- How it works


Hypothesis Testing – A Complete Guide with Examples
Published by Alvin Nicolas at August 14th, 2021 , Revised On October 26, 2023
In statistics, hypothesis testing is a critical tool. It allows us to make informed decisions about populations based on sample data. Whether you are a researcher trying to prove a scientific point, a marketer analysing A/B test results, or a manufacturer ensuring quality control, hypothesis testing plays a pivotal role. This guide aims to introduce you to the concept and walk you through real-world examples.
What is a Hypothesis and a Hypothesis Testing?
A hypothesis is considered a belief or assumption that has to be accepted, rejected, proved or disproved. In contrast, a research hypothesis is a research question for a researcher that has to be proven correct or incorrect through investigation.
What is Hypothesis Testing?
Hypothesis testing is a scientific method used for making a decision and drawing conclusions by using a statistical approach. It is used to suggest new ideas by testing theories to know whether or not the sample data supports research. A research hypothesis is a predictive statement that has to be tested using scientific methods that join an independent variable to a dependent variable.
Example: The academic performance of student A is better than student B
Characteristics of the Hypothesis to be Tested
A hypothesis should be:
- Clear and precise
- Capable of being tested
- Able to relate to a variable
- Stated in simple terms
- Consistent with known facts
- Limited in scope and specific
- Tested in a limited timeframe
- Explain the facts in detail
What is a Null Hypothesis and Alternative Hypothesis?
A null hypothesis is a hypothesis when there is no significant relationship between the dependent and the participants’ independent variables .
In simple words, it’s a hypothesis that has been put forth but hasn’t been proved as yet. A researcher aims to disprove the theory. The abbreviation “Ho” is used to denote a null hypothesis.
If you want to compare two methods and assume that both methods are equally good, this assumption is considered the null hypothesis.
Example: In an automobile trial, you feel that the new vehicle’s mileage is similar to the previous model of the car, on average. You can write it as: Ho: there is no difference between the mileage of both vehicles. If your findings don’t support your hypothesis and you get opposite results, this outcome will be considered an alternative hypothesis.
If you assume that one method is better than another method, then it’s considered an alternative hypothesis. The alternative hypothesis is the theory that a researcher seeks to prove and is typically denoted by H1 or HA.
If you support a null hypothesis, it means you’re not supporting the alternative hypothesis. Similarly, if you reject a null hypothesis, it means you are recommending the alternative hypothesis.
Example: In an automobile trial, you feel that the new vehicle’s mileage is better than the previous model of the vehicle. You can write it as; Ha: the two vehicles have different mileage. On average/ the fuel consumption of the new vehicle model is better than the previous model.
If a null hypothesis is rejected during the hypothesis test, even if it’s true, then it is considered as a type-I error. On the other hand, if you don’t dismiss a hypothesis, even if it’s false because you could not identify its falseness, it’s considered a type-II error.
Hire an Expert Researcher
Orders completed by our expert writers are
- Formally drafted in academic style
- 100% Plagiarism free & 100% Confidential
- Never resold
- Include unlimited free revisions
- Completed to match exact client requirements

How to Conduct Hypothesis Testing?
Here is a step-by-step guide on how to conduct hypothesis testing.
Step 1: State the Null and Alternative Hypothesis
Once you develop a research hypothesis, it’s important to state it is as a Null hypothesis (Ho) and an Alternative hypothesis (Ha) to test it statistically.
A null hypothesis is a preferred choice as it provides the opportunity to test the theory. In contrast, you can accept the alternative hypothesis when the null hypothesis has been rejected.
Example: You want to identify a relationship between obesity of men and women and the modern living style. You develop a hypothesis that women, on average, gain weight quickly compared to men. Then you write it as: Ho: Women, on average, don’t gain weight quickly compared to men. Ha: Women, on average, gain weight quickly compared to men.
Step 2: Data Collection
Hypothesis testing follows the statistical method, and statistics are all about data. It’s challenging to gather complete information about a specific population you want to study. You need to gather the data obtained through a large number of samples from a specific population.
Example: Suppose you want to test the difference in the rate of obesity between men and women. You should include an equal number of men and women in your sample. Then investigate various aspects such as their lifestyle, eating patterns and profession, and any other variables that may influence average weight. You should also determine your study’s scope, whether it applies to a specific group of population or worldwide population. You can use available information from various places, countries, and regions.
Step 3: Select Appropriate Statistical Test
There are many types of statistical tests , but we discuss the most two common types below, such as One-sided and two-sided tests.
Note: Your choice of the type of test depends on the purpose of your study
One-sided Test
In the one-sided test, the values of rejecting a null hypothesis are located in one tail of the probability distribution. The set of values is less or higher than the critical value of the test. It is also called a one-tailed test of significance.
Example: If you want to test that all mangoes in a basket are ripe. You can write it as: Ho: All mangoes in the basket, on average, are ripe. If you find all ripe mangoes in the basket, the null hypothesis you developed will be true.
Two-sided Test
In the two-sided test, the values of rejecting a null hypothesis are located on both tails of the probability distribution. The set of values is less or higher than the first critical value of the test and higher than the second critical value test. It is also called a two-tailed test of significance.
Example: Nothing can be explicitly said whether all mangoes are ripe in the basket. If you reject the null hypothesis (Ho: All mangoes in the basket, on average, are ripe), then it means all mangoes in the basket are not likely to be ripe. A few mangoes could be raw as well.
Get statistical analysis help at an affordable price
- An expert statistician will complete your work
- Rigorous quality checks
- Confidentiality and reliability
- Any statistical software of your choice
- Free Plagiarism Report

Step 4: Select the Level of Significance
When you reject a null hypothesis, even if it’s true during a statistical hypothesis, it is considered the significance level . It is the probability of a type one error. The significance should be as minimum as possible to avoid the type-I error, which is considered severe and should be avoided.
If the significance level is minimum, then it prevents the researchers from false claims.
The significance level is denoted by P, and it has given the value of 0.05 (P=0.05)
If the P-Value is less than 0.05, then the difference will be significant. If the P-value is higher than 0.05, then the difference is non-significant.
Example: Suppose you apply a one-sided test to test whether women gain weight quickly compared to men. You get to know about the average weight between men and women and the factors promoting weight gain.
Step 5: Find out Whether the Null Hypothesis is Rejected or Supported
After conducting a statistical test, you should identify whether your null hypothesis is rejected or accepted based on the test results. It would help if you observed the P-value for this.
Example: If you find the P-value of your test is less than 0.5/5%, then you need to reject your null hypothesis (Ho: Women, on average, don’t gain weight quickly compared to men). On the other hand, if a null hypothesis is rejected, then it means the alternative hypothesis might be true (Ha: Women, on average, gain weight quickly compared to men. If you find your test’s P-value is above 0.5/5%, then it means your null hypothesis is true.
Step 6: Present the Outcomes of your Study
The final step is to present the outcomes of your study . You need to ensure whether you have met the objectives of your research or not.
In the discussion section and conclusion , you can present your findings by using supporting evidence and conclude whether your null hypothesis was rejected or supported.
In the result section, you can summarise your study’s outcomes, including the average difference and P-value of the two groups.
If we talk about the findings, our study your results will be as follows:
Example: In the study of identifying whether women gain weight quickly compared to men, we found the P-value is less than 0.5. Hence, we can reject the null hypothesis (Ho: Women, on average, don’t gain weight quickly than men) and conclude that women may likely gain weight quickly than men.
Did you know in your academic paper you should not mention whether you have accepted or rejected the null hypothesis?
Always remember that you either conclude to reject Ho in favor of Haor do not reject Ho . It would help if you never rejected Ha or even accept Ha .
Suppose your null hypothesis is rejected in the hypothesis testing. If you conclude reject Ho in favor of Haor do not reject Ho, then it doesn’t mean that the null hypothesis is true. It only means that there is a lack of evidence against Ho in favour of Ha. If your null hypothesis is not true, then the alternative hypothesis is likely to be true.
Example: We found that the P-value is less than 0.5. Hence, we can conclude reject Ho in favour of Ha (Ho: Women, on average, don’t gain weight quickly than men) reject Ho in favour of Ha. However, rejected in favour of Ha means (Ha: women may likely to gain weight quickly than men)
Frequently Asked Questions
What are the 3 types of hypothesis test.
The 3 types of hypothesis tests are:
- One-Sample Test : Compare sample data to a known population value.
- Two-Sample Test : Compare means between two sample groups.
- ANOVA : Analyze variance among multiple groups to determine significant differences.
What is a hypothesis?
A hypothesis is a proposed explanation or prediction about a phenomenon, often based on observations. It serves as a starting point for research or experimentation, providing a testable statement that can either be supported or refuted through data and analysis. In essence, it’s an educated guess that drives scientific inquiry.
What are null hypothesis?
A null hypothesis (often denoted as H0) suggests that there is no effect or difference in a study or experiment. It represents a default position or status quo. Statistical tests evaluate data to determine if there’s enough evidence to reject this null hypothesis.
What is the probability value?
The probability value, or p-value, is a measure used in statistics to determine the significance of an observed effect. It indicates the probability of obtaining the observed results, or more extreme, if the null hypothesis were true. A small p-value (typically <0.05) suggests evidence against the null hypothesis, warranting its rejection.
What is p value?
The p-value is a fundamental concept in statistical hypothesis testing. It represents the probability of observing a test statistic as extreme, or more so, than the one calculated from sample data, assuming the null hypothesis is true. A low p-value suggests evidence against the null, possibly justifying its rejection.
What is a t test?
A t-test is a statistical test used to compare the means of two groups. It determines if observed differences between the groups are statistically significant or if they likely occurred by chance. Commonly applied in research, there are different t-tests, including independent, paired, and one-sample, tailored to various data scenarios.
When to reject null hypothesis?
Reject the null hypothesis when the test statistic falls into a predefined rejection region or when the p-value is less than the chosen significance level (commonly 0.05). This suggests that the observed data is unlikely under the null hypothesis, indicating evidence for the alternative hypothesis. Always consider the study’s context.
You May Also Like
This article presents the key advantages and disadvantages of secondary research so you can select the most appropriate research approach for your study.
Baffled by the concept of reliability and validity? Reliability refers to the consistency of measurement. Validity refers to the accuracy of measurement.
USEFUL LINKS
LEARNING RESOURCES

COMPANY DETAILS

- How It Works
Have a language expert improve your writing
Run a free plagiarism check in 10 minutes, generate accurate citations for free.
- Knowledge Base
Methodology
- How to Write a Strong Hypothesis | Steps & Examples
How to Write a Strong Hypothesis | Steps & Examples
Published on May 6, 2022 by Shona McCombes . Revised on November 20, 2023.
A hypothesis is a statement that can be tested by scientific research. If you want to test a relationship between two or more variables, you need to write hypotheses before you start your experiment or data collection .
Example: Hypothesis
Daily apple consumption leads to fewer doctor’s visits.
Table of contents
What is a hypothesis, developing a hypothesis (with example), hypothesis examples, other interesting articles, frequently asked questions about writing hypotheses.
A hypothesis states your predictions about what your research will find. It is a tentative answer to your research question that has not yet been tested. For some research projects, you might have to write several hypotheses that address different aspects of your research question.
A hypothesis is not just a guess – it should be based on existing theories and knowledge. It also has to be testable, which means you can support or refute it through scientific research methods (such as experiments, observations and statistical analysis of data).
Variables in hypotheses
Hypotheses propose a relationship between two or more types of variables .
- An independent variable is something the researcher changes or controls.
- A dependent variable is something the researcher observes and measures.
If there are any control variables , extraneous variables , or confounding variables , be sure to jot those down as you go to minimize the chances that research bias will affect your results.
In this example, the independent variable is exposure to the sun – the assumed cause . The dependent variable is the level of happiness – the assumed effect .
Here's why students love Scribbr's proofreading services
Discover proofreading & editing
Step 1. Ask a question
Writing a hypothesis begins with a research question that you want to answer. The question should be focused, specific, and researchable within the constraints of your project.
Step 2. Do some preliminary research
Your initial answer to the question should be based on what is already known about the topic. Look for theories and previous studies to help you form educated assumptions about what your research will find.
At this stage, you might construct a conceptual framework to ensure that you’re embarking on a relevant topic . This can also help you identify which variables you will study and what you think the relationships are between them. Sometimes, you’ll have to operationalize more complex constructs.
Step 3. Formulate your hypothesis
Now you should have some idea of what you expect to find. Write your initial answer to the question in a clear, concise sentence.
4. Refine your hypothesis
You need to make sure your hypothesis is specific and testable. There are various ways of phrasing a hypothesis, but all the terms you use should have clear definitions, and the hypothesis should contain:
- The relevant variables
- The specific group being studied
- The predicted outcome of the experiment or analysis
5. Phrase your hypothesis in three ways
To identify the variables, you can write a simple prediction in if…then form. The first part of the sentence states the independent variable and the second part states the dependent variable.
In academic research, hypotheses are more commonly phrased in terms of correlations or effects, where you directly state the predicted relationship between variables.
If you are comparing two groups, the hypothesis can state what difference you expect to find between them.
6. Write a null hypothesis
If your research involves statistical hypothesis testing , you will also have to write a null hypothesis . The null hypothesis is the default position that there is no association between the variables. The null hypothesis is written as H 0 , while the alternative hypothesis is H 1 or H a .
- H 0 : The number of lectures attended by first-year students has no effect on their final exam scores.
- H 1 : The number of lectures attended by first-year students has a positive effect on their final exam scores.
| Research question | Hypothesis | Null hypothesis |
|---|---|---|
| What are the health benefits of eating an apple a day? | Increasing apple consumption in over-60s will result in decreasing frequency of doctor’s visits. | Increasing apple consumption in over-60s will have no effect on frequency of doctor’s visits. |
| Which airlines have the most delays? | Low-cost airlines are more likely to have delays than premium airlines. | Low-cost and premium airlines are equally likely to have delays. |
| Can flexible work arrangements improve job satisfaction? | Employees who have flexible working hours will report greater job satisfaction than employees who work fixed hours. | There is no relationship between working hour flexibility and job satisfaction. |
| How effective is high school sex education at reducing teen pregnancies? | Teenagers who received sex education lessons throughout high school will have lower rates of unplanned pregnancy teenagers who did not receive any sex education. | High school sex education has no effect on teen pregnancy rates. |
| What effect does daily use of social media have on the attention span of under-16s? | There is a negative between time spent on social media and attention span in under-16s. | There is no relationship between social media use and attention span in under-16s. |
If you want to know more about the research process , methodology , research bias , or statistics , make sure to check out some of our other articles with explanations and examples.
- Sampling methods
- Simple random sampling
- Stratified sampling
- Cluster sampling
- Likert scales
- Reproducibility
Statistics
- Null hypothesis
- Statistical power
- Probability distribution
- Effect size
- Poisson distribution
Research bias
- Optimism bias
- Cognitive bias
- Implicit bias
- Hawthorne effect
- Anchoring bias
- Explicit bias
Prevent plagiarism. Run a free check.
A hypothesis is not just a guess — it should be based on existing theories and knowledge. It also has to be testable, which means you can support or refute it through scientific research methods (such as experiments, observations and statistical analysis of data).
Null and alternative hypotheses are used in statistical hypothesis testing . The null hypothesis of a test always predicts no effect or no relationship between variables, while the alternative hypothesis states your research prediction of an effect or relationship.
Hypothesis testing is a formal procedure for investigating our ideas about the world using statistics. It is used by scientists to test specific predictions, called hypotheses , by calculating how likely it is that a pattern or relationship between variables could have arisen by chance.
Cite this Scribbr article
If you want to cite this source, you can copy and paste the citation or click the “Cite this Scribbr article” button to automatically add the citation to our free Citation Generator.
McCombes, S. (2023, November 20). How to Write a Strong Hypothesis | Steps & Examples. Scribbr. Retrieved September 4, 2024, from https://www.scribbr.com/methodology/hypothesis/
Is this article helpful?

Shona McCombes
Other students also liked, construct validity | definition, types, & examples, what is a conceptual framework | tips & examples, operationalization | a guide with examples, pros & cons, "i thought ai proofreading was useless but..".
I've been using Scribbr for years now and I know it's a service that won't disappoint. It does a good job spotting mistakes”
- Skip to secondary menu
- Skip to main content
- Skip to primary sidebar
Statistics By Jim
Making statistics intuitive
Statistical Hypothesis Testing Overview
By Jim Frost 59 Comments
In this blog post, I explain why you need to use statistical hypothesis testing and help you navigate the essential terminology. Hypothesis testing is a crucial procedure to perform when you want to make inferences about a population using a random sample. These inferences include estimating population properties such as the mean, differences between means, proportions, and the relationships between variables.
This post provides an overview of statistical hypothesis testing. If you need to perform hypothesis tests, consider getting my book, Hypothesis Testing: An Intuitive Guide .
Why You Should Perform Statistical Hypothesis Testing

Hypothesis testing is a form of inferential statistics that allows us to draw conclusions about an entire population based on a representative sample. You gain tremendous benefits by working with a sample. In most cases, it is simply impossible to observe the entire population to understand its properties. The only alternative is to collect a random sample and then use statistics to analyze it.
While samples are much more practical and less expensive to work with, there are trade-offs. When you estimate the properties of a population from a sample, the sample statistics are unlikely to equal the actual population value exactly. For instance, your sample mean is unlikely to equal the population mean. The difference between the sample statistic and the population value is the sample error.
Differences that researchers observe in samples might be due to sampling error rather than representing a true effect at the population level. If sampling error causes the observed difference, the next time someone performs the same experiment the results might be different. Hypothesis testing incorporates estimates of the sampling error to help you make the correct decision. Learn more about Sampling Error .
For example, if you are studying the proportion of defects produced by two manufacturing methods, any difference you observe between the two sample proportions might be sample error rather than a true difference. If the difference does not exist at the population level, you won’t obtain the benefits that you expect based on the sample statistics. That can be a costly mistake!
Let’s cover some basic hypothesis testing terms that you need to know.
Background information : Difference between Descriptive and Inferential Statistics and Populations, Parameters, and Samples in Inferential Statistics
Hypothesis Testing
Hypothesis testing is a statistical analysis that uses sample data to assess two mutually exclusive theories about the properties of a population. Statisticians call these theories the null hypothesis and the alternative hypothesis. A hypothesis test assesses your sample statistic and factors in an estimate of the sample error to determine which hypothesis the data support.
When you can reject the null hypothesis, the results are statistically significant, and your data support the theory that an effect exists at the population level.
The effect is the difference between the population value and the null hypothesis value. The effect is also known as population effect or the difference. For example, the mean difference between the health outcome for a treatment group and a control group is the effect.
Typically, you do not know the size of the actual effect. However, you can use a hypothesis test to help you determine whether an effect exists and to estimate its size. Hypothesis tests convert your sample effect into a test statistic, which it evaluates for statistical significance. Learn more about Test Statistics .
An effect can be statistically significant, but that doesn’t necessarily indicate that it is important in a real-world, practical sense. For more information, read my post about Statistical vs. Practical Significance .
Null Hypothesis
The null hypothesis is one of two mutually exclusive theories about the properties of the population in hypothesis testing. Typically, the null hypothesis states that there is no effect (i.e., the effect size equals zero). The null is often signified by H 0 .
In all hypothesis testing, the researchers are testing an effect of some sort. The effect can be the effectiveness of a new vaccination, the durability of a new product, the proportion of defect in a manufacturing process, and so on. There is some benefit or difference that the researchers hope to identify.
However, it’s possible that there is no effect or no difference between the experimental groups. In statistics, we call this lack of an effect the null hypothesis. Therefore, if you can reject the null, you can favor the alternative hypothesis, which states that the effect exists (doesn’t equal zero) at the population level.
You can think of the null as the default theory that requires sufficiently strong evidence against in order to reject it.
For example, in a 2-sample t-test, the null often states that the difference between the two means equals zero.
When you can reject the null hypothesis, your results are statistically significant. Learn more about Statistical Significance: Definition & Meaning .
Related post : Understanding the Null Hypothesis in More Detail
Alternative Hypothesis
The alternative hypothesis is the other theory about the properties of the population in hypothesis testing. Typically, the alternative hypothesis states that a population parameter does not equal the null hypothesis value. In other words, there is a non-zero effect. If your sample contains sufficient evidence, you can reject the null and favor the alternative hypothesis. The alternative is often identified with H 1 or H A .
For example, in a 2-sample t-test, the alternative often states that the difference between the two means does not equal zero.
You can specify either a one- or two-tailed alternative hypothesis:
If you perform a two-tailed hypothesis test, the alternative states that the population parameter does not equal the null value. For example, when the alternative hypothesis is H A : μ ≠ 0, the test can detect differences both greater than and less than the null value.
A one-tailed alternative has more power to detect an effect but it can test for a difference in only one direction. For example, H A : μ > 0 can only test for differences that are greater than zero.
Related posts : Understanding T-tests and One-Tailed and Two-Tailed Hypothesis Tests Explained

