Research Paper Classification Using Machine and Deep Learning Techniques
New citation alert added.
This alert has been successfully added and will be sent to:
You will be notified whenever a record that you have chosen has been cited.
To manage your alert preferences, click on the button below.

New Citation Alert!
Please log in to your account
Information & Contributors
Bibliometrics & citations, index terms.
Computing methodologies
Machine learning
Machine learning approaches
Classification and regression trees
Recommendations
Deep learning--based text classification: a comprehensive review.
Deep learning--based models have surpassed classical machine learning--based approaches in various text classification tasks, including sentiment analysis, news categorization, question answering, and natural language inference. In this article, we ...
Boosting to correct inductive bias in text classification
This paper studies the effects of boosting in the context of different classification methods for text categorization, including Decision Trees, Naive Bayes, Support Vector Machines (SVMs) and a Rocchio-style classifier. We identify the inductive biases ...
Chinese text classification by the Naïve Bayes Classifier and the associative classifier with multiple confidence threshold values
Each type of classifier has its own advantages as well as certain shortcomings. In this paper, we take the advantages of the associative classifier and the Naive Bayes Classifier to make up the shortcomings of each other, thus improving the accuracy of ...
Information
Published in.

Association for Computing Machinery
New York, NY, United States
Publication History
Permissions, check for updates, author tags.
- deep learning
- gradient-boosted trees
- machine learning
- text classification
- topic classification
- Research-article
- Refereed limited
Contributors
Other metrics, bibliometrics, article metrics.
- 0 Total Citations
- 12 Total Downloads
- Downloads (Last 12 months) 12
- Downloads (Last 6 weeks) 12
View Options
Login options.
Check if you have access through your login credentials or your institution to get full access on this article.
Full Access
View options.
View or Download as a PDF file.
View online with eReader .
HTML Format
View this article in HTML Format.
Share this Publication link
Copying failed.
Share on social media
Affiliations, export citations.
- Please download or close your previous search result export first before starting a new bulk export. Preview is not available. By clicking download, a status dialog will open to start the export process. The process may take a few minutes but once it finishes a file will be downloadable from your browser. You may continue to browse the DL while the export process is in progress. Download
- Download citation
- Copy citation
We are preparing your search results for download ...
We will inform you here when the file is ready.
Your file of search results citations is now ready.
Your search export query has expired. Please try again.
- Open access
- Published: 26 August 2019
Research paper classification systems based on TF-IDF and LDA schemes
- Sang-Woon Kim 1 &
- Joon-Min Gil ORCID: orcid.org/0000-0001-6774-8476 2
Human-centric Computing and Information Sciences volume 9 , Article number: 30 ( 2019 ) Cite this article
36k Accesses
163 Citations
2 Altmetric
Metrics details
With the increasing advance of computer and information technologies, numerous research papers have been published online as well as offline, and as new research fields have been continuingly created, users have a lot of trouble in finding and categorizing their interesting research papers. In order to overcome the limitations, this paper proposes a research paper classification system that can cluster research papers into the meaningful class in which papers are very likely to have similar subjects. The proposed system extracts representative keywords from the abstracts of each paper and topics by Latent Dirichlet allocation (LDA) scheme. Then, the K-means clustering algorithm is applied to classify the whole papers into research papers with similar subjects, based on the Term frequency-inverse document frequency (TF-IDF) values of each paper.
Introduction
Numerous research papers have been published online as well as offline with the increasing advance of computer and information technologies, which makes it difficult for users to search and categorize their interesting research papers for a specific subject [ 1 ]. Therefore, it is desired that these huge numbers of research papers are systematically classified with similar subjects so that users can find their interesting research papers easily and conveniently. Typically, finding research papers on specific topics or subjects is time consuming activity. For example, researchers are usually spending a long time on the Internet to find their interesting papers and are bored because the information they are looking for is not retrieved efficiently due to the fact that the papers are not grouped in their topics or subjects for easy and fast access.
The commonly-used analysis for the classification of a huge number of research papers is run on large-scale computing machines without any consideration on big data properties. As time goes on, it is difficult to manage and process efficiently those research papers that continue to quantitatively increase. Since the relation of the papers to be analyzed and classified is very complex, it is also difficult to catch quickly the subject of each research paper and, moreover hard to accurately classify research papers with the similar subjects in terms of contents. Therefore, there is a need to use an automated processing method for such a huge number of research papers so that they are classified fast and accurately.
The abstract is one of important parts in a research paper as it describes the gist of the paper. Typically, it is a next most part that users read after paper title. Accordingly, users tend to read firstly a paper abstract in order to catch the research direction and summary before reading contents in the body of a paper. In this regard, the core words of research papers should be written in the abstract concisely and interestingly. Therefore, in this paper, we use the abstract data of research papers as a clue to classify similar papers fast and correct.
To classify a huge number of papers into papers with similar subjects, we propose the paper classification system based on term frequency-inverse document frequency (TF-IDF) [ 2 , 3 , 4 ] and Latent Dirichlet allocation (LDA) [ 5 ] schemes. The proposed system firstly constructs a representative keyword dictionary with the keywords that user inputs, and with the topics extracted by the LDA. Secondly, it uses the TF-IDF scheme to extract subject words from the abstract of papers based on the keyword dictionary. Then, the K-means clustering algorithm [ 6 , 7 , 8 ] is applied to classify the papers with similar subjects, based on the TF-IDF values of each paper.
To extract subject words from a set of massive papers efficiently, in this paper, we use the Hadoop Distributed File Systems (HDFS) [ 9 , 10 ] that can process big data rapidly and stably with high scalability. We also use the map-reduce programming model [ 11 , 12 ] to calculate the TF-IDF value from the abstract of each paper. Moreover, in order to demonstrate the validation and applicability of the proposed system, this paper evaluates the performance of the proposed system, based on actual paper data. As the experimental data of performance evaluation, we use the titles and abstracts of the papers published on Future Generation Compute Systems (FGCS) journal [ 13 ] from 1984 to 2017. The experimental results indicate that the proposed system can well classify the whole papers with papers with similar subjects according to the relationship of the keywords extracted from the abstracts of papers.
The remainder of the paper is organized as follows: In “ Related work ” section, we provide related work on research paper classification. “ System flow diagram ” section presents a system flow diagram for our research paper classification system. “ Paper classification system ” section explains the paper classification system based on TF-IDF and LDA schemes in detail. In “ Experiments ” section, we carry out experiments to evaluate the performance of the proposed paper classification system. In particular, Elbow scheme is applied to determine the optimal number of clusters in the K-means clustering algorithm, and Silhouette schemes are introduced to show the validation of clustering results. Finally, “ Conclusion ” section concludes the paper.
Related work
This section briefly reviews the literature on paper classification methods related on the research subject of this paper.
Document classification has direct relation with the paper classification of this paper. It is a problem that assigns a document to one or more predefined classes according to a specific criterion or contents. The representative application areas of document classification are follows as:
News article classification: The news articles are generally massive, because they are tremendously issued in daily or hourly. There have been lots of works for automatic news article classification [ 14 ].
Opinion mining: It is very important to analyze the information on opinions, sentiment, and subjectivity in documents with a specific topic [ 15 ]. Analysis results can be applied to various areas such as website evaluation, the review of online news articles, opinion in blog or SNS, etc. [ 16 ].
Email classification and spam filtering: Its area can be considered as a document classification problem not only for spam filtering, but also for classifying messages and sorting them into a specific folder [ 17 ].
A wide variety of classification techniques have been used to document classification [ 18 ]. Automatic document classification can be divided into two methods: supervised and unsupervised [ 19 , 20 , 21 ]. In the supervised classification, documents are classified on the basis of supervised learning methods. These methods generally analyze the training data (i.e., pair data of predefined input–output) and produce an inferred function which can be used for mapping other examples. On the other hand, unsupervised classification groups documents, based on similarity among documents without any predefined criterion. As automatic document classification algorithms, there have been developed various types of algorithms such as Naïve Bayes classifier, TF-IDF, Support Vector Machine (SVM), K-Nearest Neighbors (KNN), Decision Tree, and so on [ 22 , 23 ].
Meanwhile, as works related on paper classification, Bravo-Alcobendas et al. [ 24 ] proposed a document clustering algorithm that extracts the characteristics of documents by Non-negative matrix factorization (NMF) and that groups documents by K-means clustering algorithm. This work mainly focuses on the reduction of high-dimensional vector formed by word counts in documents, not on a sophisticated classification in terms of a variety of subject words.
In [ 25 ], Taheriyan et al. proposed the paper classification method based on a relation graph using interrelationships among papers, such as citations, authors, common references, etc. This method has better performance as the links among papers increase. It mainly focuses on interrelationships among papers without any consideration of paper contents or subjects. Thus, the papers can be misclassified regardless of subjects.
In [ 26 ], Hanyurwimfura et al. proposed the paper classification method based on research paper’s title and common terms. In [ 27 ], Nanbo et al. proposed the paper classification method that extracts keywords from research objectives and background and that groups papers on the basis of the extracted keywords. In these works, the results achieved on using important information such as paper’s subjects, objectives, background were promising ones. However, they does not consider frequently occurring keywords in paper classification. Paper title, research objectives, and research background provide only limited information, leading to inaccurate decision [ 28 ].
In [ 29 ], Nguyen et al. proposed the paper classification method based on Bag-of-Word scheme and KNN algorithm. This method extracts topics from all contents of a paper without any consideration for the reduction of computational complexity. Thus, it suffers from extensive computational time when data volume sharply increases.
Different from the above mentioned methods, our method uses three kinds of keywords: keywords that users input, keywords extracted from abstracts, and topics extracted by LDA scheme. These keywords are used to calculate the TF-IDF of each paper, with an aim to considering an importance of papers. Then, the K-means clustering algorithm is applied to classify the papers with similar subjects, based on the TF-IDF values of each paper. Meanwhile, our classification method is designed and implemented on Hadoop Distributed File System (HDFS) to efficiently process the massive research papers that have the characteristics of big data. Moreover, map-reduce programming model is used for the parallel processing of the massive research papers. To our best knowledge, our work is the first to use the analysis of paper abstracts based on TF-IDF and LDA schemes for paper classification.
System flow diagram
The paper classification system proposed in this paper consists of four main processes (Fig. 1 ): (1) Crawling, (2) Data Management and Topic Modeling, (3) TF-IDF, and (4) Classification. This section describes a system flow diagram for our paper classification system.

