ENL mutants, which indicates the disruption of the association owing to the mutation. Together, these observations suggest that ENL interacts with H3K9bhb via key residues of its YEATS domain in cells.

ENL mutagenesis and co-localization studies. ( A ) ITC titration fitting curves of ENL mutants with H3K9bhb peptide. ( B ) Representative IF images of cells treated with antibodies against FLAG (red) or H3K9bhb (green). FLAG-tagged ENL or its mutants were transfected into cells for IF analysis. ( C ) Quantification of the FLAG-ENL or its mutants co-localized with H3K9bhb using Pearson's correlation analysis.
ENL co-localizes with H3K9bhb across the whole genome
ENL is associated with acute myeloid leukemia, but its relationship with HCC remains unclear. Utilizing gene expression profiling interactive analysis (GEPIA), we found that ENL in HCC was remarkably up-regulated, and the high expression level of ENL was linked to short overall survival ( Supplementary Figures S7 and S8 ). Based on this, we proposed that ENL may recognize H3K9bhb to modulate gene transcription, potentiating progression of HCC cells.
To investigate this, we firstly implemented CUT&Tag assays in HepG2 cells to test whether ENL links H3K9bhb in the native chromatin context. The cells stably expressing Flag-tagged ENL were immunoprecipitated using Flag antibodies or H3K9bhb antibodies, respectively. By high-throughput sequencing of these CUT&Tag experiments, we identified 9660 H3K9bhb-enriched peaks and 12 077 ENL-bound peaks, 7232 of which were co-occupied by both H3K9bhb and ENL (Figure 4A ). Notably, the overlapping peaks were mainly positioned within gene promoter regions (62.1%) and others were mainly localized in the intergenic regions such as enhancers (Figure 4B ), suggesting that H3K9bhb may associate with ENL to modulate gene transcription. Furthermore, the heatmap and average distribution of H3K9bhb and ENL in the promoter regions revealed a strong enrichment at transcription start sites (TSSs) and adjacent regions within 3 kb (Figure 4C ). Genome browser views of the CUT&Tag signals of selected genes, which related to tumorigenesis, further confirmed the co-localization of ENL with H3K9bhb in TSSs (Figure 4F ). Furthermore, Kyoto Encyclopedia of Genes and Genomes (KEGG) pathway analysis showed that ENL-bound and H3K9bhb-TSSs-marked genes were involved in the regulation of gene transcription, mitogen-acivated protein kinase (MAPK) signaling, focal adhesion, and so on (Figure 4D ).

ENL co-localizes with H3K9bhb across the whole genome through CUT&Tag analysis. ( A ) Venn diagram showing the overlap of H3K9bhb- and ENL-occupied genes in cells. ( B ) The distribution of overlapping peaks within genes. ( C ) The heatmap illustrating that H3K9bhb globally co-localized with ENL at promoter regions. ( D ) The bubble graph showing the enrichment pathways in the KEGG analysis of the overlapping genes in ENL and H3K9bhb CUT&Tag results. ( E ) Averaged genome-wide occupancies of WT-ENL and Mutant-ENL (Y78A) around TSSs. ( F ) The genome browser view of WT-ENL, Mutant-ENL (Y78A) and H3K9bhb at the CCND1, MYC and TRIM71 locus, respectively. The y -axis represents CUT&Tag intensity. ( G ) The quantitative results by ChIP-qPCR assay for the selected genes. Data are shown as means (±SEM) of two independent experiments.
Given that ENL enables recognition of histone acetylation and crotonylation marks, we further explored whether there are genes co-occupied by H3K9ac-ENL, H3K9cr-ENL and H3K9bhb-ENL interactions through CUT&Tag detection. Consequently, we identified 1946 peaks marked by these modifications, among which the peaks were mainly localized at promoter regions and the genes resulting from these peaks were enriched in a variety of functional processes ( Supplementary Figure S9 ). Importantly, there are a number of peaks that are specifically occupied by H3K9bhb-ENL, suggesting potential distinctive outputs mediated by this mark ( Supplementary Figure S9A ). Furthermore, H3K9ac rather than H3K9cr was marked at the H3K9bhb-ENL-enriched genes (such as MYC ) ( Supplementary Figure S9D ), indicating the putative synergistic effect by histone acetylation on H3K9bhb-regulated gene transcription.
To further validate the dependence of ENL-binding peaks on the YEATS domain, we performed CUT&Tag assays with cells expressing Mutant-ENL (Y78A). As shown in Figure 4E , compared with WT-ENL, the average promoter region occupancies of Mutant-ENL were dramatically reduced, suggesting that ENL binds to these gene regions relying on the YEATS domain. Consistently, the Y78A mutation greatly disrupted ENL’s association with H3K9bhb at the selected gene promoter regions shown by ChIP-qPCR analysis (Figure 4F , G ). Together, these findings demonstrate that ENL co-localizes with H3K9bhb across the genome (mainly on gene promoters), while the ENL YEATS mutation attenuates the correlation.
ENL interacts with H3K9bhb to regulate gene transcription depending on the YEATS domain
It was previously reported that ENL could activate oncogenic gene transcription through the link with histone acetylation. Given the association between ENL and H3K9bhb at gene promoters, we wondered if the ENL–H3K9bhb interaction could regulate gene expression. To this end, we performed RNA-seq by ectopically expressing WT-ENL or Mutant-ENL in HepG2 cells. Through the cut-off of log 2 (fold change)>1 and P -value < 0.05, our result showed that the Mutant-ENL leads to suppressed expression of 583 genes (mainly included in the regulation of lysine writer activity, RNA binding, and so on) (Figure 5A , B ), suggesting that ENL could be recruited to these genes to modulate transcription via the YEATS domain.

ENL correlates with H3K9bhb to regulate gene expression and cell survival relying on the YEATS domain. ( A ) Volcano plots of RNA-seq results of cells expressing WT-ENL compared with cells harboring Mutant-ENL. The up-regulated genes are colored in red, and down-regulated genes are shown in green. ( B ) The bubble graph showing the enrichment pathways in the KEGG analysis of the up-regulated genes in ENL RNA-seq compared with the ENL mutation group. ( C ) Venn diagram displaying the overlap of H3K9bhb-occupied and Mutant-ENL-down-regulated genes in cells. ( D ) The browser view of H3K9bhb CUT&Tag and ENL and its mutant RNA-seq track showing that mutation of ENL leads to reduced occupation at H3K9bhb-enriched TSSs, and down-regulates the expression of CCND1, MYC and TRIM71. ( E ) qRT-PCR analysis of the expression of the indicated genes in cells as in (D). ( F ) Cell proliferation assay in cells expressing WT-ENL or its mutants (Y78A). ( G ) Cell migration ability was determined by transwell assay in cells as in (F). ** P < 0.01; *** P < 0.001. ( H ) The proposed mechanism whereby H3K9bhb recruits ENL to chromatin, and associates with it at gene promoters to boost transcription.
To exclude the potential effect of histone acetylation on the regulation of gene expression, we integrated H3K9bhb-occupied genes with those down-regulated by Mutant-ENL to define the overlapping genes as targets of H3K9bhb-ENL recognition. As a result, 113 genes satisfied this criteria, and responded for both H3K9bhb and ENL (Figure 5C ). As expected, H3K9bhb and ENL CUT&Tag with RNA-seq track displayed that Mutant-ENL at H3K9bhb-enriched promoters results in down-regulation of the selected genes (Figure 5D ). Notably, their transcript levels were verified by reverse transcription–quantitative PCR (RT–qPCR) analysis (Figure 5E ). Furthermore, CCK-8 detection and transwell assay showed that mutation of ENL led to the remarkable reduction of cell proliferation and migration capacity (Figure 5F , G ). Collectively, our results reveal a model where ENL reads H3K9bhb relying on its YEATS domain at gene promoters and recruits other factors to chromatin, to foster expression of genes such as MYC that are crucial for cell proliferation and tumorigenesis (Figure 5H ).
In this study, we developed a quantitative chemoproteomics approach based on multivalent photoaffinity probes to capture hPTM-binding proteins. Using this strategy, we identified a number of known H3K4me3 readers, validating the effectiveness and advantage of the method. Moreover, we extended this strategy to mine the putative binders of H3K9bhb, a newly uncovered histone mark, and for the first time identify ENL as a novel target of this mark.