P-values are the probability that you would obtain the effect observed in your sample, or larger, if the null hypothesis is correct. In simpler terms, p-values tell you how strongly your sample data contradict the null. Lower p-values represent stronger evidence against the null. You use P-values in conjunction with the significance level to determine whether your data favor the null or alternative hypothesis.
Related post : Interpreting P-values Correctly
Significance Level (Alpha)

For instance, a significance level of 0.05 signifies a 5% risk of deciding that an effect exists when it does not exist.
Use p-values and significance levels together to help you determine which hypothesis the data support. If the p-value is less than your significance level, you can reject the null and conclude that the effect is statistically significant. In other words, the evidence in your sample is strong enough to be able to reject the null hypothesis at the population level.
Related posts : Graphical Approach to Significance Levels and P-values and Conceptual Approach to Understanding Significance Levels
Types of Errors in Hypothesis Testing
Statistical hypothesis tests are not 100% accurate because they use a random sample to draw conclusions about entire populations. There are two types of errors related to drawing an incorrect conclusion.
- False positives: You reject a null that is true. Statisticians call this a Type I error . The Type I error rate equals your significance level or alpha (α).
- False negatives: You fail to reject a null that is false. Statisticians call this a Type II error. Generally, you do not know the Type II error rate. However, it is a larger risk when you have a small sample size , noisy data, or a small effect size. The type II error rate is also known as beta (β).
Statistical power is the probability that a hypothesis test correctly infers that a sample effect exists in the population. In other words, the test correctly rejects a false null hypothesis. Consequently, power is inversely related to a Type II error. Power = 1 – β. Learn more about Power in Statistics .
Related posts : Types of Errors in Hypothesis Testing and Estimating a Good Sample Size for Your Study Using Power Analysis
Which Type of Hypothesis Test is Right for You?
There are many different types of procedures you can use. The correct choice depends on your research goals and the data you collect. Do you need to understand the mean or the differences between means? Or, perhaps you need to assess proportions. You can even use hypothesis testing to determine whether the relationships between variables are statistically significant.
To choose the proper statistical procedure, you’ll need to assess your study objectives and collect the correct type of data . This background research is necessary before you begin a study.
Related Post : Hypothesis Tests for Continuous, Binary, and Count Data
Statistical tests are crucial when you want to use sample data to make conclusions about a population because these tests account for sample error. Using significance levels and p-values to determine when to reject the null hypothesis improves the probability that you will draw the correct conclusion.
To see an alternative approach to these traditional hypothesis testing methods, learn about bootstrapping in statistics !
If you want to see examples of hypothesis testing in action, I recommend the following posts that I have written:
- How Effective Are Flu Shots? This example shows how you can use statistics to test proportions.
- Fatality Rates in Star Trek . This example shows how to use hypothesis testing with categorical data.
- Busting Myths About the Battle of the Sexes . A fun example based on a Mythbusters episode that assess continuous data using several different tests.
- Are Yawns Contagious? Another fun example inspired by a Mythbusters episode.
Share this:

Reader Interactions

January 14, 2024 at 8:43 am
Hello professor Jim, how are you doing! Pls. What are the properties of a population and their examples? Thanks for your time and understanding.

January 14, 2024 at 12:57 pm
Please read my post about Populations vs. Samples for more information and examples.
Also, please note there is a search bar in the upper-right margin of my website. Use that to search for topics.

July 5, 2023 at 7:05 am
Hello, I have a question as I read your post. You say in p-values section
“P-values are the probability that you would obtain the effect observed in your sample, or larger, if the null hypothesis is correct. In simpler terms, p-values tell you how strongly your sample data contradict the null. Lower p-values represent stronger evidence against the null.”
But according to your definition of effect, the null states that an effect does not exist, correct? So what I assume you want to say is that “P-values are the probability that you would obtain the effect observed in your sample, or larger, if the null hypothesis is **incorrect**.”
July 6, 2023 at 5:18 am
Hi Shrinivas,
The correct definition of p-value is that it is a probability that exists in the context of a true null hypothesis. So, the quotation is correct in stating “if the null hypothesis is correct.”
Essentially, the p-value tells you the likelihood of your observed results (or more extreme) if the null hypothesis is true. It gives you an idea of whether your results are surprising or unusual if there is no effect.
Hence, with sufficiently low p-values, you reject the null hypothesis because it’s telling you that your sample results were unlikely to have occurred if there was no effect in the population.
I hope that helps make it more clear. If not, let me know I’ll attempt to clarify!

May 8, 2023 at 12:47 am
Thanks a lot Ny best regards
May 7, 2023 at 11:15 pm
Hi Jim Can you tell me something about size effect? Thanks
May 8, 2023 at 12:29 am
Here’s a post that I’ve written about Effect Sizes that will hopefully tell you what you need to know. Please read that. Then, if you have any more specific questions about effect sizes, please post them there. Thanks!

January 7, 2023 at 4:19 pm
Hi Jim, I have only read two pages so far but I am really amazed because in few paragraphs you made me clearly understand the concepts of months of courses I received in biostatistics! Thanks so much for this work you have done it helps a lot!
January 10, 2023 at 3:25 pm
Thanks so much!

June 17, 2021 at 1:45 pm
Can you help in the following question: Rocinante36 is priced at ₹7 lakh and has been designed to deliver a mileage of 22 km/litre and a top speed of 140 km/hr. Formulate the null and alternative hypotheses for mileage and top speed to check whether the new models are performing as per the desired design specifications.

April 19, 2021 at 1:51 pm
Its indeed great to read your work statistics.
I have a doubt regarding the one sample t-test. So as per your book on hypothesis testing with reference to page no 45, you have mentioned the difference between “the sample mean and the hypothesised mean is statistically significant”. So as per my understanding it should be quoted like “the difference between the population mean and the hypothesised mean is statistically significant”. The catch here is the hypothesised mean represents the sample mean.
Please help me understand this.
Regards Rajat
April 19, 2021 at 3:46 pm
Thanks for buying my book. I’m so glad it’s been helpful!
The test is performed on the sample but the results apply to the population. Hence, if the difference between the sample mean (observed in your study) and the hypothesized mean is statistically significant, that suggests that population does not equal the hypothesized mean.
For one sample tests, the hypothesized mean is not the sample mean. It is a mean that you want to use for the test value. It usually represents a value that is important to your research. In other words, it’s a value that you pick for some theoretical/practical reasons. You pick it because you want to determine whether the population mean is different from that particular value.
I hope that helps!

November 5, 2020 at 6:24 am
Jim, you are such a magnificent statistician/economist/econometrician/data scientist etc whatever profession. Your work inspires and simplifies the lives of so many researchers around the world. I truly admire you and your work. I will buy a copy of each book you have on statistics or econometrics. Keep doing the good work. Remain ever blessed
November 6, 2020 at 9:47 pm
Hi Renatus,
Thanks so much for you very kind comments. You made my day!! I’m so glad that my website has been helpful. And, thanks so much for supporting my books! 🙂

November 2, 2020 at 9:32 pm
Hi Jim, I hope you are aware of 2019 American Statistical Association’s official statement on Statistical Significance: https://www.tandfonline.com/doi/full/10.1080/00031305.2019.1583913 In case you do not bother reading the full article, may I quote you the core message here: “We conclude, based on our review of the articles in this special issue and the broader literature, that it is time to stop using the term “statistically significant” entirely. Nor should variants such as “significantly different,” “p < 0.05,” and “nonsignificant” survive, whether expressed in words, by asterisks in a table, or in some other way."
With best wishes,
November 3, 2020 at 2:09 am
I’m definitely aware of the debate surrounding how to use p-values most effectively. However, I need to correct you on one point. The link you provide is NOT a statement by the American Statistical Association. It is an editorial by several authors.
There is considerable debate over this issue. There are problems with p-values. However, as the authors state themselves, much of the problem is over people’s mindsets about how to use p-values and their incorrect interpretations about what statistical significance does and does not mean.
If you were to read my website more thoroughly, you’d be aware that I share many of their concerns and I address them in multiple posts. One of the authors’ key points is the need to be thoughtful and conduct thoughtful research and analysis. I emphasize this aspect in multiple posts on this topic. I’ll ask you to read the following three because they all address some of the authors’ concerns and suggestions. But you might run across others to read as well.
Five Tips for Using P-values to Avoid Being Misled How to Interpret P-values Correctly P-values and the Reproducibility of Experimental Results

September 24, 2020 at 11:52 pm
HI Jim, i just want you to know that you made explanation for Statistics so simple! I should say lesser and fewer words that reduce the complexity. All the best! 🙂
September 25, 2020 at 1:03 am
Thanks, Rene! Your kind words mean a lot to me! I’m so glad it has been helpful!

September 23, 2020 at 2:21 am
Honestly, I never understood stats during my entire M.Ed course and was another nightmare for me. But how easily you have explained each concept, I have understood stats way beyond my imagination. Thank you so much for helping ignorant research scholars like us. Looking forward to get hardcopy of your book. Kindly tell is it available through flipkart?
September 24, 2020 at 11:14 pm
I’m so happy to hear that my website has been helpful!
I checked on flipkart and it appears like my books are not available there. I’m never exactly sure where they’re available due to the vagaries of different distribution channels. They are available on Amazon in India.
Introduction to Statistics: An Intuitive Guide (Amazon IN) Hypothesis Testing: An Intuitive Guide (Amazon IN)

July 26, 2020 at 11:57 am
Dear Jim I am a teacher from India . I don’t have any background in statistics, and still I should tell that in a single read I can follow your explanations . I take my entire biostatistics class for botany graduates with your explanations. Thanks a lot. May I know how I can avail your books in India
July 28, 2020 at 12:31 am
Right now my books are only available as ebooks from my website. However, soon I’ll have some exciting news about other ways to obtain it. Stay tuned! I’ll announce it on my email list. If you’re not already on it, you can sign up using the form that is in the right margin of my website.

June 22, 2020 at 2:02 pm
Also can you please let me if this book covers topics like EDA and principal component analysis?
June 22, 2020 at 2:07 pm
This book doesn’t cover principal components analysis. Although, I wouldn’t really classify that as a hypothesis test. In the future, I might write a multivariate analysis book that would cover this and others. But, that’s well down the road.
My Introduction to Statistics covers EDA. That’s the largely graphical look at your data that you often do prior to hypothesis testing. The Introduction book perfectly leads right into the Hypothesis Testing book.
June 22, 2020 at 1:45 pm
Thanks for the detailed explanation. It does clear my doubts. I saw that your book related to hypothesis testing has the topics that I am studying currently. I am looking forward to purchasing it.
Regards, Take Care
June 19, 2020 at 1:03 pm
For this particular article I did not understand a couple of statements and it would great if you could help: 1)”If sample error causes the observed difference, the next time someone performs the same experiment the results might be different.” 2)”If the difference does not exist at the population level, you won’t obtain the benefits that you expect based on the sample statistics.”
I discovered your articles by chance and now I keep coming back to read & understand statistical concepts. These articles are very informative & easy to digest. Thanks for the simplifying things.
June 20, 2020 at 9:53 pm
I’m so happy to hear that you’ve found my website to be helpful!
To answer your questions, keep in mind that a central tenant of inferential statistics is that the random sample that a study drew was only one of an infinite number of possible it could’ve drawn. Each random sample produces different results. Most results will cluster around the population value assuming they used good methodology. However, random sampling error always exists and makes it so that population estimates from a sample almost never exactly equal the correct population value.
So, imagine that we’re studying a medication and comparing the treatment and control groups. Suppose that the medicine is truly not effect and that the population difference between the treatment and control group is zero (i.e., no difference.) Despite the true difference being zero, most sample estimates will show some degree of either a positive or negative effect thanks to random sampling error. So, just because a study has an observed difference does not mean that a difference exists at the population level. So, on to your questions:
1. If the observed difference is just random error, then it makes sense that if you collected another random sample, the difference could change. It could change from negative to positive, positive to negative, more extreme, less extreme, etc. However, if the difference exists at the population level, most random samples drawn from the population will reflect that difference. If the medicine has an effect, most random samples will reflect that fact and not bounce around on both sides of zero as much.
2. This is closely related to the previous answer. If there is no difference at the population level, but say you approve the medicine because of the observed effects in a sample. Even though your random sample showed an effect (which was really random error), that effect doesn’t exist. So, when you start using it on a larger scale, people won’t benefit from the medicine. That’s why it’s important to separate out what is easily explained by random error versus what is not easily explained by it.
I think reading my post about how hypothesis tests work will help clarify this process. Also, in about 24 hours (as I write this), I’ll be releasing my new ebook about Hypothesis Testing!

May 29, 2020 at 5:23 am
Hi Jim, I really enjoy your blog. Can you please link me on your blog where you discuss about Subgroup analysis and how it is done? I need to use non parametric and parametric statistical methods for my work and also do subgroup analysis in order to identify potential groups of patients that may benefit more from using a treatment than other groups.
May 29, 2020 at 2:12 pm
Hi, I don’t have a specific article about subgroup analysis. However, subgroup analysis is just the dividing up of a larger sample into subgroups and then analyzing those subgroups separately. You can use the various analyses I write about on the subgroups.
Alternatively, you can include the subgroups in regression analysis as an indicator variable and include that variable as a main effect and an interaction effect to see how the relationships vary by subgroup without needing to subdivide your data. I write about that approach in my article about comparing regression lines . This approach is my preferred approach when possible.

April 19, 2020 at 7:58 am
sir is confidence interval is a part of estimation?

April 17, 2020 at 3:36 pm
Sir can u plz briefly explain alternatives of hypothesis testing? I m unable to find the answer
April 18, 2020 at 1:22 am
Assuming you want to draw conclusions about populations by using samples (i.e., inferential statistics ), you can use confidence intervals and bootstrap methods as alternatives to the traditional hypothesis testing methods.

March 9, 2020 at 10:01 pm
Hi JIm, could you please help with activities that can best teach concepts of hypothesis testing through simulation, Also, do you have any question set that would enhance students intuition why learning hypothesis testing as a topic in introductory statistics. Thanks.

March 5, 2020 at 3:48 pm
Hi Jim, I’m studying multiple hypothesis testing & was wondering if you had any material that would be relevant. I’m more trying to understand how testing multiple samples simultaneously affects your results & more on the Bonferroni Correction
March 5, 2020 at 4:05 pm
I write about multiple comparisons (aka post hoc tests) in the ANOVA context . I don’t talk about Bonferroni Corrections specifically but I cover related types of corrections. I’m not sure if that exactly addresses what you want to know but is probably the closest I have already written. I hope it helps!

January 14, 2020 at 9:03 pm
Thank you! Have a great day/evening.
January 13, 2020 at 7:10 pm
Any help would be greatly appreciated. What is the difference between The Hypothesis Test and The Statistical Test of Hypothesis?
January 14, 2020 at 11:02 am
They sound like the same thing to me. Unless this is specialized terminology for a particular field or the author was intending something specific, I’d guess they’re one and the same.

April 1, 2019 at 10:00 am
so these are the only two forms of Hypothesis used in statistical testing?
April 1, 2019 at 10:02 am
Are you referring to the null and alternative hypothesis? If so, yes, that’s those are the standard hypotheses in a statistical hypothesis test.
April 1, 2019 at 9:57 am
year very insightful post, thanks for the write up

October 27, 2018 at 11:09 pm
hi there, am upcoming statistician, out of all blogs that i have read, i have found this one more useful as long as my problem is concerned. thanks so much
October 27, 2018 at 11:14 pm
Hi Stano, you’re very welcome! Thanks for your kind words. They mean a lot! I’m happy to hear that my posts were able to help you. I’m sure you will be a fantastic statistician. Best of luck with your studies!

October 26, 2018 at 11:39 am
Dear Jim, thank you very much for your explanations! I have a question. Can I use t-test to compare two samples in case each of them have right bias?
October 26, 2018 at 12:00 pm
Hi Tetyana,
You’re very welcome!
The term “right bias” is not a standard term. Do you by chance mean right skewed distributions? In other words, if you plot the distribution for each group on a histogram they have longer right tails? These are not the symmetrical bell-shape curves of the normal distribution.
If that’s the case, yes you can as long as you exceed a specific sample size within each group. I include a table that contains these sample size requirements in my post about nonparametric vs parametric analyses .
Bias in statistics refers to cases where an estimate of a value is systematically higher or lower than the true value. If this is the case, you might be able to use t-tests, but you’d need to be sure to understand the nature of the bias so you would understand what the results are really indicating.
I hope this helps!

April 2, 2018 at 7:28 am
Simple and upto the point 👍 Thank you so much.
April 2, 2018 at 11:11 am
Hi Kalpana, thanks! And I’m glad it was helpful!

March 26, 2018 at 8:41 am
Am I correct if I say: Alpha – Probability of wrongly rejection of null hypothesis P-value – Probability of wrongly acceptance of null hypothesis
March 28, 2018 at 3:14 pm
You’re correct about alpha. Alpha is the probability of rejecting the null hypothesis when the null is true.
Unfortunately, your definition of the p-value is a bit off. The p-value has a fairly convoluted definition. It is the probability of obtaining the effect observed in a sample, or more extreme, if the null hypothesis is true. The p-value does NOT indicate the probability that either the null or alternative is true or false. Although, those are very common misinterpretations. To learn more, read my post about how to interpret p-values correctly .

March 2, 2018 at 6:10 pm
I recently started reading your blog and it is very helpful to understand each concept of statistical tests in easy way with some good examples. Also, I recommend to other people go through all these blogs which you posted. Specially for those people who have not statistical background and they are facing to many problems while studying statistical analysis.
Thank you for your such good blogs.
March 3, 2018 at 10:12 pm
Hi Amit, I’m so glad that my blog posts have been helpful for you! It means a lot to me that you took the time to write such a nice comment! Also, thanks for recommending by blog to others! I try really hard to write posts about statistics that are easy to understand.

January 17, 2018 at 7:03 am
I recently started reading your blog and I find it very interesting. I am learning statistics by my own, and I generally do many google search to understand the concepts. So this blog is quite helpful for me, as it have most of the content which I am looking for.
January 17, 2018 at 3:56 pm
Hi Shashank, thank you! And, I’m very glad to hear that my blog is helpful!

January 2, 2018 at 2:28 pm
thank u very much sir.
January 2, 2018 at 2:36 pm
You’re very welcome, Hiral!

November 21, 2017 at 12:43 pm
Thank u so much sir….your posts always helps me to be a #statistician
November 21, 2017 at 2:40 pm
Hi Sachin, you’re very welcome! I’m happy that you find my posts to be helpful!