Detailed flows for the system flow diagram shown in Fig. 1 are as follows:
It automatically collects keywords and abstracts data of the papers published during a given period. It also executes preprocessing for these data, such as the removal of stop words, the extraction of only nouns, etc.
It constructs a keyword dictionary based on crawled keywords. Because total keywords of whole papers are huge, this paper uses only top-N keywords with high frequency among the whole keywords
It extracts topics from the crawled abstracts by LDA topic modeling
It calculates paper lengths as the number of occurrences of words in the abstract of each paper
It calculates a TF value for both of the keywords obtained by Step 2 and the topics obtained by Step 3
It calculates an IDF value for both of the keywords obtained by Step 2 and the topics obtained by Step 3
It calculates a TF-IDF value for each keyword using the values obtained by Steps 4, 5, and 6
It groups the whole papers into papers with a similar subject, based on the K-means clustering algorithm
In the next section, we provide a detailed description for the above mentioned steps.
Paper classification system
Crawling of abstract data.
The abstract is one of important parts in a paper as it describes the gist of the paper [ 30 ]. Typically, next a paper title, the next most part of papers that users are likely to read is the abstract. That is, users tend to read firstly a paper abstract in order to catch the research direction and summary before reading all contents in the paper. Accordingly, the core words of papers should be written concisely and interestingly in the abstract. Because of this, this paper classifies similar papers based on abstract data fast and correct.
As you can see in the crawling step of Fig. 1 , the data crawler collects the paper abstract and keywords according to the checking items of crawling list. It also removes stop words in the crawled abstract data and then extracts only nouns from the data. Since the abstract data have large-scale volume and are produced fast, they have a typical characteristic of big data. Therefore, this paper manages the abstract data on HDFS and calculates the TF-IDF value of each paper using the map-reduce programming model. Figure 2 shows an illustrative example for the abstract data before and after the elimination of stop words and the extraction of nouns are applied.

Abstract data before and after preprocessing
After the preprocessing (i.e., the removal of stop words and the extraction of only nouns), the amount of abstract data should be greatly reduced. This will result to enhancing the processing efficiency of the proposed paper classification system.
Managing paper data
The save step in Fig. 1 constructs the keyword dictionary using the abstract data and keywords data crawled in crawling step and saves it to the HDFS.
In order to process lots of keywords simply and efficiently, this paper categorizes several keywords with similar meanings into one representative keyword. In this paper, we construct 1394 representative keywords from total keywords of all abstracts and make a keyword dictionary of these representative keywords. However, even these representative keywords cause much computational time if they are used for paper classification without a way of reducing computation. To alleviate this suffering, we use the keyword sets of top frequency 10, 20, and 30 among these representative keywords, as shown in Table 1 .
Topic modeling
Latent Dirichlet allocation (LDA) is a probabilistic model that can extract latent topics from a collection of documents. The basic idea is that documents are represented as random mixtures over latent topics, where each topic is characterized by a distribution over words [ 31 , 32 ].
The LDA estimates the topic-word distribution \(P(t|z)\) and the document-topic distribution \(P(z|d)\) from an unlabeled corpus using Dirichlet priors for the distributions with a fixed number of topics [ 31 , 32 ]. As a result, we get \(P(z|d)\) for each document and further build the feature vector as
In this paper, using LDA scheme, we extract topic sets from the abstract data crawled in crawling step. Three kinds of topic sets are extracted, each of which consists of 10, 20, and 30 topics, respectively. Table 2 shows topic sets with 10 topics and the keywords of each topic. The remaining topic sets with 20 and 30 topics are omitted due to space limitations.
The TF-IDF has been widely used in the fields of information retrieval and text mining to evaluate the relationship for each word in the collection of documents. In particular, they are used for extracting core words (i.e., keywords) from documents, calculating similar degrees among documents, deciding search ranking, and so on.
The TF in TF-IDF means the occurrence of specific words in documents. Words with a high TF value have an importance in documents. On the other hand, the DF implies how many times a specific word appears in the collection of documents. It calculates the occurrence of the word in multiple documents, not in only a document. Words with a high DF value do not have an importance because they commonly appear in all documents. Accordingly, the IDF that is an inverse of the DF is used to measure an importance of words in all documents. The high IDF values mean rare words in all documents, resulting to the increase of an importance.
Paper length
The paper length step of Fig. 1 calculates a total number of occurrences of words after separating words in a given abstract using white spaces as a delimiter. The objective of this step is to prevent unbalancing of TF values caused by a quantity of abstracts. Figure 3 shows a map-reduce algorithm for the calculation of paper length. In this figure, DocName and wc represents a paper title and a paper length, respectively.

Map-reduce algorithm for the calculation of paper length
Word frequency
The TF calculation step in Fig. 1 counts how many times the keywords defined in a keyword dictionary and the topics extracted by LDA appear in abstract data. The TF used in this paper is defined as
where, \(n_{i,j}\) represents the number of occurrences of word \(t_{i}\) in document \(d_{j}\) and \(\sum\limits_{k} {n_{k,j} }\) represents a total number of occurrences of words in document \(d_{j}\) . K and D are the number of keywords and documents (i.e., papers), respectively.
Figure 4 illustrates TF calculation for 10 keywords of top frequency. The abstract data in this figure have the paper length of 64. As we can see in this figure, the keywords ‘cloud computing’, ‘Internet of Things’, and ‘Big Data’ have the TF value of 0.015 because of one occurrence in the abstract data. The keyword ‘cloud computing’ has the TF value of 0.03 because of two occurrences. Figure 5 shows map-reduce algorithm to calculate word frequency (i.e., TF). In this figure, n represents the number of occurrences of a keyword in a document with a paper title of DocName .

An illustrative example of TF calculation

Map-reduce algorithm for the calculation of word frequency
Document frequency
While the TF means the number of occurrences of each keyword in a document, the DF means how many times each keyword appears in the collection of documents. In the DF calculation step in Fig. 1 , the DF is calculated by dividing the total number of documents by the number of documents that contain a specific keyword. It is defined as
where, \(\left| D \right|\) represents total number of documents and \(\left| {d_{j} \in D:t_{j} \in d_{j} } \right|\) represents the number of documents that keyword \(t_{j}\) occurs. Figure 6 shows an illustrative example when four documents are used to calculate the DF value.