As a novel epigenetic mark, histone β-hydroxybutyrylation plays a key role in gene transcription. However, the involved regulation mechanism remains largely elusive. Given that histone readers serve as the core element of such epigenetic regulation, the identification of ENL provides a new opportunity to reveal the regulatory mechanism of histone Kbhb. Based on H3K9bhb chemoproteomics findings and biochemical and molecular docking studies, we revealed that ENL is capable of binding to H3K9bhb relying on its YEATS domain, in which the Y78 residue as the key site interacts with the β-hydroxybutyrate group to contribute to the recognition. Indeed, further CUT&Tag coupled with RNA-seq analysis revealed that the ENL-Y78A mutation disrupts the association with H3K9bhb on the promoters of genes such as MYC that are essential for tumorigenesis. Hence mutation of Y78A at ENL in clinical cancer samples may be explored as a promising candidate marker.
ENL has already been reported as a histone acetylation and crotonylation reader that modulates gene transcriptional programs. Here we also queried the candidate targets co-occupied by H3K9ac, H3K9cr, H3K9bhb and ENL, and demonstrated that there are numerous peaks exclusively marked by H3K9bhb-ENL in addition to the overlapping peaks, which indicated the potential distinctive gene transcription events regulated by H3K9bhb. Intriguingly, we also found that H3K9ac was enriched in the gene promoter regions of H3K9bhb-regulated genes such as MYC . Condisidering a higher binding affinity of H3K9bhb ( K d = 0.71 μM) than H3K9ac ( K d = 8.44 μM) towards ENL as well as lower peaks marked by H3K9bhb compared with H3K9ac, we surmise that histone Kbhb marks are likely to modulate transcription of these genes by competing for the binding of ENL with Kac, implying that H3K9bhb may function synergistically with H3K9ac through the recognition of ENL.
The work describes a mechanism of histone β-hydroxybutyrylation recruitment of ENL to gene promoters to activate transcription in cancer cells. Further investigations could assess whether the mechanism is available in other cells including starvation-induced liver cells. Future studies are also expected to determine the role of β-hydroxybutyrate in modulating histone Kbhb and thereby boosting cell proliferation.
In principle, we present a general chemoproteomic approach for capture of hPTM targets and identify ENL as a new reader of H3K9bhb. We envisage that our work will be useful for elucidating epigenetic regulatory mechanisms underlying histone marks in cells.
The mass spectrometry proteomics data have been deposited to the ProteomeXchange Consortium via the PRIDE ( 42 ) partner repository with the dataset identifier PXD051689. RNA-sequencing and CUT&Tag data are available through GEO (GSE266268, 266269).
Supplementary Data are available at NAR Online.
We thank members of the K.Z. laboratory for constructive comments and discussion on this work.
Author Contributions : G.Z. and K.Z. designed the research; Chen C., Cong C., G.Z., Z.J., F.Z., Y.L., Z.N., S.T. and X.B. performed the research; Chen C., G.Z., A.W. and Y.H. analyzed the data; and G.Z. and K.Z. wrote the paper.
This work was financially supported by the National Natural Science Foundation of China [22374106, 22074103 and 22274114]; and the Talent Excellence Program from Tianjin Medical University.
Conflict of interest statement . None declared.
Huang H. , Sabari B.R. , Garcia B.A. , Allis C.D. , Zhao Y.M. SnapShot: histone modifications . Cell . 2014 ; 159 : 458 – 459 .
Google Scholar
Strahl B.D. , Allis C.D. The language of covalent histone modifications . Nature . 2000 ; 403 : 41 – 45 .
Tan M. , Luo H. , Lee S. , Jin F. , Yang J.S. , Montellier E. , Buchou T. , Cheng Z. , Rousseaux S. , Rajagopal N. et al. . Identification of 67 histone marks and histone lysine crotonylation as a new type of histone modification . Cell . 2011 ; 146 : 1016 – 1028 .
Zhang Z.H. , Tan M.J. , Xie Z.Y. , Dai L.Z. , Chen Y. , Zhao Y.M. Identification of lysine succinylation as a new post-translational modification . Nat. Chem. Biol. 2011 ; 7 : 58 – 63 .
Dai L.Z. , Peng C. , Montellier E. , Lu Z.K. , Chen Y. , Ishii H. , Debernardi A. , Buchou T. , Rousseaux S. , Jin F.L. et al. . Lysine 2-hydroxyisobutyrylation is a widely distributed active histone mark . Nat. Chem. Biol. 2014 ; 10 : 365 – 373 .
Xie Z.Y. , Zhang D. , Chung D.J. , Tang Z.Y. , Huang H. , Dai L.Z. , Qi S.K. , Li J.Y. , Colak G. , Chen Y. et al. . Metabolic regulation of gene expression by histone lysine beta-hydroxybutyrylation . Mol. Cell . 2016 ; 62 : 194 – 206 .
Zhang D. , Tang Z.Y. , Huang H. , Zhou G.L. , Cui C. , Weng Y.J. , Liu W.C. , Kim S. , Lee S. , Perez-Neut M. et al. . Metabolic regulation of gene expression by histone lactylation . Nature . 2019 ; 574 : 575 – 580 .
Kouzarides T. Chromatin modifications and their function . Cell . 2007 ; 128 : 693 – 705 .
Allis C.D. , Jenuwein T. The molecular hallmarks of epigenetic control . Nat. Rev. Genet. 2016 ; 17 : 487 – 500 .
Sabari B.R. , Zhang D. , Allis C.D. , Zhao Y.M. Metabolic regulation of gene expression through histone acylations . Nat. Rev. Mol. Cell Biol. 2017 ; 18 : 90 – 101 .
Millan-Zambrano G. , Burton A. , Bannister A.J. , Schneider R. Histone post-translational modifications—cause and consequence of genome function . Nat. Rev. Genet. 2022 ; 23 : 563 – 580 .
Jenuwein T. , Allis C.D. Translating the histone code . Science . 2001 ; 293 : 1074 – 1080 .
Musselman C.A. , Lalonde M.E. , Cote J. , Kutateladze T.G. Perceiving the epigenetic landscape through histone readers . Nat. Struct. Mol. Biol. 2012 ; 19 : 1218 – 1227 .
Zhao S. , Allis C.D. , Wang G.G. The language of chromatin modification in human cancers . Nat. Rev. Cancer . 2021 ; 21 : 413 – 430 .
Owen D.J. , Ornaghi P. , Yang J.C. , Lowe N. , Evans P.R. , Ballario P. , Neuhaus D. , Filetici P. , Travers A.A. The structural basis for the recognition of acetylated histone H4 by the bromodomain of histone acetyltransferase Gcn5p . EMBO J. 2000 ; 19 : 6141 – 6149 .
Andrews F.H. , Strahl B.D. , Kutateladze T.G. Insights into newly discovered marks and readers of epigenetic information . Nat. Chem. Biol. 2016 ; 12 : 662 – 668 .
Li Y.Y. , Wen H. , Xi Y.X. , Tanaka K. , Wang H.B. , Peng D.N. , Ren Y.F. , Jin Q.H. , Dent S.Y.R. , Li W. et al. . AF9 YEATS domain links histone acetylation to DOT1L-mediated H3K79 methylation . Cell . 2014 ; 159 : 558 – 571 .
Andrews F.H. , Shinsky S.A. , Shanle E.K. , Bridgers J.B. , Gest A. , Tsun I.K. , Krajewski K. , Shi X.B. , Strahl B.D. , Kutateladze T.G. The Taf14 YEATS domain is a reader of histone crotonylation . Nat. Chem. Biol. 2016 ; 12 : 396 – 398 .
Ren X.L. , Zhou Y. , Xue Z.Y. , Hao N. , Li Y.Y. , Guo X.H. , Wang D.L. , Shi X.B. , Li H.T. Histone benzoylation serves as an epigenetic mark for DPF and YEATS family proteins . Nucleic Acids Res. 2021 ; 49 : 114 – 126 .
Mi W.Y. , Zhang Y. , Lyu J. , Wang X.L. , Tong Q. , Peng D.N. , Xue Y.M. , Tencer A.H. , Wen H. , Li W. et al. . The ZZ-type zinc finger of ZZZ3 modulates the ATAC complex-mediated histone acetylation and gene activation . Nat. Commun. 2018 ; 9 : 3759 .
Zhou T.T. , Cheng X. , He Y.Q. , Xie Y.M. , Xu F.Y. , Xu Y. , Huang W. Function and mechanism of histone beta-hydroxybutyrylation in health and disease . Front. Immunol. 2022 ; 13 : 981285 .
Zhang H. , Chang Z. , Qin L.N. , Liang B. , Han J.X. , Qiao K.L. , Yang C. , Liu Y.R. , Zhou H.G. , Sun T. MTA2 triggered R-loop trans-regulates BDH1-mediated beta-hydroxybutyrylation and potentiates propagation of hepatocellular carcinoma stem cells . Signal. Transduct. Target. Ther. 2021 ; 6 : 135 .