November 19, 2017 at 8:22 pm
great post as usual, but it would be nice to see an example.
November 19, 2017 at 8:27 pm
Thank you! At the end of this post, I have links to four other posts that show examples of hypothesis tests in action. You’ll find what you’re looking for in those posts!
Comments and Questions Cancel reply
Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.
7 Chapter 7: Introduction to Hypothesis Testing
alternative hypothesis
critical value
effect size
null hypothesis
probability value
rejection region
significance level
statistical power
statistical significance
test statistic
Type I error
Type II error
This chapter lays out the basic logic and process of hypothesis testing. We will perform z tests, which use the z score formula from Chapter 6 and data from a sample mean to make an inference about a population.
Logic and Purpose of Hypothesis Testing
A hypothesis is a prediction that is tested in a research study. The statistician R. A. Fisher explained the concept of hypothesis testing with a story of a lady tasting tea. Here we will present an example based on James Bond who insisted that martinis should be shaken rather than stirred. Let’s consider a hypothetical experiment to determine whether Mr. Bond can tell the difference between a shaken martini and a stirred martini. Suppose we gave Mr. Bond a series of 16 taste tests. In each test, we flipped a fair coin to determine whether to stir or shake the martini. Then we presented the martini to Mr. Bond and asked him to decide whether it was shaken or stirred. Let’s say Mr. Bond was correct on 13 of the 16 taste tests. Does this prove that Mr. Bond has at least some ability to tell whether the martini was shaken or stirred?
This result does not prove that he does; it could be he was just lucky and guessed right 13 out of 16 times. But how plausible is the explanation that he was just lucky? To assess its plausibility, we determine the probability that someone who was just guessing would be correct 13/16 times or more. This probability can be computed to be .0106. This is a pretty low probability, and therefore someone would have to be very lucky to be correct 13 or more times out of 16 if they were just guessing. So either Mr. Bond was very lucky, or he can tell whether the drink was shaken or stirred. The hypothesis that he was guessing is not proven false, but considerable doubt is cast on it. Therefore, there is strong evidence that Mr. Bond can tell whether a drink was shaken or stirred.
Let’s consider another example. The case study Physicians’ Reactions sought to determine whether physicians spend less time with obese patients. Physicians were sampled randomly and each was shown a chart of a patient complaining of a migraine headache. They were then asked to estimate how long they would spend with the patient. The charts were identical except that for half the charts, the patient was obese and for the other half, the patient was of average weight. The chart a particular physician viewed was determined randomly. Thirty-three physicians viewed charts of average-weight patients and 38 physicians viewed charts of obese patients.
The mean time physicians reported that they would spend with obese patients was 24.7 minutes as compared to a mean of 31.4 minutes for normal-weight patients. How might this difference between means have occurred? One possibility is that physicians were influenced by the weight of the patients. On the other hand, perhaps by chance, the physicians who viewed charts of the obese patients tend to see patients for less time than the other physicians. Random assignment of charts does not ensure that the groups will be equal in all respects other than the chart they viewed. In fact, it is certain the groups differed in many ways by chance. The two groups could not have exactly the same mean age (if measured precisely enough such as in days). Perhaps a physician’s age affects how long the physician sees patients. There are innumerable differences between the groups that could affect how long they view patients. With this in mind, is it plausible that these chance differences are responsible for the difference in times?
To assess the plausibility of the hypothesis that the difference in mean times is due to chance, we compute the probability of getting a difference as large or larger than the observed difference (31.4 − 24.7 = 6.7 minutes) if the difference were, in fact, due solely to chance. Using methods presented in later chapters, this probability can be computed to be .0057. Since this is such a low probability, we have confidence that the difference in times is due to the patient’s weight and is not due to chance.
The Probability Value
It is very important to understand precisely what the probability values mean. In the James Bond example, the computed probability of .0106 is the probability he would be correct on 13 or more taste tests (out of 16) if he were just guessing. It is easy to mistake this probability of .0106 as the probability he cannot tell the difference. This is not at all what it means.
The probability of .0106 is the probability of a certain outcome (13 or more out of 16) assuming a certain state of the world (James Bond was only guessing). It is not the probability that a state of the world is true. Although this might seem like a distinction without a difference, consider the following example. An animal trainer claims that a trained bird can determine whether or not numbers are evenly divisible by 7. In an experiment assessing this claim, the bird is given a series of 16 test trials. On each trial, a number is displayed on a screen and the bird pecks at one of two keys to indicate its choice. The numbers are chosen in such a way that the probability of any number being evenly divisible by 7 is .50. The bird is correct on 9/16 choices. We can compute that the probability of being correct nine or more times out of 16 if one is only guessing is .40. Since a bird who is only guessing would do this well 40% of the time, these data do not provide convincing evidence that the bird can tell the difference between the two types of numbers. As a scientist, you would be very skeptical that the bird had this ability. Would you conclude that there is a .40 probability that the bird can tell the difference? Certainly not! You would think the probability is much lower than .0001.
To reiterate, the probability value is the probability of an outcome (9/16 or better) and not the probability of a particular state of the world (the bird was only guessing). In statistics, it is conventional to refer to possible states of the world as hypotheses since they are hypothesized states of the world. Using this terminology, the probability value is the probability of an outcome given the hypothesis. It is not the probability of the hypothesis given the outcome.
This is not to say that we ignore the probability of the hypothesis. If the probability of the outcome given the hypothesis is sufficiently low, we have evidence that the hypothesis is false. However, we do not compute the probability that the hypothesis is false. In the James Bond example, the hypothesis is that he cannot tell the difference between shaken and stirred martinis. The probability value is low (.0106), thus providing evidence that he can tell the difference. However, we have not computed the probability that he can tell the difference.
The Null Hypothesis
The hypothesis that an apparent effect is due to chance is called the null hypothesis , written H 0 (“ H -naught”). In the Physicians’ Reactions example, the null hypothesis is that in the population of physicians, the mean time expected to be spent with obese patients is equal to the mean time expected to be spent with average-weight patients. This null hypothesis can be written as:

The null hypothesis in a correlational study of the relationship between high school grades and college grades would typically be that the population correlation is 0. This can be written as

Although the null hypothesis is usually that the value of a parameter is 0, there are occasions in which the null hypothesis is a value other than 0. For example, if we are working with mothers in the U.S. whose children are at risk of low birth weight, we can use 7.47 pounds, the average birth weight in the U.S., as our null value and test for differences against that.
For now, we will focus on testing a value of a single mean against what we expect from the population. Using birth weight as an example, our null hypothesis takes the form:

Keep in mind that the null hypothesis is typically the opposite of the researcher’s hypothesis. In the Physicians’ Reactions study, the researchers hypothesized that physicians would expect to spend less time with obese patients. The null hypothesis that the two types of patients are treated identically is put forward with the hope that it can be discredited and therefore rejected. If the null hypothesis were true, a difference as large as or larger than the sample difference of 6.7 minutes would be very unlikely to occur. Therefore, the researchers rejected the null hypothesis of no difference and concluded that in the population, physicians intend to spend less time with obese patients.
In general, the null hypothesis is the idea that nothing is going on: there is no effect of our treatment, no relationship between our variables, and no difference in our sample mean from what we expected about the population mean. This is always our baseline starting assumption, and it is what we seek to reject. If we are trying to treat depression, we want to find a difference in average symptoms between our treatment and control groups. If we are trying to predict job performance, we want to find a relationship between conscientiousness and evaluation scores. However, until we have evidence against it, we must use the null hypothesis as our starting point.
The Alternative Hypothesis
If the null hypothesis is rejected, then we will need some other explanation, which we call the alternative hypothesis, H A or H 1 . The alternative hypothesis is simply the reverse of the null hypothesis, and there are three options, depending on where we expect the difference to lie. Thus, our alternative hypothesis is the mathematical way of stating our research question. If we expect our obtained sample mean to be above or below the null hypothesis value, which we call a directional hypothesis, then our alternative hypothesis takes the form

based on the research question itself. We should only use a directional hypothesis if we have good reason, based on prior observations or research, to suspect a particular direction. When we do not know the direction, such as when we are entering a new area of research, we use a non-directional alternative:

We will set different criteria for rejecting the null hypothesis based on the directionality (greater than, less than, or not equal to) of the alternative. To understand why, we need to see where our criteria come from and how they relate to z scores and distributions.
Critical Values, p Values, and Significance Level

The significance level is a threshold we set before collecting data in order to determine whether or not we should reject the null hypothesis. We set this value beforehand to avoid biasing ourselves by viewing our results and then determining what criteria we should use. If our data produce values that meet or exceed this threshold, then we have sufficient evidence to reject the null hypothesis; if not, we fail to reject the null (we never “accept” the null).
Figure 7.1. The rejection region for a one-tailed test. (“ Rejection Region for One-Tailed Test ” by Judy Schmitt is licensed under CC BY-NC-SA 4.0 .)

The rejection region is bounded by a specific z value, as is any area under the curve. In hypothesis testing, the value corresponding to a specific rejection region is called the critical value , z crit (“ z crit”), or z * (hence the other name “critical region”). Finding the critical value works exactly the same as finding the z score corresponding to any area under the curve as we did in Unit 1 . If we go to the normal table, we will find that the z score corresponding to 5% of the area under the curve is equal to 1.645 ( z = 1.64 corresponds to .0505 and z = 1.65 corresponds to .0495, so .05 is exactly in between them) if we go to the right and −1.645 if we go to the left. The direction must be determined by your alternative hypothesis, and drawing and shading the distribution is helpful for keeping directionality straight.
Suppose, however, that we want to do a non-directional test. We need to put the critical region in both tails, but we don’t want to increase the overall size of the rejection region (for reasons we will see later). To do this, we simply split it in half so that an equal proportion of the area under the curve falls in each tail’s rejection region. For a = .05, this means 2.5% of the area is in each tail, which, based on the z table, corresponds to critical values of z * = ±1.96. This is shown in Figure 7.2 .
Figure 7.2. Two-tailed rejection region. (“ Rejection Region for Two-Tailed Test ” by Judy Schmitt is licensed under CC BY-NC-SA 4.0 .)

Thus, any z score falling outside ±1.96 (greater than 1.96 in absolute value) falls in the rejection region. When we use z scores in this way, the obtained value of z (sometimes called z obtained and abbreviated z obt ) is something known as a test statistic , which is simply an inferential statistic used to test a null hypothesis. The formula for our z statistic has not changed:

Figure 7.3. Relationship between a , z obt , and p . (“ Relationship between alpha, z-obt, and p ” by Judy Schmitt is licensed under CC BY-NC-SA 4.0 .)

When the null hypothesis is rejected, the effect is said to have statistical significance , or be statistically significant. For example, in the Physicians’ Reactions case study, the probability value is .0057. Therefore, the effect of obesity is statistically significant and the null hypothesis that obesity makes no difference is rejected. It is important to keep in mind that statistical significance means only that the null hypothesis of exactly no effect is rejected; it does not mean that the effect is important, which is what “significant” usually means. When an effect is significant, you can have confidence the effect is not exactly zero. Finding that an effect is significant does not tell you about how large or important the effect is.
Do not confuse statistical significance with practical significance. A small effect can be highly significant if the sample size is large enough.
Why does the word “significant” in the phrase “statistically significant” mean something so different from other uses of the word? Interestingly, this is because the meaning of “significant” in everyday language has changed. It turns out that when the procedures for hypothesis testing were developed, something was “significant” if it signified something. Thus, finding that an effect is statistically significant signifies that the effect is real and not due to chance. Over the years, the meaning of “significant” changed, leading to the potential misinterpretation.
The Hypothesis Testing Process
A four-step procedure.
The process of testing hypotheses follows a simple four-step procedure. This process will be what we use for the remainder of the textbook and course, and although the hypothesis and statistics we use will change, this process will not.
Step 1: State the Hypotheses
Your hypotheses are the first thing you need to lay out. Otherwise, there is nothing to test! You have to state the null hypothesis (which is what we test) and the alternative hypothesis (which is what we expect). These should be stated mathematically as they were presented above and in words, explaining in normal English what each one means in terms of the research question.
Step 2: Find the Critical Values
Step 3: calculate the test statistic and effect size.
Once we have our hypotheses and the standards we use to test them, we can collect data and calculate our test statistic—in this case z . This step is where the vast majority of differences in future chapters will arise: different tests used for different data are calculated in different ways, but the way we use and interpret them remains the same. As part of this step, we will also calculate effect size to better quantify the magnitude of the difference between our groups. Although effect size is not considered part of hypothesis testing, reporting it as part of the results is approved convention.
Step 4: Make the Decision
Finally, once we have our obtained test statistic, we can compare it to our critical value and decide whether we should reject or fail to reject the null hypothesis. When we do this, we must interpret the decision in relation to our research question, stating what we concluded, what we based our conclusion on, and the specific statistics we obtained.
Example A Movie Popcorn
Our manager is looking for a difference in the mean weight of popcorn bags compared to the population mean of 8. We will need both a null and an alternative hypothesis written both mathematically and in words. We’ll always start with the null hypothesis:

In this case, we don’t know if the bags will be too full or not full enough, so we do a two-tailed alternative hypothesis that there is a difference.
Our critical values are based on two things: the directionality of the test and the level of significance. We decided in Step 1 that a two-tailed test is the appropriate directionality. We were given no information about the level of significance, so we assume that a = .05 is what we will use. As stated earlier in the chapter, the critical values for a two-tailed z test at a = .05 are z * = ±1.96. This will be the criteria we use to test our hypothesis. We can now draw out our distribution, as shown in Figure 7.4 , so we can visualize the rejection region and make sure it makes sense.
Figure 7.4. Rejection region for z * = ±1.96. (“ Rejection Region z+-1.96 ” by Judy Schmitt is licensed under CC BY-NC-SA 4.0 .)

Now we come to our formal calculations. Let’s say that the manager collects data and finds that the average weight of this employee’s popcorn bags is M = 7.75 cups. We can now plug this value, along with the values presented in the original problem, into our equation for z :

So our test statistic is z = −2.50, which we can draw onto our rejection region distribution as shown in Figure 7.5 .
Figure 7.5. Test statistic location. (“ Test Statistic Location z-2.50 ” by Judy Schmitt is licensed under CC BY-NC-SA 4.0 .)

Effect Size
When we reject the null hypothesis, we are stating that the difference we found was statistically significant, but we have mentioned several times that this tells us nothing about practical significance. To get an idea of the actual size of what we found, we can compute a new statistic called an effect size. Effect size gives us an idea of how large, important, or meaningful a statistically significant effect is. For mean differences like we calculated here, our effect size is Cohen’s d :

This is very similar to our formula for z , but we no longer take into account the sample size (since overly large samples can make it too easy to reject the null). Cohen’s d is interpreted in units of standard deviations, just like z . For our example:

Cohen’s d is interpreted as small, moderate, or large. Specifically, d = 0.20 is small, d = 0.50 is moderate, and d = 0.80 is large. Obviously, values can fall in between these guidelines, so we should use our best judgment and the context of the problem to make our final interpretation of size. Our effect size happens to be exactly equal to one of these, so we say that there is a moderate effect.
Effect sizes are incredibly useful and provide important information and clarification that overcomes some of the weakness of hypothesis testing. Any time you perform a hypothesis test, whether statistically significant or not, you should always calculate and report effect size.
Looking at Figure 7.5 , we can see that our obtained z statistic falls in the rejection region. We can also directly compare it to our critical value: in terms of absolute value, −2.50 > −1.96, so we reject the null hypothesis. We can now write our conclusion:
Reject H 0 . Based on the sample of 25 bags, we can conclude that the average popcorn bag from this employee is smaller ( M = 7.75 cups) than the average weight of popcorn bags at this movie theater, and the effect size was moderate, z = −2.50, p < .05, d = 0.50.
Example B Office Temperature
Let’s do another example to solidify our understanding. Let’s say that the office building you work in is supposed to be kept at 74 degrees Fahrenheit during the summer months but is allowed to vary by 1 degree in either direction. You suspect that, as a cost saving measure, the temperature was secretly set higher. You set up a formal way to test your hypothesis.
You start by laying out the null hypothesis:

Next you state the alternative hypothesis. You have reason to suspect a specific direction of change, so you make a one-tailed test:

You know that the most common level of significance is a = .05, so you keep that the same and know that the critical value for a one-tailed z test is z * = 1.645. To keep track of the directionality of the test and rejection region, you draw out your distribution as shown in Figure 7.6 .
Figure 7.6. Rejection region. (“ Rejection Region z1.645 ” by Judy Schmitt is licensed under CC BY-NC-SA 4.0 .)

Now that you have everything set up, you spend one week collecting temperature data:
| Day | Temp |
| Monday | 77 |
| Tuesday | 76 |
| Wednesday | 74 |
| Thursday | 78 |
| Friday | 78 |

This value falls so far into the tail that it cannot even be plotted on the distribution ( Figure 7.7 )! Because the result is significant, you also calculate an effect size:

The effect size you calculate is definitely large, meaning someone has some explaining to do!
Figure 7.7. Obtained z statistic. (“ Obtained z5.77 ” by Judy Schmitt is licensed under CC BY-NC-SA 4.0 .)

You compare your obtained z statistic, z = 5.77, to the critical value, z * = 1.645, and find that z > z *. Therefore you reject the null hypothesis, concluding:
Reject H 0 . Based on 5 observations, the average temperature ( M = 76.6 degrees) is statistically significantly higher than it is supposed to be, and the effect size was large, z = 5.77, p < .05, d = 2.60.
Example C Different Significance Level
Finally, let’s take a look at an example phrased in generic terms, rather than in the context of a specific research question, to see the individual pieces one more time. This time, however, we will use a stricter significance level, a = .01, to test the hypothesis.
We will use 60 as an arbitrary null hypothesis value:

We will assume a two-tailed test:

We have seen the critical values for z tests at a = .05 levels of significance several times. To find the values for a = .01, we will go to the Standard Normal Distribution Table and find the z score cutting off .005 (.01 divided by 2 for a two-tailed test) of the area in the tail, which is z * = ±2.575. Notice that this cutoff is much higher than it was for a = .05. This is because we need much less of the area in the tail, so we need to go very far out to find the cutoff. As a result, this will require a much larger effect or much larger sample size in order to reject the null hypothesis.
We can now calculate our test statistic. We will use s = 10 as our known population standard deviation and the following data to calculate our sample mean:

The average of these scores is M = 60.40. From this we calculate our z statistic as:

The Cohen’s d effect size calculation is:

Our obtained z statistic, z = 0.13, is very small. It is much less than our critical value of 2.575. Thus, this time, we fail to reject the null hypothesis. Our conclusion would look something like:
Fail to reject H 0 . Based on the sample of 10 scores, we cannot conclude that there is an effect causing the mean ( M = 60.40) to be statistically significantly different from 60.00, z = 0.13, p > .01, d = 0.04, and the effect size supports this interpretation.
Other Considerations in Hypothesis Testing
There are several other considerations we need to keep in mind when performing hypothesis testing.
Errors in Hypothesis Testing
In the Physicians’ Reactions case study, the probability value associated with the significance test is .0057. Therefore, the null hypothesis was rejected, and it was concluded that physicians intend to spend less time with obese patients. Despite the low probability value, it is possible that the null hypothesis of no true difference between obese and average-weight patients is true and that the large difference between sample means occurred by chance. If this is the case, then the conclusion that physicians intend to spend less time with obese patients is in error. This type of error is called a Type I error. More generally, a Type I error occurs when a significance test results in the rejection of a true null hypothesis.
The second type of error that can be made in significance testing is failing to reject a false null hypothesis. This kind of error is called a Type II error . Unlike a Type I error, a Type II error is not really an error. When a statistical test is not significant, it means that the data do not provide strong evidence that the null hypothesis is false. Lack of significance does not support the conclusion that the null hypothesis is true. Therefore, a researcher should not make the mistake of incorrectly concluding that the null hypothesis is true when a statistical test was not significant. Instead, the researcher should consider the test inconclusive. Contrast this with a Type I error in which the researcher erroneously concludes that the null hypothesis is false when, in fact, it is true.
A Type II error can only occur if the null hypothesis is false. If the null hypothesis is false, then the probability of a Type II error is called b (“beta”). The probability of correctly rejecting a false null hypothesis equals 1 − b and is called statistical power . Power is simply our ability to correctly detect an effect that exists. It is influenced by the size of the effect (larger effects are easier to detect), the significance level we set (making it easier to reject the null makes it easier to detect an effect, but increases the likelihood of a Type I error), and the sample size used (larger samples make it easier to reject the null).
Misconceptions in Hypothesis Testing
Misconceptions about significance testing are common. This section lists three important ones.
- Misconception: The probability value ( p value) is the probability that the null hypothesis is false. Proper interpretation: The probability value ( p value) is the probability of a result as extreme or more extreme given that the null hypothesis is true. It is the probability of the data given the null hypothesis. It is not the probability that the null hypothesis is false.
- Misconception: A low probability value indicates a large effect. Proper interpretation: A low probability value indicates that the sample outcome (or an outcome more extreme) would be very unlikely if the null hypothesis were true. A low probability value can occur with small effect sizes, particularly if the sample size is large.
- Misconception: A non-significant outcome means that the null hypothesis is probably true. Proper interpretation: A non-significant outcome means that the data do not conclusively demonstrate that the null hypothesis is false.
- In your own words, explain what the null hypothesis is.
- What are Type I and Type II errors?
- Why do we phrase null and alternative hypotheses with population parameters and not sample means?
- Why do we state our hypotheses and decision criteria before we collect our data?
- Why do you calculate an effect size?
- z = 1.99, two-tailed test at a = .05
- z = 0.34, z * = 1.645
- p = .03, a = .05
- p = .015, a = .01
Answers to Odd-Numbered Exercises
Your answer should include mention of the baseline assumption of no difference between the sample and the population.
Alpha is the significance level. It is the criterion we use when deciding to reject or fail to reject the null hypothesis, corresponding to a given proportion of the area under the normal distribution and a probability of finding extreme scores assuming the null hypothesis is true.
We always calculate an effect size to see if our research is practically meaningful or important. NHST (null hypothesis significance testing) is influenced by sample size but effect size is not; therefore, they provide complimentary information.

“ Null Hypothesis ” by Randall Munroe/xkcd.com is licensed under CC BY-NC 2.5 .)