An illustrative example of DF calculation
Figure 7 shows the map-reduce algorithm to calculate the DF of each paper.

Map-reduce algorithm for the calculation of document frequency
Keywords with a high DF value cannot have an importance because they commonly appear in the most documents. Accordingly, the IDF that is an inverse of the DF is used to measure an importance of keywords in the collection of documents. The IDF is defined as
Using Eqs. ( 2 ) and ( 4 ), the TF-IDF is defined as
The TF-IDF value increases when a specific keyword has high frequency in a document and the frequency of documents that contain the keyword among the whole documents is low. This principle can be used to find the keywords frequently occurring in documents. Consequently, using the TF-IDF calculated by Eq. ( 5 ), we can find out what keywords are important in each paper.
Figure 8 shows the map-reduce algorithm for the TF-IDF calculation of each paper.

Map-reduce algorithm for TF-IDF calculation
- K-means clustering
Typically, clustering technique is used to classify a set of data into classes of similar data. Until now, it has been applied to various applications in many fields such as marketing, biology, pattern recognition, web mining, analysis of social networks, etc. [ 33 ]. Among various clustering techniques, we choose the k-means clustering algorithm, which is one of unsupervised learning algorithm, because of its effectiveness and simplicity. More specifically, the algorithm is to classify the data set of N items based on features into k disjoint subsets. This is done by minimizing distances between data item and the corresponding cluster centroid.
Mathematically, the k-means clustering algorithm can be described as follows:
where, k is the number of clusters, \(x_{j}\) is the j th data point in the i th cluster \(C_{i}\) , and \(c_{i}\) is the centroid of \(C_{i}\) . The notation \(\left\| {x_{j} - c_{i} } \right\|^{2}\) stands for the distance between \(x_{j}\) and \(c_{i}\) , and Euclidean distance is commonly used as a distance measure. To achieve a representative clustering, a sum of squared error function, E , should be as small as possible.
The advantage of the K-means clustering algorithm is that (1) dealing with different types of attributes; (2) discovering clusters with arbitrary shape; (3) minimal requirements for domain knowledge to determine input parameters; (4) dealing with noise and outliers; and (5) minimizing the dissimilarity between data [ 34 ].
The TF-IDF value represents an importance of the keywords that determines characteristics of each paper. Thus, the classification of papers by TF-IDF value leads to finding a group of papers with similar subjects according to the importance of keywords. Because of this, this paper uses the K-means clustering algorithm, which is one of most used clustering algorithm, to group papers with similar subjects. The K-means clustering algorithm used in this paper calculates a center of the cluster that represents a group of papers with a specific subject and allocates a paper to a cluster with high similarity, based on a Euclidian distance between the TF-IDF value of the paper and a center value of each cluster.
The K-means clustering algorithm is computationally faster than the other clustering algorithms. However, it produces different clustering results for different number of clusters. So, it is required to determine the number of clusters (i.e., K value) in advance before clustering. To overcome the limitations, we will use the Elbow scheme [ 35 ] that can find a proper number of clusters. Also, we will use the Silhouette scheme [ 36 , 37 ] to validate the performance of clustering results by K-means clustering scheme. The detailed descriptions of the two schemes will be provided in next section with performance evaluation.
Experiments
Experimental environment.
The paper classification system proposed by this paper is based on the HDFS to manage and process massive paper data. Specifically, we build the Hadoop cluster composed of one master node, one sub node, and four data nodes. The TF-IDF calculation module is implemented with Java language on Hadoop-2.6.5 version. We also implemented the LDA calculation module using Spark MLlib in python. The K-means clustering algorithm is implemented using Scikit-learn library [ 38 ].
Meanwhile, as experimental data, we use the actual papers published on Future Generation Computer System (FGCS) journal [ 13 ] during the period of 1984 to 2017. The titles, abstracts, and keywords of total 3264 papers are used as core data for paper classification. Figure 9 shows overall system architecture for our paper classification system.

Overall system architecture for our paper classification system
The keyword dictionaries used for performance evaluation in this paper are constructed with the three methods shown in Table 3 . The constructed keyword dictionaries are applied to Elbow and Silhouette schemes, respectively, to compare and analyze the performance of the proposed system.
Experimental results
Applying elbow scheme.
When using K-means clustering algorithm, users should determine a number of clusters before the clustering of a dataset is executed. One method to validate the number of clusters is to use the Elbow scheme [ 35 ]. We perform Elbow scheme to find out an optimal number of clusters, changing the value ranging from 2 to 100.
Table 4 shows the number of clusters obtained by Elbow scheme for the three methods shown in Table 3 .
As we can see in the results of Table 4 , the number of clusters becomes more as the number of keywords increases. It is natural phenomenon because the large number of keywords results in more elaborate clustering for the given keywords. However, on comparing the number of clusters of three methods, we can see that Method 3 has the lower number of clusters than other two methods. This is because Method 3 can complementarily use the advantages of the remaining two methods when it groups papers with similar subjects. That is, Method 1 depends on the keywords input by users. It cannot be guaranteed that these keywords are always correct to group papers with similar subjects. The reason is because users can register incorrect keywords for their own papers. Method 2 makes up for the disadvantage of Method 1 using the topics automatically extracted by LDA scheme. Figure 10 shows elbow graph when Method 3 are used. In this figure, an upper arrow represents the optimal number of clusters calculated by Elbow scheme.

Elbow graph for Method 3
Applying Silhouette scheme
The silhouette scheme is one of various evaluation methods as a measure to evaluate the performance of clustering [ 36 , 37 ]. The silhouette value becomes higher as two data within a same cluster is closer. It also becomes higher as two data within different clusters is farther. Typically, a silhouette value ranges from − 1 to 1, where a high value indicates that data are well matched to their own cluster and poorly matched to neighboring clusters. Generally, the silhouette value more than 0.5 means that clustering results are validated [ 36 , 37 ].
Table 5 shows an average silhouette value for each of the three methods shown in Table 3 . We can see from results of this table that the K-means clustering algorithm used in the paper produces good clustering when 10 and 30 keywords are used. It is should be noted that the silhouette values of more than 0.5 represent valid clustering. Figure 11 shows the silhouette graph for each of 10, 20, and 30 keywords when Method 3 are used. In this figure, a dashed line represents the average silhouette value. We omit the remaining silhouette graphs due to space limitations.

Silhouette graph for Method 3
Analysis of classification results
Table 6 shows an illustrative example for classification results. In this table, the papers in cluster 1 indicate that they are grouped by two keywords ‘cloud’ and ‘bigdata’ as a primary keyword. For cluster 2, two keywords ‘IoT’ and ‘privacy’ have an important role in grouping the papers in this cluster. For cluster 3, three keywords ‘IoT’, ‘security’ and ‘privacy’ have an important role. In particular, according to whether or not the keyword ‘security’ is used, the papers in cluster 2 and cluster 3 are grouped into different clusters.
Figure 12 shows a TF-IDF value and a clustering result for some papers. In this figure, ‘predict’ means cluster number, whose cluster contains a paper with the title denoted in first column. In Fig. 12 a, we can observe that all papers have the same keyword ‘scheduling’, but they are divided into two clusters according to a TF-IDF value of the keyword. Figure 12 b indicates that all papers have the same keyword ‘cloud’, but they are grouped into different clusters (cluster 7 and cluster 8) according whether or not a TF-IDF value of the keyword ‘cloud storage’ exists.

Illustrative examples of clustering results
Figure 13 shows an analysis result for the papers belonging to the same cluster. In this figure, we can see that three papers in cluster 11 have four common keywords ‘cloud’, ‘clustering’, ‘hadoop’, and ‘map-reduce’ as a primary keyword. Therefore, we can see from this figure that the papers are characterized by these four common keywords.

Clustering results by common keywords
Figures 14 and 15 show abstract examples for first and second papers among the four ones shown in Fig. 13 , respectively. From these figures, we can see that four keywords (‘cloud’, ‘clustering’, ‘hadoop’, and ‘map-reduce’) are properly included in the abstracts of the two papers.

An abstract example for [ 39 ]

An abstract example for [ 40 ]
Evaluation on the accuracy of the proposed classification system
The accuracy the proposed classification systems has been evaluated by using the well-known F-Score [ 41 ] which measure how good paper classification is when compared with reference classification. The F-Score is a combination of the precision and recall values used in information extraction. The precision, recall, and F-Score are defined as follows.
In the above equations, TP, TN, FP, and FN represents true positive, true negative, false positive, and false negative, respectively. We carried out our experiments on 500 research papers randomly selected among the total 3264 ones used for our experiments. This experiment is run 5 times and the average of F-Score values is recorded.
Figure 16 shows the F-Score values of the three methods to construct keyword dictionaries shown in Table 3 .