Zhang H.F. , Tang K. , Ma J.W. , Zhou L. , Liu J.C. , Zeng L.P. , Zhu L.Y. , Xu P.W. , Chen J. , Wei K.K. et al. . Ketogenesis-generated beta-hydroxybutyrate is an epigenetic regulator of CD8(+) T-cell memory development . Nat. Cell Biol. 2020 ; 22 : 18 – 25 .
Zheng Y.F. , Sun W.R. , Shan C. , Li B.R. , Liu J.Y. , Xing H. , Xu Q.L. , Cui B.P. , Zhu W.J. , Chen J. et al. . β-hydroxybutyrate inhibits ferroptosis-mediated pancreatic damage in acute liver failure through the increase of H3K9bhb . Cell Rep. 2022 ; 41 : 111847 .
Li X. , Kapoor T.M. Approach to profile proteins that recognize post-translationally modified histone ‘tails . J. Am. Chem. Soc. 2010 ; 132 : 2504 – 2505 .
Burton A.J. , Hamza G.M. , Zhang A.X. , Muir T.W. Chemical biology approaches to study histone interactors . Biochem. Soc. Trans. 2021 ; 49 : 2431 – 2441 .
Wysocka J. Identifying novel proteins recognizing histone modifications using peptide pull-down assay . Methods . 2006 ; 40 : 339 – 343 .
Zhang Z.Y. , Lin J.W. , Liu Z. , Tian G.F. , Li X.M. , Jing Y.H. , Li X. , Li X.D. Photo-cross-linking to delineate epigenetic interactome . J. Am. Chem. Soc . 2022 ; 144 : 20979 – 20997 .
Xie Y.S. , Du S.B. , Liu Z.Y. , Liu M. , Xu Z.Q. , Wang X.J. , Kee J.X. , Yi F. , Sun H.Y. , Yao S.Q. Chemical biology tools for protein lysine acylation . Angew. Chem. Int. Ed. Engl. 2022 ; 61 : e202200303 .
Zhai G.J. , Dong H.Y. , Guo Z.C. , Feng W. , Jin J. , Zhang T. , Chen C. , Chen P. , Tian S.S. , Bai X. et al. . An efficient approach for selective enrichment of histone modification readers using self-assembled multivalent photoaffinity peptide probes . Anal. Chem. 2018 ; 90 : 11385 – 11392 .
Dong H. , Zhai G. , Chen C. , Bai X. , Tian S. , Hu D. , Fan E. , Zhang K. Protein lysine de-2-hydroxyisobutyrylation by CobB in prokaryotes . Sci. Adv. 2019 ; 5 : eaaw6703 .
Vermeulen M. , Eberl H.C. , Matarese F. , Marks H. , Denissov S. , Butter F. , Lee K.K. , Olsen J.V. , Hyman A.A. , Stunnenberg H.G. et al. . Quantitative interaction proteomics and genome-wide profiling of epigenetic histone marks and their readers . Cell . 2010 ; 142 : 967 – 980 .
Arguello A.E. , DeLiberto A.N. , Kleiner R.E. RNA chemical proteomics reveals the N-6-methyladenosine (m(6)A)-regulated protein–RNA interactome . J. Am. Chem. Soc. 2017 ; 139 : 17249 – 17252 .
Dugan A. , Majmudar C.Y. , Pricer R. , Niessen S. , Lancia J.K. , Fung H.Y.H. , Cravatt B.F. , Mapp A.K. Discovery of enzymatic targets of transcriptional activators via in vivo covalent chemical capture . J. Am. Chem. Soc. 2016 ; 138 : 12629 – 12635 .
Vermeulen M. , Mulder K.W. , Denissov S. , Pijnappel W.W.M.P. , van Schaik F.M.A. , Varier R.A. , Baltissen M.P.A. , Stunnenberg H.G. , Mann M. , Timmers H.T.M. Selective anchoring of TFIID to nucleosomes by trimethylation of histone H3 lysine 4 . Cell . 2007 ; 131 : 58 – 69 .
Feng W.J. , Yonezawa M. , Ye J. , Jenuwein T. , Grummt I. PHF8 activates transcription of rRNA genes through H3K4me3 binding and H3K9me1/2 demethylation . Nat. Struct. Mol. Biol. 2010 ; 17 : 445 – 450 .
Flanagan J.F. , Mi L.Z. , Chruszcz M. , Cymborowski M. , Clines K.L. , Kim Y.C. , Minor W. , Rastinejad F. , Khorasanizadeh S. Double chromodomains cooperate to recognize the methylated histone H3 tail . Nature . 2005 ; 438 : 1181 – 1185 .
Zhang X. , Cao R. , Niu J. , Yang S. , Ma H. , Zhao S. , Li H. Molecular basis for hierarchical histone de-β-hydroxybutyrylation by SIRT3 . Cell Discov. 2019 ; 5 : 35 .
Huang H. , Zhang D. , Weng Y.J. , Delaney K. , Tang Z.Y. , Yan C. , Qi S.K. , Peng C. , Cole P.A. , Roeder R.G. et al. . The regulatory enzymes and protein substrates for the lysine beta-hydroxybutyrylation pathway . Sci. Adv. 2021 ; 7 : eabe2771 .
Wan L.L. , Wen H. , Li Y.Y. , Lyu J. , Xi Y.X. , Hoshii T. , Joseph J.K. , Wang X.L. , Loh Y.H.E. , Erb M.A. et al. . ENL links histone acetylation to oncogenic gene expression in acute myeloid leukaemia . Nature . 2017 ; 543 : 265 – 269 .
Urisman A. , Levin R.S. , Gordan J.D. , Webber J.T. , Hernandez H. , Ishihama Y. , Shokat K.M. , Burlingame A.L. An optimized chromatographic strategy for multiplexing in parallel reaction monitoring mass spectrometry: insights from quantitation of activated kinases . Mol. Cell Proteomics . 2017 ; 16 : 265 – 277 .
Perez-Riverol Y. , Bai J. , Bandla C. , Garcia-Seisdedos D. , Hewapathirana S. , Kamatchinathan S. , Kundu D.J. , Prakash A. , Frericks-Zipper A. , Eisenacher M. et al. . The PRIDE database resources in 2022: a hub for mass spectrometry-based proteomics evidences . Nucleic Acids Res. 2022 ; 50 : D543 – D552 .
Author notes
| Month: | Total Views: |
|---|---|
| June 2024 | 1,024 |
| July 2024 | 478 |
| August 2024 | 310 |
| September 2024 | 201 |
Email alerts
Citing articles via.
- Editorial Board
Affiliations
- Online ISSN 1362-4962
- Print ISSN 0305-1048
- Copyright © 2024 Oxford University Press
- About Oxford Academic
- Publish journals with us
- University press partners
- What we publish
- New features
- Open access
- Institutional account management
- Rights and permissions
- Get help with access
- Accessibility
- Advertising
- Media enquiries
- Oxford University Press
- Oxford Languages
- University of Oxford
Oxford University Press is a department of the University of Oxford. It furthers the University's objective of excellence in research, scholarship, and education by publishing worldwide
- Copyright © 2024 Oxford University Press
- Cookie settings
- Cookie policy
- Privacy policy
- Legal notice
This Feature Is Available To Subscribers Only
Sign In or Create an Account
This PDF is available to Subscribers Only
For full access to this pdf, sign in to an existing account, or purchase an annual subscription.
Information
- Author Services
Initiatives
You are accessing a machine-readable page. In order to be human-readable, please install an RSS reader.
All articles published by MDPI are made immediately available worldwide under an open access license. No special permission is required to reuse all or part of the article published by MDPI, including figures and tables. For articles published under an open access Creative Common CC BY license, any part of the article may be reused without permission provided that the original article is clearly cited. For more information, please refer to https://www.mdpi.com/openaccess .
Feature papers represent the most advanced research with significant potential for high impact in the field. A Feature Paper should be a substantial original Article that involves several techniques or approaches, provides an outlook for future research directions and describes possible research applications.
Feature papers are submitted upon individual invitation or recommendation by the scientific editors and must receive positive feedback from the reviewers.
Editor’s Choice articles are based on recommendations by the scientific editors of MDPI journals from around the world. Editors select a small number of articles recently published in the journal that they believe will be particularly interesting to readers, or important in the respective research area. The aim is to provide a snapshot of some of the most exciting work published in the various research areas of the journal.
Original Submission Date Received: .