Introduction to Statistics in the Psychological Sciences Copyright © 2021 by Linda R. Cote Ph.D.; Rupa G. Gordon Ph.D.; Chrislyn E. Randell Ph.D.; Judy Schmitt; and Helena Marvin is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License , except where otherwise noted.
Share This Book
- Hypothesis Testing: Definition, Uses, Limitations + Examples

Hypothesis testing is as old as the scientific method and is at the heart of the research process.
Research exists to validate or disprove assumptions about various phenomena. The process of validation involves testing and it is in this context that we will explore hypothesis testing.
What is a Hypothesis?
A hypothesis is a calculated prediction or assumption about a population parameter based on limited evidence. The whole idea behind hypothesis formulation is testing—this means the researcher subjects his or her calculated assumption to a series of evaluations to know whether they are true or false.
Typically, every research starts with a hypothesis—the investigator makes a claim and experiments to prove that this claim is true or false . For instance, if you predict that students who drink milk before class perform better than those who don’t, then this becomes a hypothesis that can be confirmed or refuted using an experiment.
Read: What is Empirical Research Study? [Examples & Method]
What are the Types of Hypotheses?
1. simple hypothesis.
Also known as a basic hypothesis, a simple hypothesis suggests that an independent variable is responsible for a corresponding dependent variable. In other words, an occurrence of the independent variable inevitably leads to an occurrence of the dependent variable.
Typically, simple hypotheses are considered as generally true, and they establish a causal relationship between two variables.
Examples of Simple Hypothesis
- Drinking soda and other sugary drinks can cause obesity.
- Smoking cigarettes daily leads to lung cancer.
2. Complex Hypothesis
A complex hypothesis is also known as a modal. It accounts for the causal relationship between two independent variables and the resulting dependent variables. This means that the combination of the independent variables leads to the occurrence of the dependent variables .
Examples of Complex Hypotheses
- Adults who do not smoke and drink are less likely to develop liver-related conditions.
- Global warming causes icebergs to melt which in turn causes major changes in weather patterns.
3. Null Hypothesis
As the name suggests, a null hypothesis is formed when a researcher suspects that there’s no relationship between the variables in an observation. In this case, the purpose of the research is to approve or disapprove this assumption.
Examples of Null Hypothesis
- This is no significant change in a student’s performance if they drink coffee or tea before classes.
- There’s no significant change in the growth of a plant if one uses distilled water only or vitamin-rich water.
Read: Research Report: Definition, Types + [Writing Guide]
4. Alternative Hypothesis
To disapprove a null hypothesis, the researcher has to come up with an opposite assumption—this assumption is known as the alternative hypothesis. This means if the null hypothesis says that A is false, the alternative hypothesis assumes that A is true.
An alternative hypothesis can be directional or non-directional depending on the direction of the difference. A directional alternative hypothesis specifies the direction of the tested relationship, stating that one variable is predicted to be larger or smaller than the null value while a non-directional hypothesis only validates the existence of a difference without stating its direction.
Examples of Alternative Hypotheses
- Starting your day with a cup of tea instead of a cup of coffee can make you more alert in the morning.
- The growth of a plant improves significantly when it receives distilled water instead of vitamin-rich water.
5. Logical Hypothesis
Logical hypotheses are some of the most common types of calculated assumptions in systematic investigations. It is an attempt to use your reasoning to connect different pieces in research and build a theory using little evidence. In this case, the researcher uses any data available to him, to form a plausible assumption that can be tested.
Examples of Logical Hypothesis
- Waking up early helps you to have a more productive day.
- Beings from Mars would not be able to breathe the air in the atmosphere of the Earth.
6. Empirical Hypothesis
After forming a logical hypothesis, the next step is to create an empirical or working hypothesis. At this stage, your logical hypothesis undergoes systematic testing to prove or disprove the assumption. An empirical hypothesis is subject to several variables that can trigger changes and lead to specific outcomes.
Examples of Empirical Testing
- People who eat more fish run faster than people who eat meat.
- Women taking vitamin E grow hair faster than those taking vitamin K.
7. Statistical Hypothesis
When forming a statistical hypothesis, the researcher examines the portion of a population of interest and makes a calculated assumption based on the data from this sample. A statistical hypothesis is most common with systematic investigations involving a large target audience. Here, it’s impossible to collect responses from every member of the population so you have to depend on data from your sample and extrapolate the results to the wider population.
Examples of Statistical Hypothesis
- 45% of students in Louisiana have middle-income parents.
- 80% of the UK’s population gets a divorce because of irreconcilable differences.
What is Hypothesis Testing?
Hypothesis testing is an assessment method that allows researchers to determine the plausibility of a hypothesis. It involves testing an assumption about a specific population parameter to know whether it’s true or false. These population parameters include variance, standard deviation, and median.
Typically, hypothesis testing starts with developing a null hypothesis and then performing several tests that support or reject the null hypothesis. The researcher uses test statistics to compare the association or relationship between two or more variables.
Explore: Research Bias: Definition, Types + Examples
Researchers also use hypothesis testing to calculate the coefficient of variation and determine if the regression relationship and the correlation coefficient are statistically significant.
How Hypothesis Testing Works
The basis of hypothesis testing is to examine and analyze the null hypothesis and alternative hypothesis to know which one is the most plausible assumption. Since both assumptions are mutually exclusive, only one can be true. In other words, the occurrence of a null hypothesis destroys the chances of the alternative coming to life, and vice-versa.
Interesting: 21 Chrome Extensions for Academic Researchers in 2021
What Are The Stages of Hypothesis Testing?
To successfully confirm or refute an assumption, the researcher goes through five (5) stages of hypothesis testing;
- Determine the null hypothesis
- Specify the alternative hypothesis
- Set the significance level
- Calculate the test statistics and corresponding P-value
- Draw your conclusion
- Determine the Null Hypothesis
Like we mentioned earlier, hypothesis testing starts with creating a null hypothesis which stands as an assumption that a certain statement is false or implausible. For example, the null hypothesis (H0) could suggest that different subgroups in the research population react to a variable in the same way.
- Specify the Alternative Hypothesis
Once you know the variables for the null hypothesis, the next step is to determine the alternative hypothesis. The alternative hypothesis counters the null assumption by suggesting the statement or assertion is true. Depending on the purpose of your research, the alternative hypothesis can be one-sided or two-sided.
Using the example we established earlier, the alternative hypothesis may argue that the different sub-groups react differently to the same variable based on several internal and external factors.
- Set the Significance Level
Many researchers create a 5% allowance for accepting the value of an alternative hypothesis, even if the value is untrue. This means that there is a 0.05 chance that one would go with the value of the alternative hypothesis, despite the truth of the null hypothesis.
Something to note here is that the smaller the significance level, the greater the burden of proof needed to reject the null hypothesis and support the alternative hypothesis.
Explore: What is Data Interpretation? + [Types, Method & Tools]
- Calculate the Test Statistics and Corresponding P-Value
Test statistics in hypothesis testing allow you to compare different groups between variables while the p-value accounts for the probability of obtaining sample statistics if your null hypothesis is true. In this case, your test statistics can be the mean, median and similar parameters.
If your p-value is 0.65, for example, then it means that the variable in your hypothesis will happen 65 in100 times by pure chance. Use this formula to determine the p-value for your data:

- Draw Your Conclusions
After conducting a series of tests, you should be able to agree or refute the hypothesis based on feedback and insights from your sample data.
Applications of Hypothesis Testing in Research
Hypothesis testing isn’t only confined to numbers and calculations; it also has several real-life applications in business, manufacturing, advertising, and medicine.
In a factory or other manufacturing plants, hypothesis testing is an important part of quality and production control before the final products are approved and sent out to the consumer.
During ideation and strategy development, C-level executives use hypothesis testing to evaluate their theories and assumptions before any form of implementation. For example, they could leverage hypothesis testing to determine whether or not some new advertising campaign, marketing technique, etc. causes increased sales.
In addition, hypothesis testing is used during clinical trials to prove the efficacy of a drug or new medical method before its approval for widespread human usage.
What is an Example of Hypothesis Testing?
An employer claims that her workers are of above-average intelligence. She takes a random sample of 20 of them and gets the following results:
Mean IQ Scores: 110
Standard Deviation: 15
Mean Population IQ: 100
Step 1: Using the value of the mean population IQ, we establish the null hypothesis as 100.
Step 2: State that the alternative hypothesis is greater than 100.
Step 3: State the alpha level as 0.05 or 5%
Step 4: Find the rejection region area (given by your alpha level above) from the z-table. An area of .05 is equal to a z-score of 1.645.
Step 5: Calculate the test statistics using this formula

Z = (110–100) ÷ (15÷√20)
10 ÷ 3.35 = 2.99
If the value of the test statistics is higher than the value of the rejection region, then you should reject the null hypothesis. If it is less, then you cannot reject the null.
In this case, 2.99 > 1.645 so we reject the null.
Importance/Benefits of Hypothesis Testing
The most significant benefit of hypothesis testing is it allows you to evaluate the strength of your claim or assumption before implementing it in your data set. Also, hypothesis testing is the only valid method to prove that something “is or is not”. Other benefits include:
- Hypothesis testing provides a reliable framework for making any data decisions for your population of interest.
- It helps the researcher to successfully extrapolate data from the sample to the larger population.
- Hypothesis testing allows the researcher to determine whether the data from the sample is statistically significant.
- Hypothesis testing is one of the most important processes for measuring the validity and reliability of outcomes in any systematic investigation.
- It helps to provide links to the underlying theory and specific research questions.
Criticism and Limitations of Hypothesis Testing
Several limitations of hypothesis testing can affect the quality of data you get from this process. Some of these limitations include:
- The interpretation of a p-value for observation depends on the stopping rule and definition of multiple comparisons. This makes it difficult to calculate since the stopping rule is subject to numerous interpretations, plus “multiple comparisons” are unavoidably ambiguous.
- Conceptual issues often arise in hypothesis testing, especially if the researcher merges Fisher and Neyman-Pearson’s methods which are conceptually distinct.
- In an attempt to focus on the statistical significance of the data, the researcher might ignore the estimation and confirmation by repeated experiments.
- Hypothesis testing can trigger publication bias, especially when it requires statistical significance as a criterion for publication.
- When used to detect whether a difference exists between groups, hypothesis testing can trigger absurd assumptions that affect the reliability of your observation.
Connect to Formplus, Get Started Now - It's Free!
- alternative hypothesis
- alternative vs null hypothesis
- complex hypothesis
- empirical hypothesis
- hypothesis testing
- logical hypothesis
- simple hypothesis
- statistical hypothesis
- busayo.longe
You may also like:
What is Pure or Basic Research? + [Examples & Method]
Simple guide on pure or basic research, its methods, characteristics, advantages, and examples in science, medicine, education and psychology
Internal Validity in Research: Definition, Threats, Examples
In this article, we will discuss the concept of internal validity, some clear examples, its importance, and how to test it.
Type I vs Type II Errors: Causes, Examples & Prevention
This article will discuss the two different types of errors in hypothesis testing and how you can prevent them from occurring in your research
Alternative vs Null Hypothesis: Pros, Cons, Uses & Examples
We are going to discuss alternative hypotheses and null hypotheses in this post and how they work in research.
Formplus - For Seamless Data Collection
Collect data the right way with a versatile data collection tool. try formplus and transform your work productivity today..
- Resources Home 🏠
- Try SciSpace Copilot
- Search research papers
- Add Copilot Extension
- Try AI Detector
- Try Paraphraser
- Try Citation Generator
- April Papers
- June Papers
- July Papers

The Craft of Writing a Strong Hypothesis

Table of Contents
Writing a hypothesis is one of the essential elements of a scientific research paper. It needs to be to the point, clearly communicating what your research is trying to accomplish. A blurry, drawn-out, or complexly-structured hypothesis can confuse your readers. Or worse, the editor and peer reviewers.
A captivating hypothesis is not too intricate. This blog will take you through the process so that, by the end of it, you have a better idea of how to convey your research paper's intent in just one sentence.
What is a Hypothesis?
The first step in your scientific endeavor, a hypothesis, is a strong, concise statement that forms the basis of your research. It is not the same as a thesis statement , which is a brief summary of your research paper .
The sole purpose of a hypothesis is to predict your paper's findings, data, and conclusion. It comes from a place of curiosity and intuition . When you write a hypothesis, you're essentially making an educated guess based on scientific prejudices and evidence, which is further proven or disproven through the scientific method.
The reason for undertaking research is to observe a specific phenomenon. A hypothesis, therefore, lays out what the said phenomenon is. And it does so through two variables, an independent and dependent variable.
The independent variable is the cause behind the observation, while the dependent variable is the effect of the cause. A good example of this is “mixing red and blue forms purple.” In this hypothesis, mixing red and blue is the independent variable as you're combining the two colors at your own will. The formation of purple is the dependent variable as, in this case, it is conditional to the independent variable.
Different Types of Hypotheses

Types of hypotheses
Some would stand by the notion that there are only two types of hypotheses: a Null hypothesis and an Alternative hypothesis. While that may have some truth to it, it would be better to fully distinguish the most common forms as these terms come up so often, which might leave you out of context.
Apart from Null and Alternative, there are Complex, Simple, Directional, Non-Directional, Statistical, and Associative and casual hypotheses. They don't necessarily have to be exclusive, as one hypothesis can tick many boxes, but knowing the distinctions between them will make it easier for you to construct your own.
1. Null hypothesis
A null hypothesis proposes no relationship between two variables. Denoted by H 0 , it is a negative statement like “Attending physiotherapy sessions does not affect athletes' on-field performance.” Here, the author claims physiotherapy sessions have no effect on on-field performances. Even if there is, it's only a coincidence.
2. Alternative hypothesis
Considered to be the opposite of a null hypothesis, an alternative hypothesis is donated as H1 or Ha. It explicitly states that the dependent variable affects the independent variable. A good alternative hypothesis example is “Attending physiotherapy sessions improves athletes' on-field performance.” or “Water evaporates at 100 °C. ” The alternative hypothesis further branches into directional and non-directional.
- Directional hypothesis: A hypothesis that states the result would be either positive or negative is called directional hypothesis. It accompanies H1 with either the ‘<' or ‘>' sign.
- Non-directional hypothesis: A non-directional hypothesis only claims an effect on the dependent variable. It does not clarify whether the result would be positive or negative. The sign for a non-directional hypothesis is ‘≠.'
3. Simple hypothesis
A simple hypothesis is a statement made to reflect the relation between exactly two variables. One independent and one dependent. Consider the example, “Smoking is a prominent cause of lung cancer." The dependent variable, lung cancer, is dependent on the independent variable, smoking.
4. Complex hypothesis
In contrast to a simple hypothesis, a complex hypothesis implies the relationship between multiple independent and dependent variables. For instance, “Individuals who eat more fruits tend to have higher immunity, lesser cholesterol, and high metabolism.” The independent variable is eating more fruits, while the dependent variables are higher immunity, lesser cholesterol, and high metabolism.
5. Associative and casual hypothesis
Associative and casual hypotheses don't exhibit how many variables there will be. They define the relationship between the variables. In an associative hypothesis, changing any one variable, dependent or independent, affects others. In a casual hypothesis, the independent variable directly affects the dependent.
6. Empirical hypothesis
Also referred to as the working hypothesis, an empirical hypothesis claims a theory's validation via experiments and observation. This way, the statement appears justifiable and different from a wild guess.
Say, the hypothesis is “Women who take iron tablets face a lesser risk of anemia than those who take vitamin B12.” This is an example of an empirical hypothesis where the researcher the statement after assessing a group of women who take iron tablets and charting the findings.
7. Statistical hypothesis
The point of a statistical hypothesis is to test an already existing hypothesis by studying a population sample. Hypothesis like “44% of the Indian population belong in the age group of 22-27.” leverage evidence to prove or disprove a particular statement.
Characteristics of a Good Hypothesis
Writing a hypothesis is essential as it can make or break your research for you. That includes your chances of getting published in a journal. So when you're designing one, keep an eye out for these pointers:
- A research hypothesis has to be simple yet clear to look justifiable enough.
- It has to be testable — your research would be rendered pointless if too far-fetched into reality or limited by technology.
- It has to be precise about the results —what you are trying to do and achieve through it should come out in your hypothesis.
- A research hypothesis should be self-explanatory, leaving no doubt in the reader's mind.
- If you are developing a relational hypothesis, you need to include the variables and establish an appropriate relationship among them.
- A hypothesis must keep and reflect the scope for further investigations and experiments.
Separating a Hypothesis from a Prediction
Outside of academia, hypothesis and prediction are often used interchangeably. In research writing, this is not only confusing but also incorrect. And although a hypothesis and prediction are guesses at their core, there are many differences between them.
A hypothesis is an educated guess or even a testable prediction validated through research. It aims to analyze the gathered evidence and facts to define a relationship between variables and put forth a logical explanation behind the nature of events.
Predictions are assumptions or expected outcomes made without any backing evidence. They are more fictionally inclined regardless of where they originate from.
For this reason, a hypothesis holds much more weight than a prediction. It sticks to the scientific method rather than pure guesswork. "Planets revolve around the Sun." is an example of a hypothesis as it is previous knowledge and observed trends. Additionally, we can test it through the scientific method.
Whereas "COVID-19 will be eradicated by 2030." is a prediction. Even though it results from past trends, we can't prove or disprove it. So, the only way this gets validated is to wait and watch if COVID-19 cases end by 2030.
Finally, How to Write a Hypothesis

Quick tips on writing a hypothesis
1. Be clear about your research question
A hypothesis should instantly address the research question or the problem statement. To do so, you need to ask a question. Understand the constraints of your undertaken research topic and then formulate a simple and topic-centric problem. Only after that can you develop a hypothesis and further test for evidence.
2. Carry out a recce
Once you have your research's foundation laid out, it would be best to conduct preliminary research. Go through previous theories, academic papers, data, and experiments before you start curating your research hypothesis. It will give you an idea of your hypothesis's viability or originality.
Making use of references from relevant research papers helps draft a good research hypothesis. SciSpace Discover offers a repository of over 270 million research papers to browse through and gain a deeper understanding of related studies on a particular topic. Additionally, you can use SciSpace Copilot , your AI research assistant, for reading any lengthy research paper and getting a more summarized context of it. A hypothesis can be formed after evaluating many such summarized research papers. Copilot also offers explanations for theories and equations, explains paper in simplified version, allows you to highlight any text in the paper or clip math equations and tables and provides a deeper, clear understanding of what is being said. This can improve the hypothesis by helping you identify potential research gaps.
3. Create a 3-dimensional hypothesis
Variables are an essential part of any reasonable hypothesis. So, identify your independent and dependent variable(s) and form a correlation between them. The ideal way to do this is to write the hypothetical assumption in the ‘if-then' form. If you use this form, make sure that you state the predefined relationship between the variables.
In another way, you can choose to present your hypothesis as a comparison between two variables. Here, you must specify the difference you expect to observe in the results.
4. Write the first draft
Now that everything is in place, it's time to write your hypothesis. For starters, create the first draft. In this version, write what you expect to find from your research.
Clearly separate your independent and dependent variables and the link between them. Don't fixate on syntax at this stage. The goal is to ensure your hypothesis addresses the issue.
5. Proof your hypothesis
After preparing the first draft of your hypothesis, you need to inspect it thoroughly. It should tick all the boxes, like being concise, straightforward, relevant, and accurate. Your final hypothesis has to be well-structured as well.
Research projects are an exciting and crucial part of being a scholar. And once you have your research question, you need a great hypothesis to begin conducting research. Thus, knowing how to write a hypothesis is very important.
Now that you have a firmer grasp on what a good hypothesis constitutes, the different kinds there are, and what process to follow, you will find it much easier to write your hypothesis, which ultimately helps your research.
Now it's easier than ever to streamline your research workflow with SciSpace Discover . Its integrated, comprehensive end-to-end platform for research allows scholars to easily discover, write and publish their research and fosters collaboration.
It includes everything you need, including a repository of over 270 million research papers across disciplines, SEO-optimized summaries and public profiles to show your expertise and experience.
If you found these tips on writing a research hypothesis useful, head over to our blog on Statistical Hypothesis Testing to learn about the top researchers, papers, and institutions in this domain.
Frequently Asked Questions (FAQs)
1. what is the definition of hypothesis.
According to the Oxford dictionary, a hypothesis is defined as “An idea or explanation of something that is based on a few known facts, but that has not yet been proved to be true or correct”.
2. What is an example of hypothesis?
The hypothesis is a statement that proposes a relationship between two or more variables. An example: "If we increase the number of new users who join our platform by 25%, then we will see an increase in revenue."
3. What is an example of null hypothesis?
A null hypothesis is a statement that there is no relationship between two variables. The null hypothesis is written as H0. The null hypothesis states that there is no effect. For example, if you're studying whether or not a particular type of exercise increases strength, your null hypothesis will be "there is no difference in strength between people who exercise and people who don't."
4. What are the types of research?
• Fundamental research
• Applied research
• Qualitative research
• Quantitative research
• Mixed research
• Exploratory research
• Longitudinal research
• Cross-sectional research
• Field research
• Laboratory research
• Fixed research
• Flexible research
• Action research
• Policy research
• Classification research
• Comparative research
• Causal research
• Inductive research
• Deductive research
5. How to write a hypothesis?
• Your hypothesis should be able to predict the relationship and outcome.
• Avoid wordiness by keeping it simple and brief.
• Your hypothesis should contain observable and testable outcomes.
• Your hypothesis should be relevant to the research question.
6. What are the 2 types of hypothesis?
• Null hypotheses are used to test the claim that "there is no difference between two groups of data".
• Alternative hypotheses test the claim that "there is a difference between two data groups".
7. Difference between research question and research hypothesis?
A research question is a broad, open-ended question you will try to answer through your research. A hypothesis is a statement based on prior research or theory that you expect to be true due to your study. Example - Research question: What are the factors that influence the adoption of the new technology? Research hypothesis: There is a positive relationship between age, education and income level with the adoption of the new technology.
8. What is plural for hypothesis?
The plural of hypothesis is hypotheses. Here's an example of how it would be used in a statement, "Numerous well-considered hypotheses are presented in this part, and they are supported by tables and figures that are well-illustrated."
9. What is the red queen hypothesis?
The red queen hypothesis in evolutionary biology states that species must constantly evolve to avoid extinction because if they don't, they will be outcompeted by other species that are evolving. Leigh Van Valen first proposed it in 1973; since then, it has been tested and substantiated many times.
10. Who is known as the father of null hypothesis?
The father of the null hypothesis is Sir Ronald Fisher. He published a paper in 1925 that introduced the concept of null hypothesis testing, and he was also the first to use the term itself.
11. When to reject null hypothesis?
You need to find a significant difference between your two populations to reject the null hypothesis. You can determine that by running statistical tests such as an independent sample t-test or a dependent sample t-test. You should reject the null hypothesis if the p-value is less than 0.05.
You might also like