F-score values of three methods (TF-IDF, LDA, TF-IDF + LDA)
As we can see in the results of Fig. 16 , the F-score value of Method 3 (the combination of TF-IDF and LDA) is higher than that of other methods. The main reason is that Method 3 can complementarily use the advantages of the remaining two methods. That is, TF-IDF can extract only the frequently occurring keywords in research papers and LDA can extract only the topics which are latent in research papers. On the other hand, the combination of TF-IDF and LDA can lead to the more detailed classification of research papers because frequently occurring keywords and the correlation between latent topics are simultaneously used to classify the papers.
We presented a paper classification system to efficiently support the paper classification, which is essential to provide users with fast and efficient search for their desired papers. The proposed system incorporates TF-IDF and LDA schemes to calculate an importance of each paper and groups the papers with similar subjects by the K-means clustering algorithm. It can thereby achieve correct classification results for users’ interesting papers. For the experiments to demonstrate the performance of the proposed system, we used actual data based on the papers published in FGCS journal. The experimental results showed that the proposed system can classify the papers with similar subjects according to the keywords extracted from the abstracts of papers. In particular, when a keyword dictionary with both of the keywords extracted from the abstracts and the topics extracted by LDA scheme was used, our classification system has better clustering performance and higher F-Score values. Therefore, our classification systems can classify research papers in advance by both of keywords and topics with the support of high-performance computing techniques, and then the classified research papers will be applied to search the papers within users’ interesting research areas, fast and efficiently.
This work has been mainly focused on developing and analyzing research paper classification. To be a generic approach, the work needs to be expanded into various types of datasets, e.g. documents, tweets, and so on. Therefore, future work involves working upon various types of datasets in the field of text mining, as well as developing even more efficient classifiers for research paper datasets.
Availability of data and materials
Not applicable.
Bafna P, Pramod D, Vaidya A (2016) Document clustering: TF-IDF approach. In: IEEE int. conf. on electrical, electronics, and optimization techniques (ICEEOT). pp 61–66
Ramos J (2003) Using TF-IDF to determine word relevance in document queries. In: Proc. of the first int. conf. on machine learning
Havrlant L, Kreinovich V (2017) A simple probabilistic explanation of term frequency-inverse document frequency (TF-IDF) heuristic (and variations motivated by this explanation). Int J Gen Syst 46(1):27–36
Article MathSciNet Google Scholar
Trstenjak B, Mikac S, Donko D (2014) KNN with TF-IDF based framework for text categorization. Procedia Eng 69:1356–1364
Article Google Scholar
Yau C-K et al (2014) Clustering scientific documents with topic modeling. Scientometrics 100(3):767–786
Balabantaray RC, Sarma C, Jha M (2013) Document clustering using K-means and K-medoids. Int J Knowl Based Comput Syst 1(1):7–13.
Google Scholar
Gupta H, Srivastava R (2014) K-means based document clustering with automatic “K” selection and cluster refinement. Int J Comput Sci Mob Appl 2(5):7–13
Gurusamy R, Subramaniam V (2017) A machine learning approach for MRI brain tumor classification. Comput Mater Continua 53(2):91–108
Nagwani NK (2015) Summarizing large text collection using topic modeling and clustering based on MapReduce framework. J Big Data 2(1):1–18
Kim J-J (2017) Hadoop based wavelet histogram for big data in cloud. J Inf Process Syst 13(4):668–676
Dean J, Ghemawat S (2008) MapReduce: simplified data processing on large clusters. Commun ACM 51(1):107–113
Cho W, Choi E (2017) DTG big data analysis for fuel consumption estimation. J Inf Process Syst 13(2):285–304
FGCS Journal. https://www.journals.elsevier.com/future-generation-computer-systems . Accessed 15 Aug 2018.
Gui Y, Gao G, Li R, Yang X (2012) Hierarchical text classification for news articles based-on named entities. In: Proc. of int. conf. on advanced data mining and applications. pp 318–329
Chapter Google Scholar
Singh J, Singh G, Singh R (2017) Optimization of sentiment analysis using machine learning classifiers. Hum-cent Comput Inf Sci 7:32
Mahendran A et al (2013) “Opinion Mining for text classification,” Int. J Sci Eng Technol 2(6):589–594
Alsmadi I, Alhami I (2015) Clustering and classification of email contents. J King Saud Univ Comput Inf Sci. 27(1):46–57
Rossi RG, Lopes AA, Rezende SO (2016) Optimization and label propagation in bipartite heterogeneous networks to improve transductive classification of texts. Inf Process Manag 52(2):217–257
Barigou F (2018) Impact of instance selection on kNN-based text categorization. J Inf Process Syst 14(2):418–434
Baker K, Bhandari A, Thotakura R (2009) An interactive automatic document classification prototype. In: Proc. of the third workshop on human-computer interaction and information retrieval. pp 30–33
Xuan J et al. (2017) Automatic bug triage using semi-supervised text classification. arXiv preprint arXiv:1704.04769
Aggarwal CC, Zhai CX (2012) A survey of text classification algorithms. In: Mining text data, Springer, Berlin, pp 163–222
Duda RO, Hart PE, Stork DG (2012) Pattern classification. Wiley, Hoboken
MATH Google Scholar
Bravo-Alcobendas D, Sorzano COS (2009) Clustering of biomedical scientific papers. In: 2009 IEEE Int. symp. on intelligent signal processing. pp 205–209
Taheriyan M (2011) Subject classification of research papers based on interrelationships analysis. In: ACM proc. of the 2011 workshop on knowledge discovery, modeling and simulation. pp 39–44
Hanyurwimfura D, Bo L, Njagi D, Dukuzumuremyi JP (2014) A centroid and Relationship based clustering for organizing research papers. Int J Multimed Ubiquitous Eng 9(3):219–234
Nanba H, Kando N, Okumura M (2011) Classification of research papers using citation links and citation types: towards automatic review article generation. Adv Classif Res Online 11(1):117–134
Mohsen T (2011) Subject classification of research papers based on interrelationships analysis. In: Proceeding of the 2011 workshop on knowledge discovery, modeling and simulation. pp 39–44
Nguyen TH, Shirai K (2013) Text classification of technical papers based on text segmentation. In: Int. conf. on application of natural language to information systems. pp 278–284
Gurung P, Wagh R (2017) A study on topic identification using K means clustering algorithm: big vs. small documents. Adv Comput Sci Technol 10(2):221–233
Blei DM, Ng AY, Jordan MI (2003) Latent Dirichlet allocation. J Mach Learn Res 3:993–1022
Jiang Y, Jia A, Feng Y, Zhao D (2012) Recommending academic papers via users’ reading purposes. In: Proc. of the sixth ACM conf. on recommender systems. pp 241–244
Xu R, Wunsch D (2008) Clustering. Wiley, Hoboken
Book Google Scholar
Gan G, Ma C, Wu J (2007) Data clustering: theory, algorithms, and applications. SIAM, Alexandria
Book MATH Google Scholar
Kodinariya TM, Makwana PR (2013) Review on determining number of cluster in K-means clustering. Int J Adv Res Comput Sci Manag Stud 1(6):90–95
Oliveira GV et al (2017) Improving K-means through distributed scalable metaheuristics. Neurocomputing 246:45–57
Rousseeuw PJ (1987) Silhouettes: a graphical aid to the interpretation and validation of cluster analysis. J Comput Appl Math 20:53–65
Article MATH Google Scholar
Scikit-Learn. http://scikit-learn.org/stable/modules/classes.html . Accessed 15 Aug 2018.
Veiga J, Exposito RR, Taboada GL, Tounno J (2016) Flame-MR: an event-driven architecture for MapReduce applications. Future Gener Comput Syst 65:46–56
Ibrahim S, Phan T-D, Carpen-Amarie A, Chihoub H-E, Moise D, Antoniu G (2016) Governing energy consumption in Hadoop through CPU frequency scaling: an analysis. Future Gener Comput Syst 54:219–232
Visentini I, Snidaro L, Foresti GL (2016) Diversity-aware classifier ensemble selection via F-score. Inf Fus 28:24–43
Download references
Acknowledgements
This work was supported by research grants from Daegu Catholic University in 2017.
Author information
Authors and affiliations.
Department of Police Administration, Daegu Catholic University, 13-13 Hayang-ro, Hayang-eup, Gyeongsan, Gyeongbuk, 38430, South Korea
Sang-Woon Kim
School of Information Technology Eng., Daegu Catholic University, 13-13 Hayang-ro, Hayang-eup, Gyeongsan, Gyeongbuk, 38430, South Korea
Joon-Min Gil
You can also search for this author in PubMed Google Scholar
Contributions
SWK proposed a main idea for keyword analysis and edited the manuscript. JMG was a major contributor in writing the manuscript and carried out the performance experiments. Both authors read and approved the final manuscript.
Corresponding author
Correspondence to Joon-Min Gil .
Ethics declarations
Competing interests.
The authors declare that they have no competing interests.
Additional information
Publisher's note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License ( http://creativecommons.org/licenses/by/4.0/ ), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
Reprints and permissions
About this article
Cite this article.
Kim, SW., Gil, JM. Research paper classification systems based on TF-IDF and LDA schemes. Hum. Cent. Comput. Inf. Sci. 9 , 30 (2019). https://doi.org/10.1186/s13673-019-0192-7
Download citation
Received : 03 December 2018
Accepted : 12 August 2019
Published : 26 August 2019
DOI : https://doi.org/10.1186/s13673-019-0192-7
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Paper classification