- Active Journals
- Find a Journal
- Journal Proposal
- Proceedings Series
- For Authors
- For Reviewers
- For Editors
- For Librarians
- For Publishers
- For Societies
- For Conference Organizers
- Open Access Policy
- Institutional Open Access Program
- Special Issues Guidelines
- Editorial Process
- Research and Publication Ethics
- Article Processing Charges
- Testimonials
- Preprints.org
- SciProfiles
- Encyclopedia
Article Menu

- Subscribe SciFeed
- Recommended Articles
- Google Scholar
- on Google Scholar
- Table of Contents
Find support for a specific problem in the support section of our website.
Please let us know what you think of our products and services.
Visit our dedicated information section to learn more about MDPI.
JSmol Viewer
Transcription factor and protein regulatory network of pmacre1 in pinus massoniana response to pine wilt nematode infection.

1. Introduction
2. materials and methods, 2.1. plant materials, 2.2. cloning and analysis of the pmacre1 gene promoter in p. massoniana, 2.3. detection of pmacre1 gene promoter activity, 2.4. isolation of proteins binding to the pmacre1 gene promoter, 2.5. subcellular localization of proteins binding to the pmacre1 gene promoter, 2.6. inoculation of pine wood nematode to p. massoniana seedlings and proteins extraction, 2.7. co-ip for isolation of pmacre1 interacting proteins, 2.8. kegg enrichment analysis for pmacre1-interacting proteins, 2.9. bifc assay for validating interactions among pmccoaomt, pmcas, and pmacre1, 3.1. pmacre1 gene promoter and its cis-elements, 3.2. activity of the pmacre1 gene promoter, 3.3. dna-binding proteins of the pmacre1 gene promoter, 3.4. subcellular localization of the pmmyb8 transcription factor, 3.5. proteins interacting with pmacre1, 3.6. kegg enrichment analysis of pmacre1 interacting proteins in p. massoniana, 3.7. bifc validation of interactions between pmacre1 and pmccoaomt, pmcas, 4. discussion, supplementary materials, author contributions, data availability statement, conflicts of interest.
- Wang, X.Z.; Cao, Y.F.; Wang, L.F.; Piao, C.G.; Li, C.L. Current status of pine wilt disease and its control status. J. Environ. Entomol. 2018 , 40 , 256–267. [ Google Scholar ]
- Li, X.; Liu, X.T.; Wei, J.T.; Li, Y.; Tigabu, M.; Zhao, X.Y. Genetic improvement of Pinus koraiensis in China: Current Situation and future prospects. Forests 2020 , 11 , 148. [ Google Scholar ] [ CrossRef ]
- Suontama, M.; Li, Y.; Low, C.B.; Dungey, H.S. Genetic improvement of resistance to cyclaneusma needle cast in Pinus radiata . Can. J. Forest Res. 2019 , 49 , 128–133. [ Google Scholar ] [ CrossRef ]
- Grattapaglia, D.; Silva-Junior, O.B.; Resende, R.T.; Cappa, E.P.; Müller, B.S.F.; Tan, B.; Isik, F.; Ratcliffe, B.; El-Kassaby, Y.A. Quantitative genetics and genomics converge to accelerate forest tree breeding. Front. Plant Sci. 2018 , 9 , 1693. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Modesto, I.; Sterck, L.; Arbona, V.; Gómez-Cadenas, A.; Carrasquinho, I.; Van de Peer, Y.; Miguel, C.M. Insights into the mechanisms implicated in Pinus pinaster resistance to pinewood nematode. Front. Plant Sci. 2021 , 12 , 690857. [ Google Scholar ] [ CrossRef ]
- Liu, Q.; Wei, Y.; Xu, L.; Hao, Y.; Chen, X.; Zhou, Z. Transcriptomic profiling reveals differentially expressed genes associated with pine wood nematode resistance in masson pine ( Pinus massoniana Lamb.). Sci. Rep. 2017 , 7 , 4693. [ Google Scholar ] [ CrossRef ]
- Zheng, H.Y.; Xu, M.; Xu, F.Y.; Ye, J. A comparative proteomics analysis of Pinus massoniana inoculated with Bursaphelenchus xylophilus . Pak. J. Bot. 2015 , 47 , 1271–1280. [ Google Scholar ]
- Xu, L.; Liu, Z.Y.; Zhang, K.; Lu, Q.; Liang, J.; Zhang, X.Y. Characterization of the Pinus massoniana transcriptional response to Bursaphelenchus xylophilus infection using suppression subtractive hybridization. Int. J. Mol. Sci. 2013 , 14 , 11356–11375. [ Google Scholar ] [ CrossRef ]
- Liu, B.; Liu, Q.; Zhou, Z.; Yin, H.; Xie, Y. Overexpression of geranyl diphosphate synthase ( PmGPPS1 ) boosts monoterpene and diterpene production involved in the response to pine wood nematode invasion. Tree Physiol. 2022 , 42 , 411–424. [ Google Scholar ] [ CrossRef ]
- Liu, B.; Liu, Q.; Zhou, Z.; Yin, H.; Xie, Y.; Wei, Y. Two terpene synthases in resistant Pinus massoniana contribute to defence against Bursaphelenchus xylophilus . Plant Cell Environ. 2021 , 41 , 257–274. [ Google Scholar ] [ CrossRef ]
- Xie, W.F.; Huang, A.Z.; Li, H.M.; Feng, L.Z.; Zhang, F.P.; Guo, W.X. Identification and comparative analysis of microRNAs in Pinus massoniana infected by Bursaphelenchus xylophilus . Plant Growth Regul. 2017 , 83 , 223–232. [ Google Scholar ] [ CrossRef ]
- Xie, W.F.; Liang, G.H.; Huang, A.Z.; Zhang, F.P.; Guo, W.X. Comparative study on the mRNA expression of Pinus massoniana infected by Bursaphelenchus xylophilus . J. For. Res. 2020 , 31 , 75–86. [ Google Scholar ] [ CrossRef ]
- Xie, W.F.; Liang, G.H. Expression correlation between miRNA and mRNA from needle leaves of Pinus massoniana with Bursaphelenchus xylophilus Infestation. Forest Res. 2018 , 31 , 7–14. [ Google Scholar ]
- Dangl, J.L.; Jones, J.D.G. Plant pathogens and integrated defence responses to infection. Nature 2001 , 411 , 826–833. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Xie, Y.; Liu, B.; Gao, K.; Zhao, Y.; Li, W.; Deng, L.; Zhou, Z.; Liu, Q. Comprehensive analysis and functional verification of the Pinus massoniana NBS-LRR gene family involved in the resistance to Bursaphelenchus xylophilus . Int. J. Mol. Sci. 2023 , 24 , 1812. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Hong, W.; Xu, Y.P.; Zheng, Z.; Cao, J.S.; Cai, X.Z. Comparative transcript profiling by cDNA-AFLP reveals similar patterns of Avr4/Cf-4- and Avr9/Cf-9-dependent defence gene expression. Mol. Plant Pathol. 2007 , 8 , 515–527. [ Google Scholar ] [ CrossRef ]
- González-Lamothe, R.; Tsitsigiannis, D.I.; Ludwig, A.A.; Panicot, M.; Shirasu, K.; Jones, J.D. The U-box protein CMPG1 is required for efficient activation of defense mechanisms triggered by multiple resistance genes in tobacco and tomato. Plant Cell. 2006 , 18 , 1067–1083. [ Google Scholar ] [ CrossRef ]
- Rowland, O.; Ludwig, A.A.; Merrick, C.; Baillieul, F.; Tracy, F.; Durrant, W.E.; Fitz-Laylin, L.; Nekrasov, V.; Yoshioka, H.; Jonathan, J.D.G. Functional analysis of Avr9/Cf-9 rapidly elicited genes identifies a protein kinase, ACIK1, that is essential for full Cf-9-dependent disease resistance in tomato. Plant Cell. 2005 , 17 , 295–310. [ Google Scholar ] [ CrossRef ]
- Durrant, W.E.; Rowland, O.; Piedras, P.; Hammond-Kosack, K.E.; Jones, J.D. cDNA-AFLP reveals a striking overlap in race-specific resistance and wound response gene expression profiles. Plant Cell. 2000 , 12 , 963–977. [ Google Scholar ] [ CrossRef ]