Consensus GPT vs. SciSpace GPT: Choose the Best GPT for Research

Literature Review and Theoretical Framework: Understanding the Differences

Types of Essays in Academic Writing - Quick Guide (2024)

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
- J Korean Med Sci
- v.37(16); 2022 Apr 25
A Practical Guide to Writing Quantitative and Qualitative Research Questions and Hypotheses in Scholarly Articles
Edward barroga.
1 Department of General Education, Graduate School of Nursing Science, St. Luke’s International University, Tokyo, Japan.
Glafera Janet Matanguihan
2 Department of Biological Sciences, Messiah University, Mechanicsburg, PA, USA.
The development of research questions and the subsequent hypotheses are prerequisites to defining the main research purpose and specific objectives of a study. Consequently, these objectives determine the study design and research outcome. The development of research questions is a process based on knowledge of current trends, cutting-edge studies, and technological advances in the research field. Excellent research questions are focused and require a comprehensive literature search and in-depth understanding of the problem being investigated. Initially, research questions may be written as descriptive questions which could be developed into inferential questions. These questions must be specific and concise to provide a clear foundation for developing hypotheses. Hypotheses are more formal predictions about the research outcomes. These specify the possible results that may or may not be expected regarding the relationship between groups. Thus, research questions and hypotheses clarify the main purpose and specific objectives of the study, which in turn dictate the design of the study, its direction, and outcome. Studies developed from good research questions and hypotheses will have trustworthy outcomes with wide-ranging social and health implications.
INTRODUCTION
Scientific research is usually initiated by posing evidenced-based research questions which are then explicitly restated as hypotheses. 1 , 2 The hypotheses provide directions to guide the study, solutions, explanations, and expected results. 3 , 4 Both research questions and hypotheses are essentially formulated based on conventional theories and real-world processes, which allow the inception of novel studies and the ethical testing of ideas. 5 , 6
It is crucial to have knowledge of both quantitative and qualitative research 2 as both types of research involve writing research questions and hypotheses. 7 However, these crucial elements of research are sometimes overlooked; if not overlooked, then framed without the forethought and meticulous attention it needs. Planning and careful consideration are needed when developing quantitative or qualitative research, particularly when conceptualizing research questions and hypotheses. 4
There is a continuing need to support researchers in the creation of innovative research questions and hypotheses, as well as for journal articles that carefully review these elements. 1 When research questions and hypotheses are not carefully thought of, unethical studies and poor outcomes usually ensue. Carefully formulated research questions and hypotheses define well-founded objectives, which in turn determine the appropriate design, course, and outcome of the study. This article then aims to discuss in detail the various aspects of crafting research questions and hypotheses, with the goal of guiding researchers as they develop their own. Examples from the authors and peer-reviewed scientific articles in the healthcare field are provided to illustrate key points.
DEFINITIONS AND RELATIONSHIP OF RESEARCH QUESTIONS AND HYPOTHESES
A research question is what a study aims to answer after data analysis and interpretation. The answer is written in length in the discussion section of the paper. Thus, the research question gives a preview of the different parts and variables of the study meant to address the problem posed in the research question. 1 An excellent research question clarifies the research writing while facilitating understanding of the research topic, objective, scope, and limitations of the study. 5
On the other hand, a research hypothesis is an educated statement of an expected outcome. This statement is based on background research and current knowledge. 8 , 9 The research hypothesis makes a specific prediction about a new phenomenon 10 or a formal statement on the expected relationship between an independent variable and a dependent variable. 3 , 11 It provides a tentative answer to the research question to be tested or explored. 4
Hypotheses employ reasoning to predict a theory-based outcome. 10 These can also be developed from theories by focusing on components of theories that have not yet been observed. 10 The validity of hypotheses is often based on the testability of the prediction made in a reproducible experiment. 8
Conversely, hypotheses can also be rephrased as research questions. Several hypotheses based on existing theories and knowledge may be needed to answer a research question. Developing ethical research questions and hypotheses creates a research design that has logical relationships among variables. These relationships serve as a solid foundation for the conduct of the study. 4 , 11 Haphazardly constructed research questions can result in poorly formulated hypotheses and improper study designs, leading to unreliable results. Thus, the formulations of relevant research questions and verifiable hypotheses are crucial when beginning research. 12
CHARACTERISTICS OF GOOD RESEARCH QUESTIONS AND HYPOTHESES
Excellent research questions are specific and focused. These integrate collective data and observations to confirm or refute the subsequent hypotheses. Well-constructed hypotheses are based on previous reports and verify the research context. These are realistic, in-depth, sufficiently complex, and reproducible. More importantly, these hypotheses can be addressed and tested. 13
There are several characteristics of well-developed hypotheses. Good hypotheses are 1) empirically testable 7 , 10 , 11 , 13 ; 2) backed by preliminary evidence 9 ; 3) testable by ethical research 7 , 9 ; 4) based on original ideas 9 ; 5) have evidenced-based logical reasoning 10 ; and 6) can be predicted. 11 Good hypotheses can infer ethical and positive implications, indicating the presence of a relationship or effect relevant to the research theme. 7 , 11 These are initially developed from a general theory and branch into specific hypotheses by deductive reasoning. In the absence of a theory to base the hypotheses, inductive reasoning based on specific observations or findings form more general hypotheses. 10
TYPES OF RESEARCH QUESTIONS AND HYPOTHESES
Research questions and hypotheses are developed according to the type of research, which can be broadly classified into quantitative and qualitative research. We provide a summary of the types of research questions and hypotheses under quantitative and qualitative research categories in Table 1 .
| Quantitative research questions | Quantitative research hypotheses |
|---|---|
| Descriptive research questions | Simple hypothesis |
| Comparative research questions | Complex hypothesis |
| Relationship research questions | Directional hypothesis |
| Non-directional hypothesis | |
| Associative hypothesis | |
| Causal hypothesis | |
| Null hypothesis | |
| Alternative hypothesis | |
| Working hypothesis | |
| Statistical hypothesis | |
| Logical hypothesis | |
| Hypothesis-testing | |
| Qualitative research questions | Qualitative research hypotheses |
| Contextual research questions | Hypothesis-generating |
| Descriptive research questions | |
| Evaluation research questions | |
| Explanatory research questions | |
| Exploratory research questions | |
| Generative research questions | |
| Ideological research questions | |
| Ethnographic research questions | |
| Phenomenological research questions | |
| Grounded theory questions | |
| Qualitative case study questions |
Research questions in quantitative research
In quantitative research, research questions inquire about the relationships among variables being investigated and are usually framed at the start of the study. These are precise and typically linked to the subject population, dependent and independent variables, and research design. 1 Research questions may also attempt to describe the behavior of a population in relation to one or more variables, or describe the characteristics of variables to be measured ( descriptive research questions ). 1 , 5 , 14 These questions may also aim to discover differences between groups within the context of an outcome variable ( comparative research questions ), 1 , 5 , 14 or elucidate trends and interactions among variables ( relationship research questions ). 1 , 5 We provide examples of descriptive, comparative, and relationship research questions in quantitative research in Table 2 .
| Quantitative research questions | |
|---|---|
| Descriptive research question | |
| - Measures responses of subjects to variables | |
| - Presents variables to measure, analyze, or assess | |
| What is the proportion of resident doctors in the hospital who have mastered ultrasonography (response of subjects to a variable) as a diagnostic technique in their clinical training? | |
| Comparative research question | |
| - Clarifies difference between one group with outcome variable and another group without outcome variable | |
| Is there a difference in the reduction of lung metastasis in osteosarcoma patients who received the vitamin D adjunctive therapy (group with outcome variable) compared with osteosarcoma patients who did not receive the vitamin D adjunctive therapy (group without outcome variable)? | |
| - Compares the effects of variables | |
| How does the vitamin D analogue 22-Oxacalcitriol (variable 1) mimic the antiproliferative activity of 1,25-Dihydroxyvitamin D (variable 2) in osteosarcoma cells? | |
| Relationship research question | |
| - Defines trends, association, relationships, or interactions between dependent variable and independent variable | |
| Is there a relationship between the number of medical student suicide (dependent variable) and the level of medical student stress (independent variable) in Japan during the first wave of the COVID-19 pandemic? | |
Hypotheses in quantitative research
In quantitative research, hypotheses predict the expected relationships among variables. 15 Relationships among variables that can be predicted include 1) between a single dependent variable and a single independent variable ( simple hypothesis ) or 2) between two or more independent and dependent variables ( complex hypothesis ). 4 , 11 Hypotheses may also specify the expected direction to be followed and imply an intellectual commitment to a particular outcome ( directional hypothesis ) 4 . On the other hand, hypotheses may not predict the exact direction and are used in the absence of a theory, or when findings contradict previous studies ( non-directional hypothesis ). 4 In addition, hypotheses can 1) define interdependency between variables ( associative hypothesis ), 4 2) propose an effect on the dependent variable from manipulation of the independent variable ( causal hypothesis ), 4 3) state a negative relationship between two variables ( null hypothesis ), 4 , 11 , 15 4) replace the working hypothesis if rejected ( alternative hypothesis ), 15 explain the relationship of phenomena to possibly generate a theory ( working hypothesis ), 11 5) involve quantifiable variables that can be tested statistically ( statistical hypothesis ), 11 6) or express a relationship whose interlinks can be verified logically ( logical hypothesis ). 11 We provide examples of simple, complex, directional, non-directional, associative, causal, null, alternative, working, statistical, and logical hypotheses in quantitative research, as well as the definition of quantitative hypothesis-testing research in Table 3 .
| Quantitative research hypotheses | |
|---|---|
| Simple hypothesis | |
| - Predicts relationship between single dependent variable and single independent variable | |
| If the dose of the new medication (single independent variable) is high, blood pressure (single dependent variable) is lowered. | |
| Complex hypothesis | |
| - Foretells relationship between two or more independent and dependent variables | |
| The higher the use of anticancer drugs, radiation therapy, and adjunctive agents (3 independent variables), the higher would be the survival rate (1 dependent variable). | |
| Directional hypothesis | |
| - Identifies study direction based on theory towards particular outcome to clarify relationship between variables | |
| Privately funded research projects will have a larger international scope (study direction) than publicly funded research projects. | |
| Non-directional hypothesis | |
| - Nature of relationship between two variables or exact study direction is not identified | |
| - Does not involve a theory | |
| Women and men are different in terms of helpfulness. (Exact study direction is not identified) | |
| Associative hypothesis | |
| - Describes variable interdependency | |
| - Change in one variable causes change in another variable | |
| A larger number of people vaccinated against COVID-19 in the region (change in independent variable) will reduce the region’s incidence of COVID-19 infection (change in dependent variable). | |
| Causal hypothesis | |
| - An effect on dependent variable is predicted from manipulation of independent variable | |
| A change into a high-fiber diet (independent variable) will reduce the blood sugar level (dependent variable) of the patient. | |
| Null hypothesis | |
| - A negative statement indicating no relationship or difference between 2 variables | |
| There is no significant difference in the severity of pulmonary metastases between the new drug (variable 1) and the current drug (variable 2). | |
| Alternative hypothesis | |
| - Following a null hypothesis, an alternative hypothesis predicts a relationship between 2 study variables | |
| The new drug (variable 1) is better on average in reducing the level of pain from pulmonary metastasis than the current drug (variable 2). | |
| Working hypothesis | |
| - A hypothesis that is initially accepted for further research to produce a feasible theory | |
| Dairy cows fed with concentrates of different formulations will produce different amounts of milk. | |
| Statistical hypothesis | |
| - Assumption about the value of population parameter or relationship among several population characteristics | |
| - Validity tested by a statistical experiment or analysis | |
| The mean recovery rate from COVID-19 infection (value of population parameter) is not significantly different between population 1 and population 2. | |
| There is a positive correlation between the level of stress at the workplace and the number of suicides (population characteristics) among working people in Japan. | |
| Logical hypothesis | |
| - Offers or proposes an explanation with limited or no extensive evidence | |
| If healthcare workers provide more educational programs about contraception methods, the number of adolescent pregnancies will be less. | |
| Hypothesis-testing (Quantitative hypothesis-testing research) | |
| - Quantitative research uses deductive reasoning. | |
| - This involves the formation of a hypothesis, collection of data in the investigation of the problem, analysis and use of the data from the investigation, and drawing of conclusions to validate or nullify the hypotheses. | |
Research questions in qualitative research
Unlike research questions in quantitative research, research questions in qualitative research are usually continuously reviewed and reformulated. The central question and associated subquestions are stated more than the hypotheses. 15 The central question broadly explores a complex set of factors surrounding the central phenomenon, aiming to present the varied perspectives of participants. 15
There are varied goals for which qualitative research questions are developed. These questions can function in several ways, such as to 1) identify and describe existing conditions ( contextual research question s); 2) describe a phenomenon ( descriptive research questions ); 3) assess the effectiveness of existing methods, protocols, theories, or procedures ( evaluation research questions ); 4) examine a phenomenon or analyze the reasons or relationships between subjects or phenomena ( explanatory research questions ); or 5) focus on unknown aspects of a particular topic ( exploratory research questions ). 5 In addition, some qualitative research questions provide new ideas for the development of theories and actions ( generative research questions ) or advance specific ideologies of a position ( ideological research questions ). 1 Other qualitative research questions may build on a body of existing literature and become working guidelines ( ethnographic research questions ). Research questions may also be broadly stated without specific reference to the existing literature or a typology of questions ( phenomenological research questions ), may be directed towards generating a theory of some process ( grounded theory questions ), or may address a description of the case and the emerging themes ( qualitative case study questions ). 15 We provide examples of contextual, descriptive, evaluation, explanatory, exploratory, generative, ideological, ethnographic, phenomenological, grounded theory, and qualitative case study research questions in qualitative research in Table 4 , and the definition of qualitative hypothesis-generating research in Table 5 .
| Qualitative research questions | |
|---|---|
| Contextual research question | |
| - Ask the nature of what already exists | |
| - Individuals or groups function to further clarify and understand the natural context of real-world problems | |
| What are the experiences of nurses working night shifts in healthcare during the COVID-19 pandemic? (natural context of real-world problems) | |
| Descriptive research question | |
| - Aims to describe a phenomenon | |
| What are the different forms of disrespect and abuse (phenomenon) experienced by Tanzanian women when giving birth in healthcare facilities? | |
| Evaluation research question | |
| - Examines the effectiveness of existing practice or accepted frameworks | |
| How effective are decision aids (effectiveness of existing practice) in helping decide whether to give birth at home or in a healthcare facility? | |
| Explanatory research question | |
| - Clarifies a previously studied phenomenon and explains why it occurs | |
| Why is there an increase in teenage pregnancy (phenomenon) in Tanzania? | |
| Exploratory research question | |
| - Explores areas that have not been fully investigated to have a deeper understanding of the research problem | |
| What factors affect the mental health of medical students (areas that have not yet been fully investigated) during the COVID-19 pandemic? | |
| Generative research question | |
| - Develops an in-depth understanding of people’s behavior by asking ‘how would’ or ‘what if’ to identify problems and find solutions | |
| How would the extensive research experience of the behavior of new staff impact the success of the novel drug initiative? | |
| Ideological research question | |
| - Aims to advance specific ideas or ideologies of a position | |
| Are Japanese nurses who volunteer in remote African hospitals able to promote humanized care of patients (specific ideas or ideologies) in the areas of safe patient environment, respect of patient privacy, and provision of accurate information related to health and care? | |
| Ethnographic research question | |
| - Clarifies peoples’ nature, activities, their interactions, and the outcomes of their actions in specific settings | |
| What are the demographic characteristics, rehabilitative treatments, community interactions, and disease outcomes (nature, activities, their interactions, and the outcomes) of people in China who are suffering from pneumoconiosis? | |
| Phenomenological research question | |
| - Knows more about the phenomena that have impacted an individual | |
| What are the lived experiences of parents who have been living with and caring for children with a diagnosis of autism? (phenomena that have impacted an individual) | |
| Grounded theory question | |
| - Focuses on social processes asking about what happens and how people interact, or uncovering social relationships and behaviors of groups | |
| What are the problems that pregnant adolescents face in terms of social and cultural norms (social processes), and how can these be addressed? | |
| Qualitative case study question | |
| - Assesses a phenomenon using different sources of data to answer “why” and “how” questions | |
| - Considers how the phenomenon is influenced by its contextual situation. | |
| How does quitting work and assuming the role of a full-time mother (phenomenon assessed) change the lives of women in Japan? | |
| Qualitative research hypotheses | |
|---|---|
| Hypothesis-generating (Qualitative hypothesis-generating research) | |
| - Qualitative research uses inductive reasoning. | |
| - This involves data collection from study participants or the literature regarding a phenomenon of interest, using the collected data to develop a formal hypothesis, and using the formal hypothesis as a framework for testing the hypothesis. | |
| - Qualitative exploratory studies explore areas deeper, clarifying subjective experience and allowing formulation of a formal hypothesis potentially testable in a future quantitative approach. | |
Qualitative studies usually pose at least one central research question and several subquestions starting with How or What . These research questions use exploratory verbs such as explore or describe . These also focus on one central phenomenon of interest, and may mention the participants and research site. 15
Hypotheses in qualitative research
Hypotheses in qualitative research are stated in the form of a clear statement concerning the problem to be investigated. Unlike in quantitative research where hypotheses are usually developed to be tested, qualitative research can lead to both hypothesis-testing and hypothesis-generating outcomes. 2 When studies require both quantitative and qualitative research questions, this suggests an integrative process between both research methods wherein a single mixed-methods research question can be developed. 1
FRAMEWORKS FOR DEVELOPING RESEARCH QUESTIONS AND HYPOTHESES
Research questions followed by hypotheses should be developed before the start of the study. 1 , 12 , 14 It is crucial to develop feasible research questions on a topic that is interesting to both the researcher and the scientific community. This can be achieved by a meticulous review of previous and current studies to establish a novel topic. Specific areas are subsequently focused on to generate ethical research questions. The relevance of the research questions is evaluated in terms of clarity of the resulting data, specificity of the methodology, objectivity of the outcome, depth of the research, and impact of the study. 1 , 5 These aspects constitute the FINER criteria (i.e., Feasible, Interesting, Novel, Ethical, and Relevant). 1 Clarity and effectiveness are achieved if research questions meet the FINER criteria. In addition to the FINER criteria, Ratan et al. described focus, complexity, novelty, feasibility, and measurability for evaluating the effectiveness of research questions. 14
The PICOT and PEO frameworks are also used when developing research questions. 1 The following elements are addressed in these frameworks, PICOT: P-population/patients/problem, I-intervention or indicator being studied, C-comparison group, O-outcome of interest, and T-timeframe of the study; PEO: P-population being studied, E-exposure to preexisting conditions, and O-outcome of interest. 1 Research questions are also considered good if these meet the “FINERMAPS” framework: Feasible, Interesting, Novel, Ethical, Relevant, Manageable, Appropriate, Potential value/publishable, and Systematic. 14
As we indicated earlier, research questions and hypotheses that are not carefully formulated result in unethical studies or poor outcomes. To illustrate this, we provide some examples of ambiguous research question and hypotheses that result in unclear and weak research objectives in quantitative research ( Table 6 ) 16 and qualitative research ( Table 7 ) 17 , and how to transform these ambiguous research question(s) and hypothesis(es) into clear and good statements.
| Variables | Unclear and weak statement (Statement 1) | Clear and good statement (Statement 2) | Points to avoid |
|---|---|---|---|
| Research question | Which is more effective between smoke moxibustion and smokeless moxibustion? | “Moreover, regarding smoke moxibustion versus smokeless moxibustion, it remains unclear which is more effective, safe, and acceptable to pregnant women, and whether there is any difference in the amount of heat generated.” | 1) Vague and unfocused questions |
| 2) Closed questions simply answerable by yes or no | |||
| 3) Questions requiring a simple choice | |||
| Hypothesis | The smoke moxibustion group will have higher cephalic presentation. | “Hypothesis 1. The smoke moxibustion stick group (SM group) and smokeless moxibustion stick group (-SLM group) will have higher rates of cephalic presentation after treatment than the control group. | 1) Unverifiable hypotheses |
| Hypothesis 2. The SM group and SLM group will have higher rates of cephalic presentation at birth than the control group. | 2) Incompletely stated groups of comparison | ||
| Hypothesis 3. There will be no significant differences in the well-being of the mother and child among the three groups in terms of the following outcomes: premature birth, premature rupture of membranes (PROM) at < 37 weeks, Apgar score < 7 at 5 min, umbilical cord blood pH < 7.1, admission to neonatal intensive care unit (NICU), and intrauterine fetal death.” | 3) Insufficiently described variables or outcomes | ||
| Research objective | To determine which is more effective between smoke moxibustion and smokeless moxibustion. | “The specific aims of this pilot study were (a) to compare the effects of smoke moxibustion and smokeless moxibustion treatments with the control group as a possible supplement to ECV for converting breech presentation to cephalic presentation and increasing adherence to the newly obtained cephalic position, and (b) to assess the effects of these treatments on the well-being of the mother and child.” | 1) Poor understanding of the research question and hypotheses |
| 2) Insufficient description of population, variables, or study outcomes |
a These statements were composed for comparison and illustrative purposes only.
b These statements are direct quotes from Higashihara and Horiuchi. 16
| Variables | Unclear and weak statement (Statement 1) | Clear and good statement (Statement 2) | Points to avoid |
|---|---|---|---|
| Research question | Does disrespect and abuse (D&A) occur in childbirth in Tanzania? | How does disrespect and abuse (D&A) occur and what are the types of physical and psychological abuses observed in midwives’ actual care during facility-based childbirth in urban Tanzania? | 1) Ambiguous or oversimplistic questions |
| 2) Questions unverifiable by data collection and analysis | |||
| Hypothesis | Disrespect and abuse (D&A) occur in childbirth in Tanzania. | Hypothesis 1: Several types of physical and psychological abuse by midwives in actual care occur during facility-based childbirth in urban Tanzania. | 1) Statements simply expressing facts |
| Hypothesis 2: Weak nursing and midwifery management contribute to the D&A of women during facility-based childbirth in urban Tanzania. | 2) Insufficiently described concepts or variables | ||
| Research objective | To describe disrespect and abuse (D&A) in childbirth in Tanzania. | “This study aimed to describe from actual observations the respectful and disrespectful care received by women from midwives during their labor period in two hospitals in urban Tanzania.” | 1) Statements unrelated to the research question and hypotheses |
| 2) Unattainable or unexplorable objectives |
a This statement is a direct quote from Shimoda et al. 17
The other statements were composed for comparison and illustrative purposes only.
CONSTRUCTING RESEARCH QUESTIONS AND HYPOTHESES
To construct effective research questions and hypotheses, it is very important to 1) clarify the background and 2) identify the research problem at the outset of the research, within a specific timeframe. 9 Then, 3) review or conduct preliminary research to collect all available knowledge about the possible research questions by studying theories and previous studies. 18 Afterwards, 4) construct research questions to investigate the research problem. Identify variables to be accessed from the research questions 4 and make operational definitions of constructs from the research problem and questions. Thereafter, 5) construct specific deductive or inductive predictions in the form of hypotheses. 4 Finally, 6) state the study aims . This general flow for constructing effective research questions and hypotheses prior to conducting research is shown in Fig. 1 .