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
Article-level classification of scientific publications: A comparison of deep learning, direct citation and bibliographic coupling
Maxime rivest.
1 Science-Metrix Inc., Montréal, Québec, Canada
2 Elsevier B.V., Amsterdam, Netherlands
Etienne Vignola-Gagné
Éric archambault.
3 1science, Montréal, Québec, Canada
Associated Data
The data underlying the results presented in the study are available, for scholarly research, from Elsevier BV on the ICSR Lab ( https://www.elsevier.com/icsr/icsrlab ). ICSR Lab is intended for scholarly research only and is a cloud-based computational platform which enables researchers to analyze large structured datasets, including those that power Elsevier solutions such as Scopus and PlumX. All other relevant data are within the manuscript and its Supporting information files.
Classification schemes for scientific activity and publications underpin a large swath of research evaluation practices at the organizational, governmental, and national levels. Several research classifications are currently in use, and they require continuous work as new classification techniques becomes available and as new research topics emerge. Convolutional neural networks, a subset of “deep learning” approaches, have recently offered novel and highly performant methods for classifying voluminous corpora of text. This article benchmarks a deep learning classification technique on more than 40 million scientific articles and on tens of thousands of scholarly journals. The comparison is performed against bibliographic coupling-, direct citation-, and manual-based classifications—the established and most widely used approaches in the field of bibliometrics, and by extension, in many science and innovation policy activities such as grant competition management. The results reveal that the performance of this first iteration of a deep learning approach is equivalent to the graph-based bibliometric approaches. All methods presented are also on par with manual classification. Somewhat surprisingly, no machine learning approaches were found to clearly outperform the simple label propagation approach that is direct citation. In conclusion, deep learning is promising because it performed just as well as the other approaches but has more flexibility to be further improved. For example, a deep neural network incorporating information from the citation network is likely to hold the key to an even better classification algorithm.
Introduction
Bibliographic and bibliometric classifications of research activities and publications have a subtle but pervasive influence on research policy and on performance assessments of all kinds [ 1 , 2 ]. In bibliometric assessments, assigning a research group’s or institution’s output to one field of research rather than another may drastically alter the results of its evaluation. The classification scheme and the design choices extend to the selection of reference groups and benchmark levels used for normalizations and comparisons. Briefly put, nearly all investigators and scholars whose research performance is evaluated with bibliometric indicators, or who have even a passing interest in the citation impact of their written works, are affected by design choices in some of the core classificatory systems of science that are commonly used in research evaluation. This explains why the development of relevant and precise classification systems carries so much weight.
Classifying documents is as old as libraries themselves. For instance, in the great Library of Alexandria, Callimachus classified work in tables called “Pinakes”, which contained the following subjects: rhetoric, law, epic, tragedy, comedy, lyric poetry, history, medicine, mathematics, natural science, and miscellanea [ 3 ]. Classifications are rarely consensual and are typically criticized shortly after inception, and this may have started as early as Aristophanes’s “pugnacious” criticism of Callimachus’s Pinakes [ 4 ].
A classification aims at grouping similar documents under a common class. Documents can share commonalities on various dimensions such as language, field, and so forth. The multiple dimensions of knowledge are pervasive in all characterization of research. As a consequence, classifications are required at various scales (such as at the journal level and the article level), and there are also various types of classes that can be used simultaneously to characterize research activities and publications (e.g., to reflect the organizational structure of universities or that of industry). For example, disciplines and faculties found in academia categorize themselves to reflect their topic of interest, as do Scopus All Science Journal Classification. Contrastingly, US National Library of Medicine’s Medical Subject Headings thesaurus rather aim to reflect a heterogenous mix of subjects and experimental methods.
All classifications of intellectual work present boundary challenges to various degrees (i.e., establishing clearly what is counted in and what is not). Classifying research documents such as journals and articles does not evade these challenges. In research, new knowledge is continuously created, and newer knowledge does not always fit snugly into pre-existing classes [ 5 ]. These characteristic challenges of classifying activities are true at all scales, even though some authors argue they are more particularly problematic at the journal level [ 6 , 7 ]. The “fractal” nature of classification challenges means that scientific journals could frequently be classified in more than one class, but this is equally true of scientific articles. This gives rise to controversies over using mutually exclusive classification schemes, which make reporting more convenient and clearer, and multiple-class assignments, which are ontologically more robust.
One reason to use classifications in science studies and in research assessment is to capture, interpret, and discuss changes in research practices. Some level of abstraction and aggregation is useful to retrieve the higher-level trends and patterns that are most often the object of analyses conducted by institutions, government agencies, and all manner of commentators. For bibliometric evaluation, one of the main reasons to classify scientific work and literature is to normalize bibliometric indices. This is necessary because of disciplinary-specific practices in authorship and citation practices, as well as variations in citation patterns over time [ 8 ].
A defining aspect of classification systems, particularly those used in research evaluation, is the level of aggregation of the classification, such as at the journal or the article level, or at the conference or the presentation level. The classification of scientific work at the journal and article levels has been extensively studied [ 9 – 12 ]. Journal-level classifications often recapitulate historical disciplinary conventions and nomenclatures, making their use more intuitive for certain audiences, including research administrators, policymakers, and funders. They are certainly useful for journal publishers who need to categorize their journals and to present them on their websites in a compact manner, and they can also be used to specify the field of activity of authors [ 13 ].
Though there are many cases where journal-level classifications are useful, there are many cases where classifying articles is preferable and more precise. For instance, it is often useful in bibliometrics to individually classify each article in multidisciplinary/general journals such as PLOS ONE , Nature , or Science . Moreover, there are articles published in, for example, an oncology journal whose core topic could be more relevant to surgery. As a result, journal-level classifications are not tremendously precise compared to those at the article level [ 6 , 8 , 10 , 11 ]. Without negating the need for journal-level classifications for many use cases, there are therefore several reasons to prefer an article-based classification to a journal-based one in a host of research evaluation contexts.
Knowledge is evolving extremely rapidly, and this creates notable classification problems at both the journal and the article levels. For instance, the 1findr [ 14 ] database indexes the content of close to 100,000 active and inactive refereed scholarly journals, whereas the Scopus database [ 15 ] presents a more selective view of a similar corpus by selecting journals that are highly regarded by peers and/or that are the most highly cited in their fields ( Fig 1 ). In both databases, the doubling period is approximately 17 years—meaning these indexes contain as many articles in the last 17 years as during all years prior. This rapid growth of scientific publications creates a huge strain on classification needs and not only because of the large number of articles that need to be classified every day. Furthermore, because of the evolving nature of scientific knowledge, new classes need to be added to classification schemes, which sometimes require overhauling the whole classification scheme and reclassifying thousands of journals and millions of articles. Performing this classification work manually is prohibitively expensive and time-consuming. This means that precise computational methods of classification are sorely needed.