- Ni, X.; Tian, Z.; Liu, J.; Song, B.; Xie, C. Cloning and molecular characterization of the potato RING finger protein gene StRFP1 and its function in potato broad-spectrum resistance against Phytophthora infestans . J. Plant Physiol. 2010 , 167 , 488–496. [ Google Scholar ] [ CrossRef ]
- de Vega, D.; Holden, N.; Hedley, P.E.; Morris, J.; Luna, E.; Newton, A. Chitosan primes plant defence mechanisms against Botrytis cinerea , including expression of Avr9/Cf-9 rapidly elicited genes. Plant Cell Environ. 2021 , 44 , 290–303. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Li, G.; Asiegbu, F.O. Induction of Pinus sylvestris PsACRE , a homology of Avr9/Cf-9; rapidly elicited defense-related gene following infection with root rot fungus Heterobasidion annosum . Plant Sci. 2004 , 167 , 535–540. [ Google Scholar ] [ CrossRef ]
- Nicaise, V.; Roux, M.; Zipfel, C. Recent advances in PAMP-triggered immunity against bacteria: Pattern recognition receptors watch over and raise the alarm. Plant Physiol. 2009 , 150 , 1638–1647. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- de Vega, D.; Newton, A.C.; Sadanandom, A. Post-translational modifications in priming the plant immune system: Ripe for exploitation? FEBS Letters 2018 , 592 , 1929–1936. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Schwessinger, B.; Zipfel, C. News from the frontline: Recent insights into PAMP-triggered immunity in plants. Curr. Opin. Plant Biol. 2008 , 11 , 389–395. [ Google Scholar ] [ CrossRef ]
- Xie, W.F.; Xu, X.M.; Qiu, W.J.; Lai, X.L.; Liu, M.X.; Zhang, F.P. Expression of PmACRE1 in Arabidopsis thaliana enables host defence against Bursaphelenchus xylophilus infection. BMC Plant Biol. 2022 , 22 , 541. [ Google Scholar ] [ CrossRef ]
- Fang, C.X.; Yang, L.K.; Chen, W.X.; Li, L.L.; Zhang, P.L.; Li, Y.Z.; He, H.B.; Lin, W.X. MYB57 transcriptionally regulates MAPK11 to interact with PAL2;3 and modulate rice allelopathy. J. Exp. Bot. 2020 , 71 , 2127–2141. [ Google Scholar ] [ CrossRef ]
- Yi, S.; Jin, W.T.; Yuan, Y.N.; Fang, Y.H. An optimized CTAB method for genomic DNA extraction from freshly-picked Pinnae of Fern, Adiantum capillus-veneris L. Bio-Protocol 2018 , 8 , e2906. [ Google Scholar ] [ CrossRef ]
- Zhang, Z.Y.; Zhang, K.Y.; Lin, M.S.; Luo, H.W.; Lin, F.Y. Pathogenicity determination of Bursaphelenchus xylophilus isolates to Pine thunbergii . J.Nanjing Agric. Univ. 2002 , 25 , 43–46. [ Google Scholar ]
- Zhu, L.H.; Zhang, X.Y.; Xia, X.R.; Wan, Y.; Dai, S.J.; Ye, J.R. Pathogenicity of aseptic Bursaphelenchus xylophilus on Pinus massoniana . Sci. Silvae Sin. 2020 , 56 , 63–69. [ Google Scholar ]
- Wang, Y.; Jin, M.; Wang, Y.; Yang, Y.; Yu, A. Infestation of pine seedlings ( Pinus thunbergii Parl.) with pine wood nematode, Bursaphelenchus xylophilus (Nematoda: Aphelenchoididae) through needle leaves. J. Asia-Pac. Entomol. 2024 , 27 , 102252. [ Google Scholar ] [ CrossRef ]
- An, Y.; Li, Y.; Ma, L.; Li, D.; Zhang, W.; Feng, Y.; Liu, Z.; Wang, X.; Wen, X.; Zhang, X. Transcriptomic response of Pinus massoniana to infection stress from the pine wood nematode Bursaphelenchus xylophilus . Stress. Biol. 2023 , 3 , 50. [ Google Scholar ] [ CrossRef ]
- Shin, H.; Lee, H.; Woo, K.S.; Noh, E.W.; Koo, Y.B.; Lee, K.J. Identification of genes upregulated by pine wood nematode inoculation in Japanese red pine. Tree Physiol. 2009 , 29 , 411–421. [ Google Scholar ] [ CrossRef ]
- dos Santos, C.S.S.; de Vasconcelos, M.W. Identification of genes differentially expressed in Pinus pinaster and Pinus pinea after infection with the pine wood nematode. Eur. J. Plant Pathol. 2012 , 132 , 407–418. [ Google Scholar ] [ CrossRef ]
- Hirao, T.; Matsunaga, K.; Hirakawa, H.; Shirasawa, K.; Isoda, K.; Mishima, K.; Tamura, M.; Watanabe, A. Construction of genetic linkage map and identification of a novel major locus for resistance to pine wood nematode in Japanese black pine ( Pinus thunbergii ). BMC Plant Biol. 2019 , 19 , 424. [ Google Scholar ] [ CrossRef ]
- Wang, X.Y.; Wu, X.Q.; Wen, T.Y.; Feng, Y.Q.; Zhang, Y. Transcriptomic analysis reveals differentially expressed genes associated with pine wood nematode resistance in resistant Pinus thunbergii . Tree Physiol. 2023 , 7 , 995–1008. [ Google Scholar ] [ CrossRef ]
- Wang, Y.; Xu, W.; Chen, Z.X.; Han, B.; Haque, M.E.; Liu, A.Z. Gene structure, expression pattern and interaction of Nuclear Factor-Y family in castor bean ( Ricinus communis ). Planta 2018 , 247 , 559–572. [ Google Scholar ] [ CrossRef ]
- Kuang, J.F.; Wu, C.J.; Guo, Y.F.; Walther, D.; Shan, W.; Chen, J.Y.; Chen, L.; Lu, W.J. Deciphering transcriptional regulators of banana fruit ripening by regulatory network analysis. Plant Biotech. J. 2020 , 19 , 477–489. [ Google Scholar ] [ CrossRef ]
- Zhu, J.; Wei, X.; Yin, C.; Zhou, H.; Yan, J.; He, W.; Yan, J.; Li, H. ZmEREB57 regulates OPDA synthesis and enhances salt stress tolerance through two distinct signalling pathways in Zea mays . Plant Cell Environ. 2023 , 46 , 2867–2883. [ Google Scholar ] [ CrossRef ]
- Xie, L.; Liu, S.; Zhang, Y.; Tian, W.; Xu, D.; Li, J.; Luo, X.; Li, L.; Bian, Y.; Li, F.; et al. Efficient proteome-wide identification of transcription factors targeting Glu-1: A case study for functional validation of TaB3-2A1 in wheat. Plant Biotech. J. 2023 , 21 , 1952–1965. [ Google Scholar ] [ CrossRef ]
- Dubos, C.; Stracke, R.; Grotewold, E.; Weisshaar, B.; Martin, C.; Lepiniec, L. MYB transcription factors in Arabidopsis . Trends Plant Sci. 2010 , 15 , 573–581. [ Google Scholar ] [ CrossRef ]
- Craven-Bartle, B.; Pascual, M.B.; Cánovas, F.M.; Avila, C.A. Myb transcription factor regulates genes of the phenylalanine pathway in maritime pine. Plant J. 2013 , 74 , 755–766. [ Google Scholar ] [ CrossRef ]
- Pandey, A.; Misra, P.; Chandrashekar, K.; Trivedi, P.K. Development of AtMYB12 -expressing transgenic tobacco callus culture for production of rutin with biopesticidal potential. Plant Cell Rep. 2012 , 31 , 1867–1876. [ Google Scholar ] [ CrossRef ]
- Yu, Y.; Guo, D.D.; Min, D.H.; Cao, T.; Ning, L.; Jiang, Q.Y.; Sun, X.J.; Zhang, H.; Tang, W.S.; Gao, S.Q.; et al. Foxtail millet MYB-like transcription factor SiMYB16 confers salt tolerance in transgenic rice by regulating phenylpropane pathway. Plant Physiol. Biochem. 2023 , 195 , 310–321. [ Google Scholar ] [ CrossRef ]
- Liu, D.L.; Xue, Y.S.; Wang, R.Z.; Song, B.B.; Xue, C.; Shan, Y.F.; Xue, Z.L.; Wu, J. PbrMYB4, a R2R3-MYB protein, regulates pear stone cell lignification through activation of lignin biosynthesis genes. Hortic. Plant J. 2024; in press . [ Google Scholar ] [ CrossRef ]
- Fan, T.; Fan, Y.; Yang, Y.; Qian, D.; Niu, Y.; An, L.; Xiang, Y. SEC1A and SEC6 synergistically regulate pollen tube polar growth. J. Integr. Plant Biol. 2023 , 65 , 1717–1733. [ Google Scholar ] [ CrossRef ]