Research questions are used more frequently in qualitative research than objectives or hypotheses. 3 These questions seek to discover, understand, explore or describe experiences by asking “What” or “How.” The questions are open-ended to elicit a description rather than to relate variables or compare groups. The questions are continually reviewed, reformulated, and changed during the qualitative study. 3 Research questions are also used more frequently in survey projects than hypotheses in experiments in quantitative research to compare variables and their relationships.
Hypotheses are constructed based on the variables identified and as an if-then statement, following the template, ‘If a specific action is taken, then a certain outcome is expected.’ At this stage, some ideas regarding expectations from the research to be conducted must be drawn. 18 Then, the variables to be manipulated (independent) and influenced (dependent) are defined. 4 Thereafter, the hypothesis is stated and refined, and reproducible data tailored to the hypothesis are identified, collected, and analyzed. 4 The hypotheses must be testable and specific, 18 and should describe the variables and their relationships, the specific group being studied, and the predicted research outcome. 18 Hypotheses construction involves a testable proposition to be deduced from theory, and independent and dependent variables to be separated and measured separately. 3 Therefore, good hypotheses must be based on good research questions constructed at the start of a study or trial. 12
In summary, research questions are constructed after establishing the background of the study. Hypotheses are then developed based on the research questions. Thus, it is crucial to have excellent research questions to generate superior hypotheses. In turn, these would determine the research objectives and the design of the study, and ultimately, the outcome of the research. 12 Algorithms for building research questions and hypotheses are shown in Fig. 2 for quantitative research and in Fig. 3 for qualitative research.

EXAMPLES OF RESEARCH QUESTIONS FROM PUBLISHED ARTICLES
- EXAMPLE 1. Descriptive research question (quantitative research)
- - Presents research variables to be assessed (distinct phenotypes and subphenotypes)
- “BACKGROUND: Since COVID-19 was identified, its clinical and biological heterogeneity has been recognized. Identifying COVID-19 phenotypes might help guide basic, clinical, and translational research efforts.
- RESEARCH QUESTION: Does the clinical spectrum of patients with COVID-19 contain distinct phenotypes and subphenotypes? ” 19
- EXAMPLE 2. Relationship research question (quantitative research)
- - Shows interactions between dependent variable (static postural control) and independent variable (peripheral visual field loss)
- “Background: Integration of visual, vestibular, and proprioceptive sensations contributes to postural control. People with peripheral visual field loss have serious postural instability. However, the directional specificity of postural stability and sensory reweighting caused by gradual peripheral visual field loss remain unclear.
- Research question: What are the effects of peripheral visual field loss on static postural control ?” 20
- EXAMPLE 3. Comparative research question (quantitative research)
- - Clarifies the difference among groups with an outcome variable (patients enrolled in COMPERA with moderate PH or severe PH in COPD) and another group without the outcome variable (patients with idiopathic pulmonary arterial hypertension (IPAH))
- “BACKGROUND: Pulmonary hypertension (PH) in COPD is a poorly investigated clinical condition.
- RESEARCH QUESTION: Which factors determine the outcome of PH in COPD?
- STUDY DESIGN AND METHODS: We analyzed the characteristics and outcome of patients enrolled in the Comparative, Prospective Registry of Newly Initiated Therapies for Pulmonary Hypertension (COMPERA) with moderate or severe PH in COPD as defined during the 6th PH World Symposium who received medical therapy for PH and compared them with patients with idiopathic pulmonary arterial hypertension (IPAH) .” 21
- EXAMPLE 4. Exploratory research question (qualitative research)
- - Explores areas that have not been fully investigated (perspectives of families and children who receive care in clinic-based child obesity treatment) to have a deeper understanding of the research problem
- “Problem: Interventions for children with obesity lead to only modest improvements in BMI and long-term outcomes, and data are limited on the perspectives of families of children with obesity in clinic-based treatment. This scoping review seeks to answer the question: What is known about the perspectives of families and children who receive care in clinic-based child obesity treatment? This review aims to explore the scope of perspectives reported by families of children with obesity who have received individualized outpatient clinic-based obesity treatment.” 22
- EXAMPLE 5. Relationship research question (quantitative research)
- - Defines interactions between dependent variable (use of ankle strategies) and independent variable (changes in muscle tone)
- “Background: To maintain an upright standing posture against external disturbances, the human body mainly employs two types of postural control strategies: “ankle strategy” and “hip strategy.” While it has been reported that the magnitude of the disturbance alters the use of postural control strategies, it has not been elucidated how the level of muscle tone, one of the crucial parameters of bodily function, determines the use of each strategy. We have previously confirmed using forward dynamics simulations of human musculoskeletal models that an increased muscle tone promotes the use of ankle strategies. The objective of the present study was to experimentally evaluate a hypothesis: an increased muscle tone promotes the use of ankle strategies. Research question: Do changes in the muscle tone affect the use of ankle strategies ?” 23
EXAMPLES OF HYPOTHESES IN PUBLISHED ARTICLES
- EXAMPLE 1. Working hypothesis (quantitative research)
- - A hypothesis that is initially accepted for further research to produce a feasible theory
- “As fever may have benefit in shortening the duration of viral illness, it is plausible to hypothesize that the antipyretic efficacy of ibuprofen may be hindering the benefits of a fever response when taken during the early stages of COVID-19 illness .” 24
- “In conclusion, it is plausible to hypothesize that the antipyretic efficacy of ibuprofen may be hindering the benefits of a fever response . The difference in perceived safety of these agents in COVID-19 illness could be related to the more potent efficacy to reduce fever with ibuprofen compared to acetaminophen. Compelling data on the benefit of fever warrant further research and review to determine when to treat or withhold ibuprofen for early stage fever for COVID-19 and other related viral illnesses .” 24
- EXAMPLE 2. Exploratory hypothesis (qualitative research)
- - Explores particular areas deeper to clarify subjective experience and develop a formal hypothesis potentially testable in a future quantitative approach
- “We hypothesized that when thinking about a past experience of help-seeking, a self distancing prompt would cause increased help-seeking intentions and more favorable help-seeking outcome expectations .” 25
- “Conclusion
- Although a priori hypotheses were not supported, further research is warranted as results indicate the potential for using self-distancing approaches to increasing help-seeking among some people with depressive symptomatology.” 25
- EXAMPLE 3. Hypothesis-generating research to establish a framework for hypothesis testing (qualitative research)
- “We hypothesize that compassionate care is beneficial for patients (better outcomes), healthcare systems and payers (lower costs), and healthcare providers (lower burnout). ” 26
- Compassionomics is the branch of knowledge and scientific study of the effects of compassionate healthcare. Our main hypotheses are that compassionate healthcare is beneficial for (1) patients, by improving clinical outcomes, (2) healthcare systems and payers, by supporting financial sustainability, and (3) HCPs, by lowering burnout and promoting resilience and well-being. The purpose of this paper is to establish a scientific framework for testing the hypotheses above . If these hypotheses are confirmed through rigorous research, compassionomics will belong in the science of evidence-based medicine, with major implications for all healthcare domains.” 26
- EXAMPLE 4. Statistical hypothesis (quantitative research)
- - An assumption is made about the relationship among several population characteristics ( gender differences in sociodemographic and clinical characteristics of adults with ADHD ). Validity is tested by statistical experiment or analysis ( chi-square test, Students t-test, and logistic regression analysis)
- “Our research investigated gender differences in sociodemographic and clinical characteristics of adults with ADHD in a Japanese clinical sample. Due to unique Japanese cultural ideals and expectations of women's behavior that are in opposition to ADHD symptoms, we hypothesized that women with ADHD experience more difficulties and present more dysfunctions than men . We tested the following hypotheses: first, women with ADHD have more comorbidities than men with ADHD; second, women with ADHD experience more social hardships than men, such as having less full-time employment and being more likely to be divorced.” 27
- “Statistical Analysis
- ( text omitted ) Between-gender comparisons were made using the chi-squared test for categorical variables and Students t-test for continuous variables…( text omitted ). A logistic regression analysis was performed for employment status, marital status, and comorbidity to evaluate the independent effects of gender on these dependent variables.” 27
EXAMPLES OF HYPOTHESIS AS WRITTEN IN PUBLISHED ARTICLES IN RELATION TO OTHER PARTS
- EXAMPLE 1. Background, hypotheses, and aims are provided
- “Pregnant women need skilled care during pregnancy and childbirth, but that skilled care is often delayed in some countries …( text omitted ). The focused antenatal care (FANC) model of WHO recommends that nurses provide information or counseling to all pregnant women …( text omitted ). Job aids are visual support materials that provide the right kind of information using graphics and words in a simple and yet effective manner. When nurses are not highly trained or have many work details to attend to, these job aids can serve as a content reminder for the nurses and can be used for educating their patients (Jennings, Yebadokpo, Affo, & Agbogbe, 2010) ( text omitted ). Importantly, additional evidence is needed to confirm how job aids can further improve the quality of ANC counseling by health workers in maternal care …( text omitted )” 28
- “ This has led us to hypothesize that the quality of ANC counseling would be better if supported by job aids. Consequently, a better quality of ANC counseling is expected to produce higher levels of awareness concerning the danger signs of pregnancy and a more favorable impression of the caring behavior of nurses .” 28
- “This study aimed to examine the differences in the responses of pregnant women to a job aid-supported intervention during ANC visit in terms of 1) their understanding of the danger signs of pregnancy and 2) their impression of the caring behaviors of nurses to pregnant women in rural Tanzania.” 28
- EXAMPLE 2. Background, hypotheses, and aims are provided
- “We conducted a two-arm randomized controlled trial (RCT) to evaluate and compare changes in salivary cortisol and oxytocin levels of first-time pregnant women between experimental and control groups. The women in the experimental group touched and held an infant for 30 min (experimental intervention protocol), whereas those in the control group watched a DVD movie of an infant (control intervention protocol). The primary outcome was salivary cortisol level and the secondary outcome was salivary oxytocin level.” 29
- “ We hypothesize that at 30 min after touching and holding an infant, the salivary cortisol level will significantly decrease and the salivary oxytocin level will increase in the experimental group compared with the control group .” 29
- EXAMPLE 3. Background, aim, and hypothesis are provided
- “In countries where the maternal mortality ratio remains high, antenatal education to increase Birth Preparedness and Complication Readiness (BPCR) is considered one of the top priorities [1]. BPCR includes birth plans during the antenatal period, such as the birthplace, birth attendant, transportation, health facility for complications, expenses, and birth materials, as well as family coordination to achieve such birth plans. In Tanzania, although increasing, only about half of all pregnant women attend an antenatal clinic more than four times [4]. Moreover, the information provided during antenatal care (ANC) is insufficient. In the resource-poor settings, antenatal group education is a potential approach because of the limited time for individual counseling at antenatal clinics.” 30
- “This study aimed to evaluate an antenatal group education program among pregnant women and their families with respect to birth-preparedness and maternal and infant outcomes in rural villages of Tanzania.” 30
- “ The study hypothesis was if Tanzanian pregnant women and their families received a family-oriented antenatal group education, they would (1) have a higher level of BPCR, (2) attend antenatal clinic four or more times, (3) give birth in a health facility, (4) have less complications of women at birth, and (5) have less complications and deaths of infants than those who did not receive the education .” 30
Research questions and hypotheses are crucial components to any type of research, whether quantitative or qualitative. These questions should be developed at the very beginning of the study. Excellent research questions lead to superior hypotheses, which, like a compass, set the direction of research, and can often determine the successful conduct of the study. Many research studies have floundered because the development of research questions and subsequent hypotheses was not given the thought and meticulous attention needed. The development of research questions and hypotheses is an iterative process based on extensive knowledge of the literature and insightful grasp of the knowledge gap. Focused, concise, and specific research questions provide a strong foundation for constructing hypotheses which serve as formal predictions about the research outcomes. Research questions and hypotheses are crucial elements of research that should not be overlooked. They should be carefully thought of and constructed when planning research. This avoids unethical studies and poor outcomes by defining well-founded objectives that determine the design, course, and outcome of the study.
Disclosure: The authors have no potential conflicts of interest to disclose.
Author Contributions:
- Conceptualization: Barroga E, Matanguihan GJ.
- Methodology: Barroga E, Matanguihan GJ.
- Writing - original draft: Barroga E, Matanguihan GJ.
- Writing - review & editing: Barroga E, Matanguihan GJ.
- Search Search Please fill out this field.
What Is Hypothesis Testing?
- How It Works
4 Step Process
The bottom line.
- Fundamental Analysis
Hypothesis Testing: 4 Steps and Example
:max_bytes(150000):strip_icc():format(webp)/ChristinaMajaski-5c9433ea46e0fb0001d880b1.jpeg "hypothesis testing in basic research")
Hypothesis testing, sometimes called significance testing, is an act in statistics whereby an analyst tests an assumption regarding a population parameter. The methodology employed by the analyst depends on the nature of the data used and the reason for the analysis.
Hypothesis testing is used to assess the plausibility of a hypothesis by using sample data. Such data may come from a larger population or a data-generating process. The word "population" will be used for both of these cases in the following descriptions.
Key Takeaways
- Hypothesis testing is used to assess the plausibility of a hypothesis by using sample data.
- The test provides evidence concerning the plausibility of the hypothesis, given the data.
- Statistical analysts test a hypothesis by measuring and examining a random sample of the population being analyzed.
- The four steps of hypothesis testing include stating the hypotheses, formulating an analysis plan, analyzing the sample data, and analyzing the result.
How Hypothesis Testing Works
In hypothesis testing, an analyst tests a statistical sample, intending to provide evidence on the plausibility of the null hypothesis. Statistical analysts measure and examine a random sample of the population being analyzed. All analysts use a random population sample to test two different hypotheses: the null hypothesis and the alternative hypothesis.
The null hypothesis is usually a hypothesis of equality between population parameters; e.g., a null hypothesis may state that the population mean return is equal to zero. The alternative hypothesis is effectively the opposite of a null hypothesis. Thus, they are mutually exclusive , and only one can be true. However, one of the two hypotheses will always be true.
The null hypothesis is a statement about a population parameter, such as the population mean, that is assumed to be true.
- State the hypotheses.
- Formulate an analysis plan, which outlines how the data will be evaluated.
- Carry out the plan and analyze the sample data.
- Analyze the results and either reject the null hypothesis, or state that the null hypothesis is plausible, given the data.
Example of Hypothesis Testing
If an individual wants to test that a penny has exactly a 50% chance of landing on heads, the null hypothesis would be that 50% is correct, and the alternative hypothesis would be that 50% is not correct. Mathematically, the null hypothesis is represented as Ho: P = 0.5. The alternative hypothesis is shown as "Ha" and is identical to the null hypothesis, except with the equal sign struck-through, meaning that it does not equal 50%.
A random sample of 100 coin flips is taken, and the null hypothesis is tested. If it is found that the 100 coin flips were distributed as 40 heads and 60 tails, the analyst would assume that a penny does not have a 50% chance of landing on heads and would reject the null hypothesis and accept the alternative hypothesis.
If there were 48 heads and 52 tails, then it is plausible that the coin could be fair and still produce such a result. In cases such as this where the null hypothesis is "accepted," the analyst states that the difference between the expected results (50 heads and 50 tails) and the observed results (48 heads and 52 tails) is "explainable by chance alone."
When Did Hypothesis Testing Begin?
Some statisticians attribute the first hypothesis tests to satirical writer John Arbuthnot in 1710, who studied male and female births in England after observing that in nearly every year, male births exceeded female births by a slight proportion. Arbuthnot calculated that the probability of this happening by chance was small, and therefore it was due to “divine providence.”
What are the Benefits of Hypothesis Testing?
Hypothesis testing helps assess the accuracy of new ideas or theories by testing them against data. This allows researchers to determine whether the evidence supports their hypothesis, helping to avoid false claims and conclusions. Hypothesis testing also provides a framework for decision-making based on data rather than personal opinions or biases. By relying on statistical analysis, hypothesis testing helps to reduce the effects of chance and confounding variables, providing a robust framework for making informed conclusions.
What are the Limitations of Hypothesis Testing?
Hypothesis testing relies exclusively on data and doesn’t provide a comprehensive understanding of the subject being studied. Additionally, the accuracy of the results depends on the quality of the available data and the statistical methods used. Inaccurate data or inappropriate hypothesis formulation may lead to incorrect conclusions or failed tests. Hypothesis testing can also lead to errors, such as analysts either accepting or rejecting a null hypothesis when they shouldn’t have. These errors may result in false conclusions or missed opportunities to identify significant patterns or relationships in the data.
Hypothesis testing refers to a statistical process that helps researchers determine the reliability of a study. By using a well-formulated hypothesis and set of statistical tests, individuals or businesses can make inferences about the population that they are studying and draw conclusions based on the data presented. All hypothesis testing methods have the same four-step process, which includes stating the hypotheses, formulating an analysis plan, analyzing the sample data, and analyzing the result.
Sage. " Introduction to Hypothesis Testing ," Page 4.
Elder Research. " Who Invented the Null Hypothesis? "
Formplus. " Hypothesis Testing: Definition, Uses, Limitations and Examples ."
:max_bytes(150000):strip_icc():format(webp)/stresstesting.asp-final-b2577fb8ba804e1fa1069b8bd96bf3bc.png "hypothesis testing in basic research")
- Terms of Service
- Editorial Policy
- Privacy Policy
Hypothesis testing
When interpreting research findings, researchers need to assess whether these findings may have occurred by chance. Hypothesis testing is a systematic procedure for deciding whether the results of a research study support a particular theory which applies to a population.
Hypothesis testing uses sample data to evaluate a hypothesis about a population . A hypothesis test assesses how unusual the result is, whether it is reasonable chance variation or whether the result is too extreme to be considered chance variation.
Basic concepts
- Null and research hypothesis
Probability value and types of errors
Effect size and statistical significance.
- Directional and non-directional hypotheses
Null and research hypotheses
To carry out statistical hypothesis testing, research and null hypothesis are employed:
- Research hypothesis : this is the hypothesis that you propose, also known as the alternative hypothesis HA. For example:
H A: There is a relationship between intelligence and academic results.
H A: First year university students obtain higher grades after an intensive Statistics course.
H A; Males and females differ in their levels of stress.
- The null hypothesis (H o ) is the opposite of the research hypothesis and expresses that there is no relationship between variables, or no differences between groups; for example:
H o : There is no relationship between intelligence and academic results.
H o: First year university students do not obtain higher grades after an intensive Statistics course.
H o : Males and females will not differ in their levels of stress.
The purpose of hypothesis testing is to test whether the null hypothesis (there is no difference, no effect) can be rejected or approved. If the null hypothesis is rejected, then the research hypothesis can be accepted. If the null hypothesis is accepted, then the research hypothesis is rejected.
In hypothesis testing, a value is set to assess whether the null hypothesis is accepted or rejected and whether the result is statistically significant:
- A critical value is the score the sample would need to decide against the null hypothesis.
- A probability value is used to assess the significance of the statistical test. If the null hypothesis is rejected, then the alternative to the null hypothesis is accepted.
The probability value, or p value , is the probability of an outcome or research result given the hypothesis. Usually, the probability value is set at 0.05: the null hypothesis will be rejected if the probability value of the statistical test is less than 0.05. There are two types of errors associated to hypothesis testing:
- What if we observe a difference – but none exists in the population?
- What if we do not find a difference – but it does exist in the population?
These situations are known as Type I and Type II errors:
- Type I Error: is the type of error that involves the rejection of a null hypothesis that is actually true (i.e. a false positive).
- Type II Error: is the type of error that occurs when we do not reject a null hypothesis that is false (i.e. a false negative).