Although articles have been manually classified by librarians for decades if not centuries, computational classification is a comparatively recent development given the requirement for processing capacity and large-scale capture and characterization of scientific publications [ 6 ]. Ongoing investigations carried out since the 1970s have resulted in the creation of a toolbox of classificatory approaches, each supported by varying bases of evidence, and from which investigators must pick and choose a technique based on their object’s features. Article-level computational classification techniques are mostly based on clustering algorithms and use a bottom-up approach, requiring relatively involved follow-up work to link the clusters obtained to categories that are intelligible to potential users. Determination of optimal levels of cluster aggregation is an ongoing development [ 11 , 12 , 16 , 17 ]. Computational classification techniques have also benefited from advances in network analysis and text mining [ 18 – 21 ].
There is a plethora of methods developed and routinely used in the computer science fields of natural language processing and, more recently, machine learning and artificial intelligence (AI). These methods could advantageously be used in bibliometrics. More specifically, deep learning has recently been found to be extremely performant in finding patterns in noisy data, providing the network can be trained on a large enough volume of data. Yet, despite all the work that has been conducted to date on computational classification methods, bibliometricians have yet to make sustained use of AI, and in particular deep learning methods, in their classificatory and clustering practices.
The BioASQ challenge is a notable example of recent use of deep learning to bibliometrics [ 22 ] related task, but BioASQ’s researcher and bibliometrician have so far explored the topic in parallel. The BioASQ challenge aim at promoting methodologies and systems for large-scale biomedical semantic indexing since 2012 by hosting a competition where team try to automatically assign pubmed’s mesh-terms to scholarly publication [ 23 ]. Perhaps surprinsingly, none of the 9182 articles published in journals with (scientomet* OR informetri* OR bibliometri*) in their name ever mentioned BioASQ in their title, abstract, or keywords and only one of those 9182 publications cite a BioASQ related publication (according to this search on Scopus: “SRCTITLE (scientomet* OR informetri* OR bibliometri*) AND REF (bioasq)”). This latter publication is not focused on the subject of text classification.
As just mentioned, most solution to the BioASQ challenge now use technics related to deep neural networks. Several were based on BERT and BioBERT [ 22 ]. In this paper, we have chosen to explore another type of deep neural network (namely character-based neural network) because we felt that our task was different from the BioASQ task and less suited to those architectures. For example, the granularity of the task is several levels of magnitude different, we are classifying 174 subfield instead of approximately 27,000 mesh-terms. Furthermore, our training set is extremely noisy (56% accuracy). This noise may seem like a bad experimental design but is an integral part of the task facing bibliometricians. Indeed, any reclassification system or strategy useful to creating both an article and a journal level classification will need to be robust to noisy training set as it is prohibitively expensive to gather an article level training set. The last difference is that we used a much bigger set of input data and some are less amenable to tokenisation. Indeed, defining tokens for affiliations and source citation or other very rare and specific jargon words seemed suboptimal. Nevertheless, these were useful hypothesis that helped us choose a model architecture but as they are untested hypotheses other architectures should be explored in future works.
Generally speaking, classifications are only as good as the measurement and validation systems used to put them to the test [ 6 , 7 ]. To examine how precise a deep learning classification technique could be, the results of this approach were compared to two other methods frequently used to map science: bibliographic coupling and direct citation links. This examination was based on scores of citation concentration [ 6 ] and on agreement with a benchmark dataset classified manually.
In addition to the novelty of this experiment with the use of a deep learning technique, the computational experiment was conducted at a very large scale. Often due to computational limits, bibliographic coupling has previously tended to be computed on record samples rather than at the corpus level of bibliographic databases such as Scopus and the Web of Science. The present paper examines the use of deep learning with bibliographic coupling, essentially at the corpus level of the Scopus database. One advantage of the approach proposed in the present paper is that it can be used to classify articles, as well as journals through aggregation of the resulting information. Obtaining a single classification scheme at both scales enables direct comparisons of article-level and journal-level classifications, which has seldom been realized in prior studies [ 10 ]. Lastly, and more importantly, whereas a large sample of the research on classifications addresses the creation of new classifications, this paper examines whether computational classification techniques, including the use of AI, can be used advantageously to maintain existing classification schemes compared to the use of a manual method.
Empirical setting and input data
This paper uses Science-Metrix’s bibliometric-optimized version of the Scopus database to retrieve scientific article metadata records and their associated citation data. This implementation used the 8 May 2019 build of the Scopus database. Publication records from the following types of sources were used in the experiment: book series, conference proceedings, and journals. For book series and journals, only the document types articles, conference papers, reviews, and short surveys were kept. For conference proceedings, only those classified as articles, reviews, and conference papers were used. Additional filters were applied such as removing sources not having valid ISSNs. Overall, 41 million Scopus publication records were used in the experiment.
Training set
Science-Metrix’s journal classification was used to seed the journal classes to which articles or journals would be assigned to test the three computational classification techniques. This classification scheme is available in more than 25 languages. It contains a core set of 15,000 journals and is freely available (see science-metrix.com/classification and Supporting information ). An additional set of some 15,000 journals that had fewer than 30 articles each when the original classification was designed are also used internally. Journals are classified in a mutually exclusive manner into 176 scientific subfields, and these subfields are mapped to 22 fields, which themselves are mapped to six domains.
A first version of that classification tree was designed from the top down by examining and drawing best practices from the classifications used by the US National Science Foundation, the Web of Science (now Clarivate, Thomson Reuters at the time), the Australian Research Council, and the European Science Foundation and the OECD. Journals were assigned to categories seeded from these classifications and then run through several iterations of automated suggestions, drawing insight from direct citation, Latent Dirichlet Allocation [ 24 ], and mapping of departmental names. Each iteration was followed by manual corrections to the suggestions obtained with these signals [ 9 ].
Except for the manual addition of new journals in the production version of the classification, the original version of the classification has not been updated in the last 10 years. As a consequence, some journals may have drifted in terms of subfields. In addition, many of the journals would no doubt be classified more precisely if the coupling were performed again due to improved signals (10 more years of publications means substantially more references and citations).
A newer version of this classification is currently under development and provides greater granularity, having 330 subfields, 33 fields, and seven domains. Although it is not yet used in bibliometric production, it can be seen in the 1findr abstracting and indexing database (see 1findr.com). The techniques experimented with here have been used to develop this expanded version, which currently provides a class for more than 56,000 journals, with an equal amount yet to be classified and more than 130 million scholarly articles waiting to be classified.
Article- and journal-level classification
In contrast to a large share of the papers on classification, which use clustering techniques to determine fields and topics using a bottom-up approach, this experiment maps signals obtained from three coupling techniques to the existing Science-Metrix classification. The coupling/linking is performed at the article level, whereas journal-level classes are determined by the most frequent subfield of the sum of articles in each journal.
Benchmarking deep learning against two bibliometric classification techniques
In order to benchmark the result obtained by the more experimental deep learning technique (DL), articles and journals were also mapped to the Science-Metrix classification using two commonly used techniques in bibliometrics: bibliographic coupling (BC) and direct citation (DC).
DL was compared to the other classification techniques using concentration scores of the references in review articles (at both the article and the journal levels) and was also compared to assignations by bibliometrics experts who manually classified articles.
Deep learning: A modified character-based convolutional deep neural network
The classifier deployed a character-based (i.e., the alphabetical letters composing the articles’ text) convolutional deep neural network. From single letters, the model learned words and discovered features. This character-based approach has recently been developed by adapting computer vision strategies to classification and has been used on large datasets of texts such as those from Wikipedia-based ontologies or Yahoo! Answers comment logs [ 25 ]. It has been found to be extremely performant in finding patterns in noisy data.
The model performed best when it was given the following features: authors’ affiliations, names of journals referenced in the bibliography, titles of references, publication abstract, publication keywords, publication title, and classification of publication references. All features, except the classification of publication references, were truncated, but not padded, to a specific maximum length ( Table 1 ) and concatenated into one long string of text, which was itself truncated to a maximum length of 3,000 characters, the length of the 98 th percentile when ordering the concatenated vectors per length.
| Branch | Feature | Length |
|---|---|---|
| Text branch | ||
| Title | 175 | |
| Keywords | 150 | |
| Authors’ affiliations | 450 | |
| Abstract | 1750 | |
| Journal title of references | 1000 | |
| Article title of references | 500 | |
| Subfield branch | ||
| Vector of classifications of a publication’s references | 176 |
The order of this table reflects the items’ order in the model. The lengths represent the maximum allowable length for each feature. Each character was embedded into a one-hot encoded vector of length 68. One-hot encoding is defined as a vector filled with zeroes and ones only at the position assigned to the character. Table 2 presents an example of character embedding for the word “cab”.
| 0 | 1 | 0 | |
| 0 | 0 | 1 | |
| 1 | 0 | 0 |
When encoding, the 26 letters of the English alphabet, the 10 Arabic numbers, several punctuation signs (e.g., "-,;.!?:’_/\|&#$%ˆ&*˜+ = <>()[]{}\), and the space character each occupied one position in the vector. Any character that was not in this list was encoded as a hash sign (i.e., #). The subfield was the only feature not fed to the model as raw text. Instead, the subfield information was encoded into a vector of the proportion of each subfield mentioned in the reference list.
The deep neural network architecture is shown in Fig 2 . A rectified linear unit was used as the activation function between each layer, except after the last one, where a softmax was used instead. The kernels had a width of seven for the first two convolutions and three for the others. The model was trained with a stochastic gradient descent as the optimizer and categorical cross-entropy as the loss function. The gradient descent had a learning rate of 0.01, with a nesterov momentum of 0.9 and a decay of 0.000001. The model was trained on batches of 64 publications at a time and an epoch was considered passed after ~11,000 articles. The model was trained on a random sample of 24,000,000 articles.