- Koh, H.; Joo, H.; Lim, C.W.; Lee, S.C. Roles of the pepper JAZ protein CaJAZ1-03 and its interacting partner RING-type E3 ligase CaASRF1 in regulating ABA signaling and drought responses. Plant Cell Environ. 2023 , 46 , 3242–3257. [ Google Scholar ] [ CrossRef ]
- Wang, H.M.; Yu, Y.C.; Fu, C.X.; Zhou, G.K.; Gao, H.H. Progress of a key enzyme-caffeoyl-CoA 3-O-methyltransferase in lignin biosynthesis. Genom. Appl. Biol. 2014 , 33 , 458–466. [ Google Scholar ]
- Tak, H.; Negi, S.; Ganapathi, T.R. Overexpression of MusaMYB31 , a R2R3 type MYB transcription factor gene indicate its role as a negative regulator of lignin biosynthesis in banana. PLoS ONE 2017 , 12 , e172695. [ Google Scholar ] [ CrossRef ]
- Wagner, A.; Tobimatsu, Y.; Phillips, L.; Flint, H.; Torr, K.; Donaldson, L.; Pears, L.; Ralph, J. CCoAOMT suppression modifies lignin composition in Pinus radiata . Plant J. 2011 , 67 , 119–129. [ Google Scholar ] [ CrossRef ]
- Zhang, Y.; Lv, H.P.; Ma, C.Y.; Guo, L.; Tan, J.F.; Peng, Q.H.; Lin, Z. Cloning of a caffeoyl-coenzyme A O-methyltransferase from Camellia sinensis and analysis of its catalytic activity. J. Zhejiang Univ. Sci. B 2015 , 16 , 103–112. [ Google Scholar ] [ CrossRef ]
- Do, C.T.; Pollet, B.; Thévenin, J.; Sibout, R.; Denoue, D.; Barrière, Y.; Lapierre, C.; Jouanin, L. Both caffeoyl Coenzyme A 3-O-methyltransferase 1 and caffeic acid O-methyltransferase 1 are involved in redundant functions for lignin, flavonoids and sinapoyl malate biosynthesis in Arabidopsis . Planta 2007 , 226 , 1117–1129. [ Google Scholar ] [ CrossRef ]
- Day, A.; Neutelings, G.; Nolin, F.; Grec, S.; Habrant, A.; Crônier, D.; Maher, B.; Rolando, C.; David, H.; Chabbert, B.; et al. Caffeoyl coenzyme A O-methyltransferase down-regulation is associated with modifications in lignin and cell-wall architecture in flax secondary xylem. Plant Physiol. Biochem. 2009 , 47 , 9–19. [ Google Scholar ] [ CrossRef ]
- Jia, L.J.; Tang, H.Y.; Wang, W.Q.; Yuan, T.L.; Wei, W.Q.; Pang, B.; Gong, X.M.; Wang, S.F.; Li, Y.J.; Zhang, D.; et al. A linear nonribosomal octapeptide from Fusarium graminearum facilitates cell-to-cell invasion of wheat. Nat. Commun. 2019 , 10 , 1–20. [ Google Scholar ] [ CrossRef ]
- Nomura, H.; Komori, T.; Uemura, S.; Kanda, Y.; Shimotani, K.; Nakai, K.; Furuichi, T.; Takebayashi, K.; Sugimoto, T.; Sano, S.; et al. Chloroplast-mediated activation of plant immune signalling in Arabidopsis . Nat. Commun. 2012 , 3 , 926. [ Google Scholar ] [ CrossRef ]
- Nomura, H.; Komori, T.; Kobori, M.; Nakahira, Y.; Shiina, T. Evidence for chloroplast control of external Ca 2+ -induced cytosolic Ca 2+ transients and stomatal closure. Plant J. 2008 , 53 , 988–998. [ Google Scholar ] [ CrossRef ]
- Madhu; Sharma, A.; Kaur, A.; Upadhyay, S.K. Glutathione peroxidases in plants: Innumerable role in abiotic stress tolerance and plant development. J. Plant Growth Regul. 2023 , 42 , 598–613. [ Google Scholar ] [ CrossRef ]
- Bela, K.; Bangash, S.A.K.; Riyazuddin; Csiszár, J. Plant Glutathione Peroxidases: Antioxidant Enzymes in Plant Stress Responses and Tolerance. In Glutathione in Plant Growth, Development, and Stress Tolerance ; Hossain, M., Mostofa, M., Diaz-Vivancos, P., Burritt, D., Fujita, M., Tran, L.S., Eds.; Springer: Cham, Switzerland, 2017; pp. 113–126. [ Google Scholar ]
- Fukuda, H. Signals that control plant vascular cell differentiation. Nat. Rev. Mol. Cell Biol. 2004 , 5 , 379–391. [ Google Scholar ] [ CrossRef ]
- Aloni, R. Role of hormones in controlling vascular differentiation and the mechanism of lateral root initiation. Planta 2013 , 238 , 819–830. [ Google Scholar ] [ CrossRef ]
- Li, Y.H.; Han, S.Q.; Qi, Y.H. Advances in structure and function of auxin response factor in plants. J. Integr. Plant Biol. 2022 , 65 , 617–632. [ Google Scholar ] [ CrossRef ]
- Cancé, C.; Martin-Arevalillo, R.; Boubekeur, K.; Dumas, R. Auxin response factors are keys to the many auxin doors. New Phytol. 2022 , 235 , 402–419. [ Google Scholar ] [ CrossRef ]
- Chen, H.; Tan, J.; Liang, X.; Tang, S.; Jia, J.; Yang, Z. Molecular mechanism of lateral bud differentiation of Pinus massoniana based on high-throughput sequencing. Sci. Rep. 2021 , 11 , 9033. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Ha, S.; Tran, L.S. Understanding plant responses to phosphorus starvation for improvement of plant tolerance to phosphorus deficiency by biotechnological approaches. Crit. Rev. Biotechnol. 2014 , 34 , 16–30. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Sekhwal, M.K.; Swami, A.K.; Sharma, V.; Sarin, R. Identification of drought-induced transcription factors in Sorghum bicolor using GO term semantic similarity. Cell Mol. Biol. Lett. 2015 , 20 , 1–23. [ Google Scholar ] [ CrossRef ]
- Zhao, F.Y.; Hu, F.; Zhang, S.Y.; Wang, K.; Zhang, C.R.; Liu, T. MAPKs regulate root growth by influencing auxin signaling and cell cycle-related gene expression in cadmium-stressed rice. Environ. Sci. Pollut. Res. Int. 2013 , 20 , 5449–5460. [ Google Scholar ] [ CrossRef ]
Click here to enlarge figure
| Cis-Regulatory Element | Core Sequence | Totals | Function |
|---|---|---|---|
| AAGAA-motif | gGTAAAGAAA/GAAAGAA | 3 | Unknown |
| ABRE | CACGTG/CACGTG | 3 | cis-acting element involved in the abscisic acid responsiveness |
| ABRE3a | TACGTG | 1 | cis-acting element involved in abiotic stress and signaling pathway |
| ABRE4 | CACGTA | 1 | cis-acting element involved in abiotic stress and signaling pathway |
| AE-box | AGAAACTT | 1 | part of a module for light response |
| ARE | AAACCA | 5 | cis-acting regulatory element essential for the anaerobic induction |
| AT~TATA-box | TATATAAA | 3 | involved in the formation of a transcription initiation complex |
| CAAT-box | CAAAT/CAAT | 39 | common cis-acting element in promoter and enhancer regions |
| CCAAT-box | CAACGG | 1 | MYBHv1 binding site |
| ERE | ATTTTAAA | 1 | cis-acting element involved in the response to ethylene |
| G-Box | CACGTG | 2 | cis-acting regulatory element involved in light responsiveness |
| G-box | TAACACGTAG/GCCACGTGGA/TACGTG/CACGTG | 4 | cis-acting regulatory element involved in light responsiveness |
| GT1-motif | GGTTAA | 1 | light responsive element |
| LTR | CCGAAA | 1 | cis-acting element involved in low-temperature responsiveness |
| MBS | CAACTG | 2 | MYB binding site involved in drought-inducibility |
| MRE | AACCTAA | 1 | MYB binding site involved in light responsiveness |
| MYB | CAACAG/CAACCA/TAACCA | 6 | MYB binding site |
| MYB recognition site | CCGTTG | 1 | MYB binding site |
| MYB-like sequence | TAACCA | 3 | MYB binding site |
| MYC | CAATTG/CATTTG | 2 | basic helix-loop-helix (bHLH) binding motifs |
| Myb | CAACTG | 2 | MYB binding site |
| Myb-binding site | CAACAG | 2 | MYB binding site |
| O2-site | GATGATGTGG | 1 | cis-acting regulatory element involved in zein metabolism regulation |
| P-box | CCTTTTG | 1 | gibberellin-responsive element |