These errors cannot be eliminated; they can be minimised, but minimising one type of error will increase the probability of committing the other type.
The probability of making a Type I error depends on the criterion that is used to accept or reject the null hypothesis: the p value or alpha level . The alpha is set by the researcher, usually at .05, and is the chance the researcher is willing to take and still claim the significance of the statistical test.). Choosing a smaller alpha level will decrease the likelihood of committing Type I error.
For example, p<0.05 indicates that there are 5 chances in 100 that the difference observed was really due to sampling error – that 5% of the time a Type I error will occur or that there is a 5% chance that the opposite of the null hypothesis is actually true.
With a p<0.01, there will be 1 chance in 100 that the difference observed was really due to sampling error – 1% of the time a Type I error will occur.
The p level is specified before analysing the data. If the data analysis results in a probability value below the α (alpha) level, then the null hypothesis is rejected; if it is not, then the null hypothesis is not rejected.
When the null hypothesis is rejected, the effect is said to be statistically significant. However, statistical significance does not mean that the effect is important.
A result can be statistically significant, but the effect size may be small. Finding that an effect is significant does not provide information about how large or important the effect is. In fact, a small effect can be statistically significant if the sample size is large enough.
Information about the effect size, or magnitude of the result, is given by the statistical test. For example, the strength of the correlation between two variables is given by the coefficient of correlation, which varies from 0 to 1.
- A hypothesis that states that students who attend an intensive Statistics course will obtain higher grades than students who do not attend would be directional.
- A non-directional hypothesis states that there will be differences between students who attend do or don’t attend an intensive Statistics course, but we don’t know what group will get higher grades than the other. The hypothesis only states that they will obtain different grades.
The hypothesis testing process
The hypothesis testing process can be divided into five steps:
- Restate the research question as research hypothesis and a null hypothesis about the populations.
- Determine the characteristics of the comparison distribution.
- Determine the cut off sample score on the comparison distribution at which the null hypothesis should be rejected.
- Determine your sample’s score on the comparison distribution.
- Decide whether to reject the null hypothesis.
This example illustrates how these five steps can be applied to text a hypothesis:
- Let’s say that you conduct an experiment to investigate whether students’ ability to memorise words improves after they have consumed caffeine.
- The experiment involves two groups of students: the first group consumes caffeine; the second group drinks water.
- Both groups complete a memory test.
- A randomly selected individual in the experimental condition (i.e. the group that consumes caffeine) has a score of 27 on the memory test. The scores of people in general on this memory measure are normally distributed with a mean of 19 and a standard deviation of 4.
- The researcher predicts an effect (differences in memory for these groups) but does not predict a particular direction of effect (i.e. which group will have higher scores on the memory test). Using the 5% significance level, what should you conclude?
Step 1 : There are two populations of interest.
Population 1: People who go through the experimental procedure (drink coffee).
Population 2: People who do not go through the experimental procedure (drink water).
- Research hypothesis: Population 1 will score differently from Population 2.
- Null hypothesis: There will be no difference between the two populations.
Step 2 : We know that the characteristics of the comparison distribution (student population) are:
Population M = 19, Population SD= 4, normally distributed. These are the mean and standard deviation of the distribution of scores on the memory test for the general student population.
Step 3 : For a two-tailed test (the direction of the effect is not specified) at the 5% level (25% at each tail), the cut off sample scores are +1.96 and -1.99.
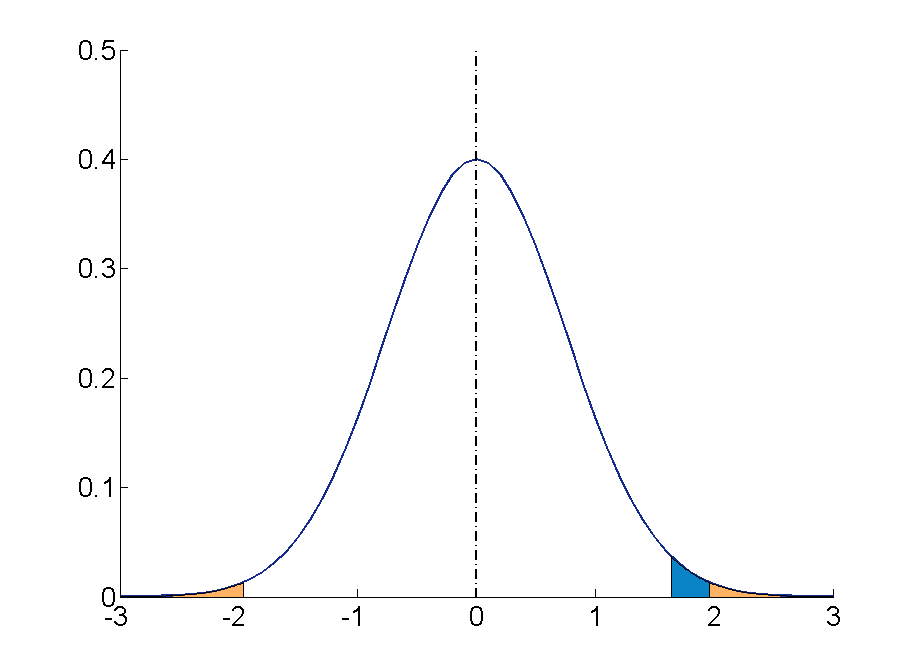
Step 4 : Your sample score of 27 needs to be converted into a Z value. To calculate Z = (27-19)/4= 2 ( check the Converting into Z scores section if you need to review how to do this process)
Step 5 : A ‘Z’ score of 2 is more extreme than the cut off Z of +1.96 (see figure above). The result is significant and, thus, the null hypothesis is rejected.
You can find more examples here:
- Statistics (RMIT Learning Lab)
Some commonly used statistical techniques
Correlation analysis, multiple regression.
- Analysis of variance
Chi-square test for independence
Correlation analysis explores the association between variables . The purpose of correlational analysis is to discover whether there is a relationship between variables, which is unlikely to occur by sampling error. The null hypothesis is that there is no relationship between the two variables. Correlation analysis provides information about:
- The direction of the relationship: positive or negative- given by the sign of the correlation coefficient.
- The strength or magnitude of the relationship between the two variables- given by the correlation coefficient, which varies from 0 (no relationship between the variables) to 1 (perfect relationship between the variables).
- Direction of the relationship.
A positive correlation indicates that high scores on one variable are associated with high scores on the other variable; low scores on one variable are associated with low scores on the second variable . For instance, in the figure below, higher scores on negative affect are associated with higher scores on perceived stress

A negative correlation indicates that high scores on one variable are associated with low scores on the other variable. The graph shows that a person who scores high on perceived stress will probably score low on mastery. The slope of the graph is downwards- as it moves to the right. In the figure below, higher scores on mastery are associated with lower scores on perceived stress.

Fig 2. Negative correlation between two variables. Adapted from Pallant, J. (2013). SPSS survival manual: A step by step guide to data analysis using IBM SPSS (5th ed.). Sydney, Melbourne, Auckland, London: Allen & Unwin
2. The strength or magnitude of the relationship
The strength of a linear relationship between two variables is measured by a statistic known as the correlation coefficient , which varies from 0 to -1, and from 0 to +1. There are several correlation coefficients; the most widely used are Pearson’s r and Spearman’s rho. The strength of the relationship is interpreted as follows:
- Small/weak: r= .10 to .29
- Medium/moderate: r= .30 to .49
- Large/strong: r= .50 to 1
It is important to note that correlation analysis does not imply causality. Correlation is used to explore the association between variables, however, it does not indicate that one variable causes the other. The correlation between two variables could be due to the fact that a third variable is affecting the two variables.
Multiple regression is an extension of correlation analysis. Multiple regression is used to explore the relationship between one dependent variable and a number of independent variables or predictors . The purpose of a multiple regression model is to predict values of a dependent variable based on the values of the independent variables or predictors. For example, a researcher may be interested in predicting students’ academic success (e.g. grades) based on a number of predictors, for example, hours spent studying, satisfaction with studies, relationships with peers and lecturers.
A multiple regression model can be conducted using statistical software (e.g. SPSS). The software will test the significance of the model (i.e. does the model significantly predicts scores on the dependent variable using the independent variables introduced in the model?), how much of the variance in the dependent variable is explained by the model, and the individual contribution of each independent variable.
Example of multiple regression model

From Dunn et al. (2014). Influence of academic self-regulation, critical thinking, and age on online graduate students' academic help-seeking.
In this model, help-seeking is the dependent variable; there are three independent variables or predictors. The coefficients show the direction (positive or negative) and magnitude of the relationship between each predictor and the dependent variable. The model was statistically significant and predicted 13.5% of the variance in help-seeking.
t-Tests are employed to compare the mean score on some continuous variable for two groups . The null hypothesis to be tested is there are no differences between the two groups (e.g. anxiety scores for males and females are not different).
If the significance value of the t-test is equal or less than .05, there is a significant difference in the mean scores on the variable of interest for each of the two groups. If the value is above .05, there is no significant difference between the groups.
t-Tests can be employed to compare the mean scores of two different groups (independent-samples t-test ) or to compare the same group of people on two different occasions ( paired-samples t-test) .
In addition to assessing whether the difference between the two groups is statistically significant, it is important to consider the effect size or magnitude of the difference between the groups. The effect size is given by partial eta squared (proportion of variance of the dependent variable that is explained by the independent variable) and Cohen’s d (difference between groups in terms of standard deviation units).
In this example, an independent samples t-test was conducted to assess whether males and females differ in their perceived anxiety levels. The significance of the test is .004. Since this value is less than .05, we can conclude that there is a statistically significant difference between males and females in their perceived anxiety levels.

Whilst t-tests compare the mean score on one variable for two groups, analysis of variance is used to test more than two groups . Following the previous example, analysis of variance would be employed to test whether there are differences in anxiety scores for students from different disciplines.
Analysis of variance compare the variance (variability in scores) between the different groups (believed to be due to the independent variable) with the variability within each group (believed to be due to chance). An F ratio is calculated; a large F ratio indicates that there is more variability between the groups (caused by the independent variable) than there is within each group (error term). A significant F test indicates that we can reject the null hypothesis; i.e. that there is no difference between the groups.
Again, effect size statistics such as Cohen’s d and eta squared are employed to assess the magnitude of the differences between groups.
In this example, we examined differences in perceived anxiety between students from different disciplines. The results of the Anova Test show that the significance level is .005. Since this value is below .05, we can conclude that there are statistically significant differences between students from different disciplines in their perceived anxiety levels.

Chi-square test for independence is used to explore the relationship between two categorical variables. Each variable can have two or more categories.
For example, a researcher can use a Chi-square test for independence to assess the relationship between study disciplines (e.g. Psychology, Business, Education,…) and help-seeking behaviour (Yes/No). The test compares the observed frequencies of cases with the values that would be expected if there was no association between the two variables of interest. A statistically significant Chi-square test indicates that the two variables are associated (e.g. Psychology students are more likely to seek help than Business students). The effect size is assessed using effect size statistics: Phi and Cramer’s V .
In this example, a Chi-square test was conducted to assess whether males and females differ in their help-seeking behaviour (Yes/No). The crosstabulation table shows the percentage of males of females who sought/didn't seek help. The table 'Chi square tests' shows the significance of the test (Pearson Chi square asymp sig: .482). Since this value is above .05, we conclude that there is no statistically significant difference between males and females in their help-seeking behaviour.