Other machine learning algorithms
In addition to DL, three other machine learning approaches were considered for inclusion in the comparison to established bibliometric algorithm-based classifications. These are presented below but were all outperformed by the DL (the modified character-based convolutional deep neural network presented above) approach in the end. To keep the paper focused on the comparison between DL and bibliometric approaches, the rest of the paper will not present results for these three other methods after this section. However, the interested reader can find the results of our experiments in the ( S1 and S2 Figs, S1 and S3 Tables).
A character-based neural network, without the above-mentioned modifications, was one of the methods tested. The model architecture followed the small ConvNets developed in Zhang et al. (preprint) (20), but a short description follows. The input layer was a character-encoded 2D matrix with 70 characters. Then, the input layer was fed into two consecutive layers of 256 kernels of width 7. Those two layers were each followed by a maxpooling layer of width equal to 3 and activated with a rectified linear unit. Then, four layers each of 256 features but this time of width 3 and without maxpooling followed the two initial layers of width 7. Then, the layer was flattened and passed to two fully connected layers of 1,024 nodes each, followed by a 0.5 dropout layer. Finally, after the last dropout we used a dense layer with as many nodes as there were subfields to predict. This last layer was softmax activated. A stochastic gradient descent with learning rate 0.01, a nesterov momentum of 0.9, and decay of 0.000001 was used as the optimizer. Mini batches were of size 64 and an epoch was considered passed (for the learning rate decay) after 11,000 articles were processed. The model was trained on a random sample of 24,000,000 articles.
A support vector machine (SVM) and a logistic regression were also tested as alternative shallow machine learning strategies. Both were based on term frequency–inverse document frequency (TF–IDF) one and two grams. The 150,000 tokens with the highest TF–IDF scores were used. The SVM and logistic regression models were trained on 1 million articles. There was no need to train on more articles since preliminary tests showed no model improvements after 0.75 million articles.
Bibliographic coupling
A BC-based similarity measure between each publication P and each subfield S was calculated and normalized as follows:
where X is the set of all BC values between publication P and all other publications of subfield S , and T is total number of citations given by all papers of subfield S .
Direct citation
A DC-based similarity measure between one publication P and one subfield S was calculated and normalized as follows:
where inCits is the number of citations received by paper P from all papers in subfield S , outCits is the number of citations given by paper P to subfield S , subfieldNR is the total number of citations given by subfield S , and paperNR is the total number of citations given by paper P . In the end, paper P is classified in the subfield S with the highest DCsimilarity . This is calculated for all papers crossed with all subfields.
Bibliometricians and machine learning researchers have different approaches to evaluate classification tasks. In bibliometrics, the task is often to search for the “true” classification, and no clear gold standard datasets exist for article-level classification of scientific publications. To mitigate the lack of a gold standard and in an attempt to quantitatively evaluate classification schemes, the concentration of reviews’ references (Herfindahl index) currently serves as the evaluation metric for such a task (more on that below) [ 6 ]. In machine learning research, it has become standard to evaluate classification methods by splitting the dataset into three sections: training, validation, and test. Unfortunately, this was not strictly possible here because the bibliometrics-based classification strategies (DC, BC) do not lend themselves well to such a dataset split. More importantly, the training set that we used here is only a rough approximation of what we want to achieve and not the ground truth per se. Indeed, the training set comprises articles roughly labeled by extending a journal’s label (from disciplinary journals) to all its articles, whereas our task is to classify each article independently of their journal classification. By doing so, we created a training set for which 56% of the articles corresponded to the mode classification of 5 experts. That said, we are still presenting those standard evaluation metrics in the supplementary material but we focus on two other evaluation strategies—namely, a human, manually assembled gold standard (which acts as our test set) and the Herfindahl index.
Performance measurements were produced for both article- and journal-level classification algorithms. We note already, however, that the bibliometric community is decisively moving toward article-level classification, where possible, for the reasons presented above, and that measurements for journal-based classification algorithms benefit from prior use of citation-based algorithms in the construction of the Science-Metrix ontology.
Comparison to training set
Precision, recall, specificity, sensitivity, and F1 were calculated. To measure the scores, the complete dataset was used (as opposed to a validation/test split); this was done to avoid biasing the results toward BC and DC as they are not amenable to the train/validation/test split. Moreover, in all machine learning cases, the training datasets were smaller than the validation dataset, which limits the confounding effect that overfitting could have. Furthermore, the training set is not ground truth, in fact only 56% of the articles corresponded to the mode classification of 5 experts. In other words, 44% of the labels in the training set were sub optimally assigned. This limits greatly the relevance of such metrics. Thus, the results for those are presented in the supplementary materials. Comparison to training set is done mostly to follow academic standard of the machine learning discipline, but the reader should interpret the results from this evaluation with great caution because the training set has 44% of it’s label sub optimally assigned. No statistical test were used as we measured precision, recall, specificity, sensitivity, and F1 on the whole dataset relevant for this task (i.e., the population) as opposed to using a few random samples [ 26 ].
Benchmark 1 (B1): Citation concentration (Herfindahl index)
As proposed by Klavans and Boyack [ 6 ], a citation concentration score was calculated on all articles having 100 or more references that could successfully be classified (i.e., the cited journals were in the set of classified journals). This technique assumes that large review articles tend to present an exhaustive analysis of a phenomenon by summarizing content from a large volume of prior research in a single or a few research subfields and specialties. In other words, and everything being equal, review papers would inherently capture clusters of topically related publications and would therefore act as appropriate reference points for benchmarking degrees of disciplinary concentration. A more accurate classification algorithm should therefore lead to a larger Herfindahl index. This use of the Herfindahl index as an accuracy measure applied to bibliometric classification appears to have been a novel development by Boyack and Klavans [ 27 , 28 ]. Citation distribution profiles have also been measured with the Herfindahl index in a small number of unrelated studies aiming to assess the concentration and direction of “citedness” (i.e., uptake) among large populations of peer-reviewed articles [ 29 ].
The Herfindahl index itself originates in the economic literature but has been applied to measure the concentration of citations within a corpus in the last decade [ 29 ]. It has also been applied as a measure of disciplinary diversity among citations. Klavans and Boyack’s application of the index to measure clustering performance, however, appears to us to be a novel development.
Herfindahl index scores were measured for 379,413 papers. Citation concentration by subfield was calculated with the Herfindahl index for DL, BC, and BC, at the article and journal levels.
Benchmark 2 (B2): Manual article classification
To create a test set, five bibliometric analysts were asked to manually classify the same set of 100 randomly sampled scientific publications from disciplinary journals, and six other analysts were asked to do the same for another set of 100 articles from multidisciplinary journals. The analysts were asked to classify the publications as best they could, using whichever information was at their disposal. Most analysts used search engines to acquire additional information about authors and their affiliation. Analysts could assign more than one subfield to a publication when they were uncertain, in which case they were asked to rank subfields by relevance.
For each of the three classification techniques, the percentage of agreement between the computational and the manual classification was computed (the subfield most often assigned as the first choice by manual classification was used as the benchmark; in case of a tie, all top subfields were kept and computed classes were given a point for matching one or the other).
A comparison between each classification strategy and the Science-Metrix classification (which served as the training dataset) provided a first proxy to evaluate the quality of a classification strategy. We see that DL tended to replicate Science-Metrix classification more than BC and DC, given its higher macro-averaged F1 score and much higher macro-averaged precision than those calculated for BC and DC ( S3 Table and see S1 Table for precision per subfield). That said, all journal-level classifications strategies were closer to the Science-Metrix journal level classification than any article-level classification strategy ( S3 Table ), which can be easily explained by the fact that the Science-Metrix classification is itself at the journal level. A measurement of the pairs of the most frequently substituted subfields by article-level DL and DC revealed that these pairs were generally formed of topically similar subfields. For example, the subfield Networking & telecommunications was assigned to an article belonging to Automobile design & engineering (according to the journal-level Science-Metrix classification) 65% of the time by DL (DC = 59%), Economic theory was substituted with Economics 51% of the time (DC = 34%), Mining & metallurgy was confused with Materials 47% of the time for DL (DC = 23%), and Horticulture with Plant biology & botany 42% of the time for DL (DC = 39%) (see S2 Table for full results). Altogether, these results show that very different strategies can similarly approximate a journal classification. This first set of results should be interpreted with caution since the Science-Metrix classification was an imperfect (53% accurate) journal-level classification used as a training set in the absence of a gold standard to act as a ground truth.
Median Herfindahl index scores obtained for the three classification techniques (B1) reveal that, though the scores are not all that markedly different, DL is the least effective technique for classifying articles (DL = 0.35 vs. 0.39 for BC and 0.43 for DC) and is fairly similar to DC when classifying journals (tie at 0.29 for DL and DC, with BC slightly lower at 0.27) ( Fig 3 ). DL’s (article) median was the lowest of the three techniques because it had fewer high scores (as opposed to more low scores). This is shown in the width of the violins and the spread of the top boxes of the boxplots in Fig 3 . More precisely, the width of the bottom parts of the violins are equivalent (as is the spread of the lower boxes), whereas the width of the top parts of the violins are narrowest at the top for DL.