| STRE | AGGGG | 2 | involved in peroxisome biogenesis, function, and regulation |
| TATA | TATAAAAT | 2 | involved in the formation of a transcription initiation complex |
| TATA-box | TATATAA | 45 | core promoter element around −30 of transcription start |
| TCA-element | CCATCTTTTT | 2 | cis-acting element involved in salicylic acid responsiveness |
| TCCC-motif | TCTCCCT | 1 | part of a light responsive element |
| Unnamed_1 | CGTGG | 2 | Unknown |
| Unnamed_2 | AACCTAACCT | 1 | Unknown |
| Unnamed_4 | CTCC | 6 | Unknown |
| W box | TTGACC | 1 | a core sequence acts as a binding site for WRKY TFs |
| WUN-motif | AAATTACT/TTATTACAT | 2 | wound-responsive element |
| chs-CMA1a | TTACTTAA | 1 | part of a light responsive element |
| circadian | CAAAGATATC | 1 | cis-acting regulatory element involved in circadian control |
| Accession | Description | Sum PEP Score | Peptides | Unique Peptides |
|---|---|---|---|---|
| AIZ74346.1 | phosphoglycerate kinase 1 [Pinus massoniana] | 109.786 | 26 | 26 |
| AHL24663.1 | ribulose-1,5-bisphosphate carboxylase/oxygenase activase large isoform [Pinus massoniana] | 116.557 | 23 | 23 |
| ULQ63856.1 | ATP synthase CF1 beta subunit (chloroplast) [Cuscuta japonica] | 47.272 | 12 | 2 |
| AIZ74323.1 | actin related protein 1 [Pinus massoniana] | 28.62 | 11 | 11 |
| QEP51812.1 | elongation factor [Pinus massoniana] | 35.434 | 10 | 1 |
| AIZ74328.1 | translation elongation factor 1-alpha [Pinus massoniana] | 33.002 | 10 | 1 |
| AFA51418.1 | extracellular calcium sensing receptor [Pinus massoniana] | 28.98 | 10 | 10 |
| AGC13142.1 | DHAR class glutathione S-transferase [Pinus tabuliformis] | 23.517 | 9 | 9 |
| ADV40957.1 | caffeoyl-CoAO-methyltransferase [Pinus radiata] | 17.378 | 7 | 7 |
| AIZ74331.1 | alpha-tubulin [Pinus massoniana] | 14.751 | 7 | 6 |
| AGT98543.1 | glutathione peroxidase 2 [Pinus tabuliformis] | 13.11 | 6 | 4 |
| AIZ74330.1 | cyclophilin [Pinus massoniana] | 14.913 | 5 | 5 |
| QSD59059.1 | heat shock 90 kDa protein [Pinus sylvestris] | 10.745 | 5 | 5 |
| CAA41404.1 | Type 1 chlorophyll a /b-binding protein [Pinus sylvestris] | 7.835 | 2 | 2 |
| ACJ70336.1 | putative ribosomal protein S10, partial [Pinus sylvestris] | 4.348 | 2 | 1 |
| AGC13149.1 | phi class glutathione S-transferase [Pinus tabuliformis] | 3.945 | 2 | 2 |
| AHA90706.1 | aquaporin [Pinus massoniana] | 3.003 | 2 | 2 |
| CBM40481.1 | MYB8 transcription factor [Pinus pinaster] | 0.752 | 1 | 1 |
| ACL14200.1 | putative ribosomal protein L34, partial [Pinus sylvestris] | 0.749 | 1 | 1 |
| AXQ01589.1 | photosystem II protein K (plastid) [Pinus pinea] | 0.714 | 1 | 1 |
| YP_008082259.1 | ribosomal protein S12 (chloroplast) [Pinus massoniana] | 0.674 | 1 | 1 |
| Accession | Description | Sum PEP Score | Peptides | Unique Peptides |
|---|---|---|---|---|
| AHL24663.1 | ribulose-1,5-bisphosphate carboxylase/oxygenase activase large isoform [Pinus massoniana] | 68.19 | 23 | 23 |
| WCL24039.1 | ribulose-1,5-bisphosphate carboxylase/oxygenase large subunit (chloroplast) [Pinus massoniana] | 30.174 | 13 | 13 |
| QEP51812.1 | elongation factor [Pinus massoniana] | 18.672 | 8 | 2 |
| ASU09148.1 | disease resistance protein [Pinus massoniana] | 21.065 | 7 | 7 |
| AIZ74328.1 | translation elongation factor 1-alpha [Pinus massoniana] | 16.688 | 7 | 1 |
| WCL23812.1 | cytochrome f (chloroplast) [Pinus massoniana] | 14.926 | 7 | 7 |
| AFA51418.1 | extracellular calcium sensing receptor [Pinus massoniana] | 13.155 | 17 | 6 |
| AIZ74323.1 | actin related protein 1 [Pinus massoniana] | 12.518 | 6 | 6 |
| WCL24807.1 | photosystem II 44 kDa protein (chloroplast) [Pinus massoniana] | 8.537 | 6 | 6 |
| WCL24370.1 | photosytem I subunit VII (chloroplast) | 8.045 | 5 | 5 |
| WCL24671.1 | photosystem II protein D1 (chloroplast) [Pinus massoniana] | 6.064 | 4 | 4 |
| WCL25227.1 | photosystem II 47 kDa protein (chloroplast) [Pinus massoniana] | 5.584 | 4 | 4 |
| AIZ74332.1 | beta-tubulin [Pinus massoniana] | 4.894 | 4 | 4 |
| AIZ74331.1 | alpha-tubulin [Pinus massoniana] | 6.451 | 3 | 3 |
| WCL23846.1 | photosystem II protein D2 (chloroplast) [Pinus massoniana] | 4.799 | 3 | 3 |
| ACY66805.1 | chlorophyll a/b-binding protein [Pinus massoniana] | 4.253 | 3 | 3 |
| AHJ86267.1 | glutathione peroxidase [Pinus massoniana] | 5.426 | 14 | 2 |
| AIZ74335.1 | polyubiquitin 3, partial [Pinus massoniana] | 2.894 | 2 | 2 |
| WCL24189.1 | ATP synthase CF1 epsilon subunit (chloroplast) [Pinus massoniana] | 2.562 | 2 | 2 |
| WCL23911.1 | ribosomal protein L2 (chloroplast) [Pinus massoniana] | 4.188 | 1 | 1 |
| AIZ74341.1 | isocitrate dehydrogenase [Pinus massoniana] | 3.581 | 1 | 1 |
| WCL38145.1 | photosystem I P700 chlorophyll a apoprotein A1 (chloroplast) [Pinus massoniana] | 2.016 | 1 | 1 |
| ACV88654.1 | cyclophilin [Pinus massoniana] | 1.319 | 1 | 1 |
| WCL24138.1 | photosystem I P700 chlorophyll a apoprotein A2 (chloroplast) [Pinus massoniana] | 1.117 | 1 | 1 |
| WCL25009.1 | cytochrome b6 (chloroplast) [Pinus massoniana] | 1.06 | 1 | 1 |
| WCL25872.1 | ATP-dependent Clp protease proteolytic subunit (chloroplast) [Pinus massoniana] | 0.863 | 1 | 1 |
| AMR43653.1 | purple acid phosphatase 1 [Pinus massoniana] | 0.861 | 1 | 1 |
| WCL25530.1 | ribosomal protein S11 (chloroplast) [Pinus massoniana] | 0.861 | 1 | 1 |
| AIF75959.1 | putative phosphofructokinase, partial [Pinus massoniana] | 0.842 | 1 | 1 |
| AVP71779.1 | auxin response factor 16 [Pinus massoniana] | 0.763 | 3 | 1 |
| UFA45708.1 | bHLH10 [Pinus massoniana] | 0.684 | 1 | 1 |
| WCL23782.1 | Ycf2 (chloroplast) [Pinus massoniana] | 0.677 | 1 | 1 |
| AHL67654.1 | caffeoyl-CoA 3-O-methyltransferase [Pinus massoniana] | 0.635 | 5 | 1 |
| AIF75747.1 | dehydrin 1 protein, partial [Pinus massoniana] | 0.621 | 5 | 1 |
| WCL25253.1 | hypothetical chloroplast RF68 (chloroplast) [Pinus massoniana] | 0.595 | 1 | 1 |
| UIB01906.1 | 2-C-methyl-D-erythritol 4-phosphate cytidylyltransferase [Pinus massoniana] | 0.584 | 1 | 1 |
| The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
Share and Cite
Xie, W.; Lai, X.; Wu, Y.; Li, Z.; Zhu, J.; Huang, Y.; Zhang, F. Transcription Factor and Protein Regulatory Network of PmACRE1 in Pinus massoniana Response to Pine Wilt Nematode Infection. Plants 2024 , 13 , 2672. https://doi.org/10.3390/plants13192672
Xie W, Lai X, Wu Y, Li Z, Zhu J, Huang Y, Zhang F. Transcription Factor and Protein Regulatory Network of PmACRE1 in Pinus massoniana Response to Pine Wilt Nematode Infection. Plants . 2024; 13(19):2672. https://doi.org/10.3390/plants13192672
Xie, Wanfeng, Xiaolin Lai, Yuxiao Wu, Zheyu Li, Jingwen Zhu, Yu Huang, and Feiping Zhang. 2024. "Transcription Factor and Protein Regulatory Network of PmACRE1 in Pinus massoniana Response to Pine Wilt Nematode Infection" Plants 13, no. 19: 2672. https://doi.org/10.3390/plants13192672
Article Metrics
Article access statistics, supplementary material.