- << Previous: Probability and the normal distribution
- Next: Statistical techniques >>
- Data Science
- Data Analysis
- Data Visualization
- Machine Learning
- Deep Learning
- Computer Vision
- Artificial Intelligence
- AI ML DS Interview Series
- AI ML DS Projects series
- Data Engineering
- Web Scrapping
Understanding Hypothesis Testing
Hypothesis testing involves formulating assumptions about population parameters based on sample statistics and rigorously evaluating these assumptions against empirical evidence. This article sheds light on the significance of hypothesis testing and the critical steps involved in the process.
What is Hypothesis Testing?
A hypothesis is an assumption or idea, specifically a statistical claim about an unknown population parameter. For example, a judge assumes a person is innocent and verifies this by reviewing evidence and hearing testimony before reaching a verdict.
Hypothesis testing is a statistical method that is used to make a statistical decision using experimental data. Hypothesis testing is basically an assumption that we make about a population parameter. It evaluates two mutually exclusive statements about a population to determine which statement is best supported by the sample data.
To test the validity of the claim or assumption about the population parameter:
- A sample is drawn from the population and analyzed.
- The results of the analysis are used to decide whether the claim is true or not.
Example: You say an average height in the class is 30 or a boy is taller than a girl. All of these is an assumption that we are assuming, and we need some statistical way to prove these. We need some mathematical conclusion whatever we are assuming is true.
Defining Hypotheses
- Null hypothesis (H 0 ): In statistics, the null hypothesis is a general statement or default position that there is no relationship between two measured cases or no relationship among groups. In other words, it is a basic assumption or made based on the problem knowledge. Example : A company’s mean production is 50 units/per da H 0 : [Tex]\mu [/Tex] = 50.
- Alternative hypothesis (H 1 ): The alternative hypothesis is the hypothesis used in hypothesis testing that is contrary to the null hypothesis. Example: A company’s production is not equal to 50 units/per day i.e. H 1 : [Tex]\mu [/Tex] [Tex]\ne [/Tex] 50.
Key Terms of Hypothesis Testing
- Level of significance : It refers to the degree of significance in which we accept or reject the null hypothesis. 100% accuracy is not possible for accepting a hypothesis, so we, therefore, select a level of significance that is usually 5%. This is normally denoted with [Tex]\alpha[/Tex] and generally, it is 0.05 or 5%, which means your output should be 95% confident to give a similar kind of result in each sample.
- P-value: The P value , or calculated probability, is the probability of finding the observed/extreme results when the null hypothesis(H0) of a study-given problem is true. If your P-value is less than the chosen significance level then you reject the null hypothesis i.e. accept that your sample claims to support the alternative hypothesis.
- Test Statistic: The test statistic is a numerical value calculated from sample data during a hypothesis test, used to determine whether to reject the null hypothesis. It is compared to a critical value or p-value to make decisions about the statistical significance of the observed results.
- Critical value : The critical value in statistics is a threshold or cutoff point used to determine whether to reject the null hypothesis in a hypothesis test.
- Degrees of freedom: Degrees of freedom are associated with the variability or freedom one has in estimating a parameter. The degrees of freedom are related to the sample size and determine the shape.
Why do we use Hypothesis Testing?
Hypothesis testing is an important procedure in statistics. Hypothesis testing evaluates two mutually exclusive population statements to determine which statement is most supported by sample data. When we say that the findings are statistically significant, thanks to hypothesis testing.
One-Tailed and Two-Tailed Test
One tailed test focuses on one direction, either greater than or less than a specified value. We use a one-tailed test when there is a clear directional expectation based on prior knowledge or theory. The critical region is located on only one side of the distribution curve. If the sample falls into this critical region, the null hypothesis is rejected in favor of the alternative hypothesis.
One-Tailed Test
There are two types of one-tailed test:
- Left-Tailed (Left-Sided) Test: The alternative hypothesis asserts that the true parameter value is less than the null hypothesis. Example: H 0 : [Tex]\mu \geq 50 [/Tex] and H 1 : [Tex]\mu < 50 [/Tex]
- Right-Tailed (Right-Sided) Test : The alternative hypothesis asserts that the true parameter value is greater than the null hypothesis. Example: H 0 : [Tex]\mu \leq50 [/Tex] and H 1 : [Tex]\mu > 50 [/Tex]
Two-Tailed Test
A two-tailed test considers both directions, greater than and less than a specified value.We use a two-tailed test when there is no specific directional expectation, and want to detect any significant difference.
Example: H 0 : [Tex]\mu = [/Tex] 50 and H 1 : [Tex]\mu \neq 50 [/Tex]
To delve deeper into differences into both types of test: Refer to link
What are Type 1 and Type 2 errors in Hypothesis Testing?
In hypothesis testing, Type I and Type II errors are two possible errors that researchers can make when drawing conclusions about a population based on a sample of data. These errors are associated with the decisions made regarding the null hypothesis and the alternative hypothesis.
- Type I error: When we reject the null hypothesis, although that hypothesis was true. Type I error is denoted by alpha( [Tex]\alpha [/Tex] ).
- Type II errors : When we accept the null hypothesis, but it is false. Type II errors are denoted by beta( [Tex]\beta [/Tex] ).
Null Hypothesis is True | Null Hypothesis is False | |
|---|---|---|
Null Hypothesis is True (Accept) | Correct Decision | Type II Error (False Negative) |
Alternative Hypothesis is True (Reject) | Type I Error (False Positive) | Correct Decision |
How does Hypothesis Testing work?
Step 1: define null and alternative hypothesis.
State the null hypothesis ( [Tex]H_0 [/Tex] ), representing no effect, and the alternative hypothesis ( [Tex]H_1 [/Tex] ), suggesting an effect or difference.
We first identify the problem about which we want to make an assumption keeping in mind that our assumption should be contradictory to one another, assuming Normally distributed data.
Step 2 – Choose significance level
Select a significance level ( [Tex]\alpha [/Tex] ), typically 0.05, to determine the threshold for rejecting the null hypothesis. It provides validity to our hypothesis test, ensuring that we have sufficient data to back up our claims. Usually, we determine our significance level beforehand of the test. The p-value is the criterion used to calculate our significance value.
Step 3 – Collect and Analyze data.
Gather relevant data through observation or experimentation. Analyze the data using appropriate statistical methods to obtain a test statistic.
Step 4-Calculate Test Statistic
The data for the tests are evaluated in this step we look for various scores based on the characteristics of data. The choice of the test statistic depends on the type of hypothesis test being conducted.
There are various hypothesis tests, each appropriate for various goal to calculate our test. This could be a Z-test , Chi-square , T-test , and so on.
- Z-test : If population means and standard deviations are known. Z-statistic is commonly used.
- t-test : If population standard deviations are unknown. and sample size is small than t-test statistic is more appropriate.
- Chi-square test : Chi-square test is used for categorical data or for testing independence in contingency tables
- F-test : F-test is often used in analysis of variance (ANOVA) to compare variances or test the equality of means across multiple groups.
We have a smaller dataset, So, T-test is more appropriate to test our hypothesis.
T-statistic is a measure of the difference between the means of two groups relative to the variability within each group. It is calculated as the difference between the sample means divided by the standard error of the difference. It is also known as the t-value or t-score.
Step 5 – Comparing Test Statistic:
In this stage, we decide where we should accept the null hypothesis or reject the null hypothesis. There are two ways to decide where we should accept or reject the null hypothesis.
Method A: Using Crtical values
Comparing the test statistic and tabulated critical value we have,
- If Test Statistic>Critical Value: Reject the null hypothesis.
- If Test Statistic≤Critical Value: Fail to reject the null hypothesis.
Note: Critical values are predetermined threshold values that are used to make a decision in hypothesis testing. To determine critical values for hypothesis testing, we typically refer to a statistical distribution table , such as the normal distribution or t-distribution tables based on.
Method B: Using P-values
We can also come to an conclusion using the p-value,
- If the p-value is less than or equal to the significance level i.e. ( [Tex]p\leq\alpha [/Tex] ), you reject the null hypothesis. This indicates that the observed results are unlikely to have occurred by chance alone, providing evidence in favor of the alternative hypothesis.
- If the p-value is greater than the significance level i.e. ( [Tex]p\geq \alpha[/Tex] ), you fail to reject the null hypothesis. This suggests that the observed results are consistent with what would be expected under the null hypothesis.
Note : The p-value is the probability of obtaining a test statistic as extreme as, or more extreme than, the one observed in the sample, assuming the null hypothesis is true. To determine p-value for hypothesis testing, we typically refer to a statistical distribution table , such as the normal distribution or t-distribution tables based on.
Step 7- Interpret the Results
At last, we can conclude our experiment using method A or B.
Calculating test statistic
To validate our hypothesis about a population parameter we use statistical functions . We use the z-score, p-value, and level of significance(alpha) to make evidence for our hypothesis for normally distributed data .
1. Z-statistics:
When population means and standard deviations are known.
[Tex]z = \frac{\bar{x} – \mu}{\frac{\sigma}{\sqrt{n}}}[/Tex]
- [Tex]\bar{x} [/Tex] is the sample mean,
- μ represents the population mean,
- σ is the standard deviation
- and n is the size of the sample.
2. T-Statistics
T test is used when n<30,
t-statistic calculation is given by:
[Tex]t=\frac{x̄-μ}{s/\sqrt{n}} [/Tex]
- t = t-score,
- x̄ = sample mean
- μ = population mean,
- s = standard deviation of the sample,
- n = sample size
3. Chi-Square Test
Chi-Square Test for Independence categorical Data (Non-normally distributed) using:
[Tex]\chi^2 = \sum \frac{(O_{ij} – E_{ij})^2}{E_{ij}}[/Tex]
- [Tex]O_{ij}[/Tex] is the observed frequency in cell [Tex]{ij} [/Tex]
- i,j are the rows and columns index respectively.
- [Tex]E_{ij}[/Tex] is the expected frequency in cell [Tex]{ij}[/Tex] , calculated as : [Tex]\frac{{\text{{Row total}} \times \text{{Column total}}}}{{\text{{Total observations}}}}[/Tex]
Real life Examples of Hypothesis Testing
Let’s examine hypothesis testing using two real life situations,
Case A: D oes a New Drug Affect Blood Pressure?
Imagine a pharmaceutical company has developed a new drug that they believe can effectively lower blood pressure in patients with hypertension. Before bringing the drug to market, they need to conduct a study to assess its impact on blood pressure.
- Before Treatment: 120, 122, 118, 130, 125, 128, 115, 121, 123, 119
- After Treatment: 115, 120, 112, 128, 122, 125, 110, 117, 119, 114
Step 1 : Define the Hypothesis
- Null Hypothesis : (H 0 )The new drug has no effect on blood pressure.
- Alternate Hypothesis : (H 1 )The new drug has an effect on blood pressure.
Step 2: Define the Significance level
Let’s consider the Significance level at 0.05, indicating rejection of the null hypothesis.
If the evidence suggests less than a 5% chance of observing the results due to random variation.
Step 3 : Compute the test statistic
Using paired T-test analyze the data to obtain a test statistic and a p-value.
The test statistic (e.g., T-statistic) is calculated based on the differences between blood pressure measurements before and after treatment.
t = m/(s/√n)
- m = mean of the difference i.e X after, X before
- s = standard deviation of the difference (d) i.e d i = X after, i − X before,
- n = sample size,
then, m= -3.9, s= 1.8 and n= 10
we, calculate the , T-statistic = -9 based on the formula for paired t test
Step 4: Find the p-value
The calculated t-statistic is -9 and degrees of freedom df = 9, you can find the p-value using statistical software or a t-distribution table.
thus, p-value = 8.538051223166285e-06
Step 5: Result
- If the p-value is less than or equal to 0.05, the researchers reject the null hypothesis.
- If the p-value is greater than 0.05, they fail to reject the null hypothesis.
Conclusion: Since the p-value (8.538051223166285e-06) is less than the significance level (0.05), the researchers reject the null hypothesis. There is statistically significant evidence that the average blood pressure before and after treatment with the new drug is different.
Python Implementation of Case A
Let’s create hypothesis testing with python, where we are testing whether a new drug affects blood pressure. For this example, we will use a paired T-test. We’ll use the scipy.stats library for the T-test.
Scipy is a mathematical library in Python that is mostly used for mathematical equations and computations.
We will implement our first real life problem via python,
import numpy as np from scipy import stats # Data before_treatment = np . array ([ 120 , 122 , 118 , 130 , 125 , 128 , 115 , 121 , 123 , 119 ]) after_treatment = np . array ([ 115 , 120 , 112 , 128 , 122 , 125 , 110 , 117 , 119 , 114 ]) # Step 1: Null and Alternate Hypotheses # Null Hypothesis: The new drug has no effect on blood pressure. # Alternate Hypothesis: The new drug has an effect on blood pressure. null_hypothesis = "The new drug has no effect on blood pressure." alternate_hypothesis = "The new drug has an effect on blood pressure." # Step 2: Significance Level alpha = 0.05 # Step 3: Paired T-test t_statistic , p_value = stats . ttest_rel ( after_treatment , before_treatment ) # Step 4: Calculate T-statistic manually m = np . mean ( after_treatment - before_treatment ) s = np . std ( after_treatment - before_treatment , ddof = 1 ) # using ddof=1 for sample standard deviation n = len ( before_treatment ) t_statistic_manual = m / ( s / np . sqrt ( n )) # Step 5: Decision if p_value <= alpha : decision = "Reject" else : decision = "Fail to reject" # Conclusion if decision == "Reject" : conclusion = "There is statistically significant evidence that the average blood pressure before and after treatment with the new drug is different." else : conclusion = "There is insufficient evidence to claim a significant difference in average blood pressure before and after treatment with the new drug." # Display results print ( "T-statistic (from scipy):" , t_statistic ) print ( "P-value (from scipy):" , p_value ) print ( "T-statistic (calculated manually):" , t_statistic_manual ) print ( f "Decision: { decision } the null hypothesis at alpha= { alpha } ." ) print ( "Conclusion:" , conclusion )
T-statistic (from scipy): -9.0 P-value (from scipy): 8.538051223166285e-06 T-statistic (calculated manually): -9.0 Decision: Reject the null hypothesis at alpha=0.05. Conclusion: There is statistically significant evidence that the average blood pressure before and after treatment with the new drug is different.
In the above example, given the T-statistic of approximately -9 and an extremely small p-value, the results indicate a strong case to reject the null hypothesis at a significance level of 0.05.
- The results suggest that the new drug, treatment, or intervention has a significant effect on lowering blood pressure.
- The negative T-statistic indicates that the mean blood pressure after treatment is significantly lower than the assumed population mean before treatment.
Case B : Cholesterol level in a population
Data: A sample of 25 individuals is taken, and their cholesterol levels are measured.
Cholesterol Levels (mg/dL): 205, 198, 210, 190, 215, 205, 200, 192, 198, 205, 198, 202, 208, 200, 205, 198, 205, 210, 192, 205, 198, 205, 210, 192, 205.
Populations Mean = 200
Population Standard Deviation (σ): 5 mg/dL(given for this problem)
Step 1: Define the Hypothesis
- Null Hypothesis (H 0 ): The average cholesterol level in a population is 200 mg/dL.
- Alternate Hypothesis (H 1 ): The average cholesterol level in a population is different from 200 mg/dL.
As the direction of deviation is not given , we assume a two-tailed test, and based on a normal distribution table, the critical values for a significance level of 0.05 (two-tailed) can be calculated through the z-table and are approximately -1.96 and 1.96.
The test statistic is calculated by using the z formula Z = [Tex](203.8 – 200) / (5 \div \sqrt{25}) [/Tex] and we get accordingly , Z =2.039999999999992.
Step 4: Result
Since the absolute value of the test statistic (2.04) is greater than the critical value (1.96), we reject the null hypothesis. And conclude that, there is statistically significant evidence that the average cholesterol level in the population is different from 200 mg/dL
Python Implementation of Case B
import scipy.stats as stats import math import numpy as np # Given data sample_data = np . array ( [ 205 , 198 , 210 , 190 , 215 , 205 , 200 , 192 , 198 , 205 , 198 , 202 , 208 , 200 , 205 , 198 , 205 , 210 , 192 , 205 , 198 , 205 , 210 , 192 , 205 ]) population_std_dev = 5 population_mean = 200 sample_size = len ( sample_data ) # Step 1: Define the Hypotheses # Null Hypothesis (H0): The average cholesterol level in a population is 200 mg/dL. # Alternate Hypothesis (H1): The average cholesterol level in a population is different from 200 mg/dL. # Step 2: Define the Significance Level alpha = 0.05 # Two-tailed test # Critical values for a significance level of 0.05 (two-tailed) critical_value_left = stats . norm . ppf ( alpha / 2 ) critical_value_right = - critical_value_left # Step 3: Compute the test statistic sample_mean = sample_data . mean () z_score = ( sample_mean - population_mean ) / \ ( population_std_dev / math . sqrt ( sample_size )) # Step 4: Result # Check if the absolute value of the test statistic is greater than the critical values if abs ( z_score ) > max ( abs ( critical_value_left ), abs ( critical_value_right )): print ( "Reject the null hypothesis." ) print ( "There is statistically significant evidence that the average cholesterol level in the population is different from 200 mg/dL." ) else : print ( "Fail to reject the null hypothesis." ) print ( "There is not enough evidence to conclude that the average cholesterol level in the population is different from 200 mg/dL." )
Reject the null hypothesis. There is statistically significant evidence that the average cholesterol level in the population is different from 200 mg/dL.
Limitations of Hypothesis Testing
- Although a useful technique, hypothesis testing does not offer a comprehensive grasp of the topic being studied. Without fully reflecting the intricacy or whole context of the phenomena, it concentrates on certain hypotheses and statistical significance.
- The accuracy of hypothesis testing results is contingent on the quality of available data and the appropriateness of statistical methods used. Inaccurate data or poorly formulated hypotheses can lead to incorrect conclusions.
- Relying solely on hypothesis testing may cause analysts to overlook significant patterns or relationships in the data that are not captured by the specific hypotheses being tested. This limitation underscores the importance of complimenting hypothesis testing with other analytical approaches.
Hypothesis testing stands as a cornerstone in statistical analysis, enabling data scientists to navigate uncertainties and draw credible inferences from sample data. By systematically defining null and alternative hypotheses, choosing significance levels, and leveraging statistical tests, researchers can assess the validity of their assumptions. The article also elucidates the critical distinction between Type I and Type II errors, providing a comprehensive understanding of the nuanced decision-making process inherent in hypothesis testing. The real-life example of testing a new drug’s effect on blood pressure using a paired T-test showcases the practical application of these principles, underscoring the importance of statistical rigor in data-driven decision-making.
Frequently Asked Questions (FAQs)
1. what are the 3 types of hypothesis test.
There are three types of hypothesis tests: right-tailed, left-tailed, and two-tailed. Right-tailed tests assess if a parameter is greater, left-tailed if lesser. Two-tailed tests check for non-directional differences, greater or lesser.
2.What are the 4 components of hypothesis testing?
Null Hypothesis ( [Tex]H_o [/Tex] ): No effect or difference exists. Alternative Hypothesis ( [Tex]H_1 [/Tex] ): An effect or difference exists. Significance Level ( [Tex]\alpha [/Tex] ): Risk of rejecting null hypothesis when it’s true (Type I error). Test Statistic: Numerical value representing observed evidence against null hypothesis.
3.What is hypothesis testing in ML?
Statistical method to evaluate the performance and validity of machine learning models. Tests specific hypotheses about model behavior, like whether features influence predictions or if a model generalizes well to unseen data.
4.What is the difference between Pytest and hypothesis in Python?
Pytest purposes general testing framework for Python code while Hypothesis is a Property-based testing framework for Python, focusing on generating test cases based on specified properties of the code.
Please Login to comment...
Similar reads.
- data-science
- Top Android Apps for 2024
- Top Cell Phone Signal Boosters in 2024
- Best Travel Apps (Paid & Free) in 2024
- The Best Smart Home Devices for 2024
- 15 Most Important Aptitude Topics For Placements [2024]
Improve your Coding Skills with Practice
What kind of Experience do you want to share?
IMAGES
VIDEO
COMMENTS
Step 5: Present your findings. The results of hypothesis testing will be presented in the results and discussion sections of your research paper, dissertation or thesis.. In the results section you should give a brief summary of the data and a summary of the results of your statistical test (for example, the estimated difference between group means and associated p-value).
Formulate the Hypotheses: Write your research hypotheses as a null hypothesis (H 0) and an alternative hypothesis (H A).; Data Collection: Gather data specifically aimed at testing the hypothesis.; Conduct A Test: Use a suitable statistical test to analyze your data.; Make a Decision: Based on the statistical test results, decide whether to reject the null hypothesis or fail to reject it.
Hypothesis testing is a scientific method used for making a decision and drawing conclusions by using a statistical approach. It is used to suggest new ideas by testing theories to know whether or not the sample data supports research. A research hypothesis is a predictive statement that has to be tested using scientific methods that join an ...
HYPOTHESIS TESTING. A clinical trial begins with an assumption or belief, and then proceeds to either prove or disprove this assumption. In statistical terms, this belief or assumption is known as a hypothesis. Counterintuitively, what the researcher believes in (or is trying to prove) is called the "alternate" hypothesis, and the opposite ...
Step 1: State the Null Hypothesis. The null hypothesis can be thought of as the opposite of the "guess" the researchers made: in this example, the biologist thinks the plant height will be different for the fertilizers. So the null would be that there will be no difference among the groups of plants. Specifically, in more statistical language ...
The specific group being studied. The predicted outcome of the experiment or analysis. 5. Phrase your hypothesis in three ways. To identify the variables, you can write a simple prediction in if…then form. The first part of the sentence states the independent variable and the second part states the dependent variable.
This is the basic structure of testing a hypothesis, usually called a hypothesis test. Since this one has a test statistic involving z, it is also called a z-test. And since there is only one sample, it is usually called a one-sample z-test. ... Based on research data, the claim is made that from the time shoots are planted 90 days on average ...
Hypothesis testing is a crucial procedure to perform when you want to make inferences about a population using a random sample. These inferences include estimating population properties such as the mean, differences between means, proportions, and the relationships between variables. This post provides an overview of statistical hypothesis testing.
In hypothesis testing, the goal is to see if there is sufficient statistical evidence to reject a presumed null hypothesis in favor of a conjectured alternative hypothesis.The null hypothesis is usually denoted \(H_0\) while the alternative hypothesis is usually denoted \(H_1\). An hypothesis test is a statistical decision; the conclusion will either be to reject the null hypothesis in favor ...
8.2 FOUR STEPS TO HYPOTHESIS TESTING The goal of hypothesis testing is to determine the likelihood that a population parameter, such as the mean, is likely to be true. In this section, we describe the four steps of hypothesis testing that were briefly introduced in Section 8.1: Step 1: State the hypotheses. Step 2: Set the criteria for a decision.
This chapter lays out the basic logic and process of hypothesis testing. We will perform z tests, which use the z score formula from Chapter 6 and data from a sample mean to make an inference about a population.. Logic and Purpose of Hypothesis Testing. A hypothesis is a prediction that is tested in a research study. The statistician R. A. Fisher explained the concept of hypothesis testing ...
Applications of Hypothesis Testing in Research. Hypothesis testing isn't only confined to numbers and calculations; it also has several real-life applications in business, manufacturing, advertising, and medicine. ... Simple guide on pure or basic research, its methods, characteristics, advantages, and examples in science, medicine, education ...
Medical providers often rely on evidence-based medicine to guide decision-making in practice. Often a research hypothesis is tested with results provided, typically with p values, confidence intervals, or both. Additionally, statistical or research significance is estimated or determined by the investigators. Unfortunately, healthcare providers may have different comfort levels in interpreting ...
A hypothesis test consists of five steps: 1. State the hypotheses. State the null and alternative hypotheses. These two hypotheses need to be mutually exclusive, so if one is true then the other must be false. 2. Determine a significance level to use for the hypothesis. Decide on a significance level.
3. Simple hypothesis. A simple hypothesis is a statement made to reflect the relation between exactly two variables. One independent and one dependent. Consider the example, "Smoking is a prominent cause of lung cancer." The dependent variable, lung cancer, is dependent on the independent variable, smoking. 4.
A hypothesis test allows us to test the claim about the population and find out how likely it is to be true. The hypothesis test consists of several components; two statements, the null hypothesis and the alternative hypothesis, the test statistic and the critical value, which in turn give us the P-value and the rejection region ...
Components of a Formal Hypothesis Test. The null hypothesis is a statement about the value of a population parameter, such as the population mean (µ) or the population proportion (p).It contains the condition of equality and is denoted as H 0 (H-naught).. H 0: µ = 157 or H0 : p = 0.37. The alternative hypothesis is the claim to be tested, the opposite of the null hypothesis.
Unlike in quantitative research where hypotheses are usually developed to be tested, qualitative research can lead to both hypothesis-testing and hypothesis-generating outcomes.2 When studies require both quantitative and qualitative research questions, this suggests an integrative process between both research methods wherein a single mixed ...
4 Step Process. State the hypotheses. Formulate an analysis plan, which outlines how the data will be evaluated. Carry out the plan and analyze the sample data. Analyze the results and either ...
Step 4: Your sample score of 27 needs to be converted into a Z value. To calculate Z = (27-19)/4= 2 (check the if you need to review how to do this process) Step 5: A 'Z' score of 2 is more extreme than the cut off Z of +1.96 (see figure above). The result is significant and, thus, the null hypothesis is rejected. You can find more examples ...
148. 4. Photo by Anna Nekrashevich from Pexels. Hypothesis testing is a common statistical tool used in research and data science to support the certainty of findings. The aim of testing is to answer how probable an apparent effect is detected by chance given a random data sample. This article provides a detailed explanation of the key concepts ...
This page titled 1.4: Basic Concepts of Hypothesis Testing is shared under a not declared license and was authored, remixed, and/or curated by John H. McDonald via source content that was edited to the style and standards of the LibreTexts platform. The technique used by the vast majority of biologists, and the technique that most of this ...
Hypothesis testing is a statistical method that is used to make a statistical decision using experimental data. ... it is a basic assumption or made based on the problem knowledge. Example: A company's mean production is 50 units ... The Lottery Ticket Hypothesis has been presented in the form of a research paper at ICLR 2019 by MIT-IBM ...
Quantitative research involves the collection and analysis of numerical data to test hypotheses and identify patterns and relationships (Hair et al., Citation 2019). Using a quantitative approach, this study aimed to systematically examine the relationship between green supply chain practices and commercial performance metrics.
The Null hypothesis \(\left(H_{O}\right)\) is a statement about the comparisons, e.g., between a sample statistic and the population, or between two treatment groups. The former is referred to as a one-tailed test whereas the latter is called a two-tailed test. The null hypothesis is typically "no statistical difference" between the ...
We can calibrate the Bayesian probability to the frequentist p-value (Selke et al 2001; Goodman 2008; Held 2010; Greenland and Poole 2012). Methods to achieve this calibration vary, but the Fagan nomogram proposed by Held (2010) is a good tool for us as we go forward. We can calculate our NHST p-value, but then convert the p-value to a Bayes factor by looking at the nomogram.