ZIP-Document (ZIP, 3117 KiB)
Further Information
Mdpi initiatives, follow mdpi.
Subscribe to receive issue release notifications and newsletters from MDPI journals
IMAGES
VIDEO
COMMENTS
Transcription in Protein Synthesis. The transcription process is the first step of protein synthesis. This step transfers genetic information from DNA to the ribosomes of the cytoplasm or rough endoplasmic reticulum. Transcription is divided into three phases: initiation, elongation and termination. Transcription within the nucleus, translation ...
It begins with the sequence of amino acids that make up the protein. Instructions for making proteins with the correct sequence of amino acids are encoded in DNA. Figure 6.4.1 6.4. 1: Transcription and translation (Protein synthesis) in a cell. DNA is found in chromosomes.
Learn how DNA makes RNA, which makes proteins, in a simple and illustrated guide. Find out the steps, terms, and challenges of transcription and translation, and how they are regulated.
Messenger RNA (mRNA) molecules carry the coding sequences for protein synthesis and are called transcripts; ribosomal RNA (rRNA) molecules form the core of a cell's ribosomes (the structures in ...
By the end of transcription, mature mRNA has been made. This acts as the messaging system to allow translation and protein synthesis to occur. Within the mature mRNA, is the open reading frame (ORF). This region will be translated into protein. It is translated in blocks of three nucleotides, called codons.
1) Transcription: The First Step of Protein Synthesis. In this process, a single-stranded mRNA molecule is transcribed from a double-stranded DNA molecule. The mRNA thus formed is used as a template for the next step, translation. The three steps of transcription are: initiation, elongation, and termination. i) Initiation.
Proteins are made from a sequence of amino acids rather than nucleotides. Transcription and translation are the two processes that convert a sequence of nucleotides from DNA into a sequence of amino acids to build the desired protein. These two processes are essential for life. They are found in all organisms - eukaryotic and prokaryotic.
5.7 Summary. Protein synthesis is the process in which cells make proteins. It occurs in two stages: transcription and translation. Transcription is the transfer of genetic instructions in DNA to mRNA in the nucleus. It includes three steps: initiation, elongation, and termination.
Transcription is the process by which DNA is copied (transcribed) to mRNA, which carries the information needed for protein synthesis. Transcription takes place in two broad steps. First, pre-messenger RNA is formed, with the involvement of RNA polymerase enzymes. The process relies on Watson-Crick base pairing, and the resultant single strand ...
Transcription requires the DNA double helix to partially unwind in the region of mRNA synthesis. The region of unwinding is called a transcription bubble. The DNA sequence onto which the proteins and enzymes involved in transcription bind to initiate the process is called a promoter. In most cases, promoters exist upstream of the genes they ...
Explain the processes necessary for transcription to begin. Explain how DNA is transcribed to create an mRNA sequence. Describe the role of polymerase in transcription. Recognize that protein synthesis regulation (i.e., changes in gene expression) allow cells to respond to changes in the environment.
The process of translation can be seen as the decoding of instructions for making proteins, involving mRNA in transcription as well as tRNA. The genes in DNA encode protein molecules, which are ...
The transcription process is regulated by a class of proteins called transcription factors, which bind to the gene sequence and either promote or inhibit their transcription. (move Figure 3.35 here). Before the mRNA molecule leaves the nucleus and proceeds to protein synthesis, it is modified in a number of ways.
transcription, the synthesis of RNA from DNA. Genetic information flows from DNA into protein, the substance that gives an organism its form. This flow of information occurs through the sequential processes of transcription (DNA to RNA) and translation (RNA to protein). Transcription occurs when there is a need for a particular gene product at ...
Steps of Transcription. The process of Transcription takes place in the cytoplasm in prokaryotes and in nucleus in eukaryotes. It uses DNA as a template to make an RNA (mRNA) molecule. During transcription, a strand of mRNA is made that is complementary to a strand of DNA. Figure 1 shows how this occurs.
Transcription and RNA processing are followed by translation, the synthesis of proteins as directed by mRNA templates. Proteins are the active players in most cell processes, implementing the myriad tasks that are directed by the information encoded in genomic DNA. Protein synthesis is thus the final stage of gene expression. However, the translation of mRNA is only the first step in the ...
Past Papers. Edexcel. Spanish. Past Papers. CIE. Spanish Language & Literature. Past Papers. Revision notes on 4.2.3 Transcription for the AQA A Level Biology syllabus, written by the Biology experts at Save My Exams.
Course: Biology archive > Unit 16. Lesson 2: Transcription. DNA replication and RNA transcription and translation. Transcription and mRNA processing. Molecular structure of RNA. Overview of transcription. Stages of transcription. Eukaryotic pre-mRNA processing. Transcription.
We will learn about protein synthesis regulation in a later chapter. Protein synthesis consists of two main processes: transcription and translation. During the process of transcription —which occurs in the nucleus—an mRNA molecule is created by reading the DNA. Note that DNA never "becomes" RNA; rather, the DNA is "read" to make an ...
In both bacteria and archaea, before transcriptional termination occurs, each protein-encoding transcript is already being used to begin synthesis of numerous copies of the encoded polypeptide(s) because the processes of transcription and translation can occur concurrently, forming polyribosomes (Figure 11.13). The reason why transcription and ...
This process of protein synthesis occurs in two stages - transcription and translation. Transcription When a gene is to be expressed, the base sequence of DNA is copied or transcribed into mRNA ...
Learn how DNA codes for proteins in this biology video tutorial. Explore the processes of transcription and translation with clear explanations and examples.
If you're seeing this message, it means we're having trouble loading external resources on our website. If you're behind a web filter, please make sure that the domains *.kastatic.org and *.kasandbox.org are unblocked.
Ribosomes. Even before an mRNA is translated, a cell must invest energy to build each of its ribosomes. In E. coli, there are between 10,000 and 70,000 ribosomes present in each cell at any given time.A ribosome is a complex macromolecule composed of structural and catalytic rRNAs, and many distinct polypeptides. In eukaryotes, the nucleolus is completely specialized for the synthesis and ...
Transcription is the process of converting DNA to RNA in the cell nucleus. This biological process involves RNA polymerase reading the DNA template strand in a 3' to 5' direction, synthesizing complementary RNA in a 5' to 3' direction.Transcription is essential for gene expression and protein production. Understanding what transcription is helps explain how genetic information is transferred ...
D 1.2 Protein synthesis D1.2.1 Transcription as the synthesis of RNA using a DNA template D1.2.2 Role of hydrogen bonding and complementary base pairing in transcription. This process of protein synthesis occurs in two stages: Transcription - DNA is transcribed and an mRNA molecule is produced mRNA is a single stranded RNA molecule that transfers the information in DNA from the nucleus into ...
By exploring the transcription and translation levels of HpLHY in different HR, it was found that the expression and protein levels of HpLHY in OE lines were increased, while KO lines showed the opposite results (Fig. 5, B and C). The OE HR lines significantly reduced the content of melatonin, while the KO showed an increase in melatonin content.
The protein at 100 μM was dropped into the 1000 μM peptide segment for 19 consecutive drops, and the resulting titration curve was drawn using the 'one set of binding sites' model and the Origin 7.0 program. The protein concentration was determined by UV absorption at 280 nm. The peptide concentration was measured by nanodrop.
Pine wilt disease, caused by Bursaphelenchus xylophilus, is a highly destructive and contagious forest affliction. Often termed the "cancer" of pine trees, it severely impacts the growth of Masson pine (Pinus massoniana). Previous studies have demonstrated that ectopic expression of the PmACRE1 gene from P. massoniana in Arabidopsis thaliana notably enhances resistance to pine wilt ...