The curves show a distribution of all the 379,413 Herfindahl scores that were computed for each classification technique, while the pale grey thicker vertical lines are outliers.
Fig 4 shows the difference in Herfindahl scores between each technique, at both the article and journal levels. The scores in rows are subtracted from those in columns, each time involving scores computed on all 379,413 papers having more than 100 matched references. One can see that DL yielded a Herfindahl index score that was 0.04 lower than BC and 0.07 lower than DC at the article level. The results show that article-level classifications always provided better scores than any of these techniques at the journal level.

The scores in rows are subtracted from those in columns, each time involving scores computed on all 379,413 papers having more than 100 matched references. A green cell indicates that the technique listed in the row yielded greater concentration than the technique listed in the column, and a red cell indicates the opposite.
Benchmark 2 (B2) examines how computational techniques compare to manual classification. Usually, the subfields selected by experts were related to each other, but disagreement between experts was sometimes high. For example, for one document, two analysts chose the subfield biophysics, whereas others chose anatomy & morphology, bioinformatics, biomedical engineering, or evolutionary biology ( Table 3 ). In one case, the five experts classified an article in five different subfields and in four different fields of science. Another scenario for disagreement was when a publication was interdisciplinary in its nature or applications (see the third document in Table 3 ). In contrast, article-level DC and BC consistently gave the same results, even in cases of overall disagreement among bibliometrics experts. In many cases, computationally obtained classifications tended to remain plausible, even in cases of divergence from the experts’ consensus.
| Agreement between experts | Documents | Number of different experts’ first choices | Most mentioned subfield by experts | Classifications | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Article level | Journal level | |||||||||||
| Subfields | Fields | Rank 1 | Rank 2 | DC | BC | DL | BC | DL | DC | SM | ||
| Rabinovitch A, Aviram I, Gulko N, Ovsyshcher E. A model for the propagation of action potentials in non-uniformly excitable media. Journal of theoretical biology. 1999 Jan 21;196(2):141–54. | 5 | 4 | *biophysics | *anatomy & morphology | fluids & plasmas | fluids & plasmas | fluids & plasmas | bioinformatics | evolutionary biology | evolutionary biology | evolutionary biology | |
| *bioinformatics | ||||||||||||
| *biomedical engineering | ||||||||||||
| *evolutionary biology | ||||||||||||
| Yamauchi S, Yamamoto N, Kinoshita Y. Improved stereoselective synthesis of optically active methylene lactone, key intermediate for the synthesis of 1, 2-oxidized furofuran lignan, by direct α-methylenation to butanolide. Bioscience, biotechnology, and biochemistry. 2000;64(10):2209–15. | 4 | 3 | *organic chemistry | *biochemistry & molecular biology | organic chemistry | organic chemistry | organic chemistry | biotechnology | biotechnology | biotechnology | biotechnology | |
| *biophysics | ||||||||||||
| *biotechnology | ||||||||||||
| Udhaya K, Sarala Devi KV, Sridhar J. Regression equation for estimation of length of humerus from its segments: A South Indian population study. Journal of Clinical and Diagnostic Research. 2011 Aug;5(4):783–6. | 5 | 4 | *anatomy & morphology | *archaeology | legal & forensic medicine | legal & forensic medicine | anatomy & morphology | dentistry | general & internal medicine | dentistry | pediatrics | |
| *general & internal medicine | ||||||||||||
| *pediatrics | ||||||||||||
| *public health | ||||||||||||
| Richards SN, Bryant JJ, Croom SM, Hopkins AM, Schaefer AL, Bland-Hawthorn J, Allen JT, Brough S, Cecil G, Cortese L, Fogarty LM. Erratum: the SAMI Galaxy Survey: can we trust aperture corrections to predict star formation?. Monthly Notices of the Royal Astronomical Society. 2016 May 11;458(2):1300-. | 1 | 1 | *astronomy & astrophysics | astronomy & astrophysics | astronomy & astrophysics | general physics | astronomy & astrophysics | astronomy & astrophysics | astronomy & astrophysics | astronomy & astrophysics | ||
| Meister DW, Hearns KA, Carlson MG. Dorsal scaphoid subluxation on sagittal magnetic resonance imaging as a marker for scapholunate ligament tear. The Journal of Hand Surgery. 2017 Sep 1;42(9):717–21. | 1 | 1 | *orthopedics | orthopedics | orthopedics | orthopedics | orthopedics | orthopedics | orthopedics | orthopedics | ||
| Gusakov EZ, Popov AY, Saveliev AN. Saturation of low-threshold two-plasmon parametric decay leading to excitation of one localized upper hybrid wave. Physics of Plasmas. 2018 Jun 1;25(6):062106. | 1 | 1 | *fluids & plasmas | fluids & plasmas | fluids & plasmas | fluids & plasmas | fluids & plasmas | fluids & plasmas | fluids & plasmas | fluids & plasmas | ||
Three of the most and three of least agreed upon classifications are presented.
Overall, B2 reveals that classification techniques were more accurate, in addition to having more similar scores between one another in the disciplinary dataset than in the multidisciplinary dataset ( Fig 5 ). For both the disciplinary dataset and the multidisciplinary dataset, all computational classification techniques performed at a broadly similar level (i.e., all 95% confidence intervals overlapped).

Two datasets (disciplinary vs. multidisciplinary) of 100 papers were classified by five and six experts respectively to find the modal classification of each article.
Based on the examination of the differences obtained between each classification technique, considering the slight differences between these techniques, one can state that each technique is similarly effective overall to the two others. Though this suggests that classifying articles with DC, BC, or DL does not make a huge difference when mapping to an existing classification scheme, it is clear that it is always more precise for metrics to be based on an article-level assignment of classes, as shown previously [ 6 ].
Though the tests conducted here do not show DL to outperform other classification techniques overall it also worked just as well as BC and DC to classify articles published in disciplinary and multidisciplinary journals (B2). DL did not perform as well as BC and DC in the reference concentration test (B1) at both the article and journal levels, but it did not trail these techniques by a long measure either.
DC seemed to perform slightly better overall, yielding a high concentration of references in a subfield for review-type articles with large numbers of references (B1), and agreeing as much as others with experts (B2). DC and BC are well-established methods that have benefited from a decade of large-scale implementations and nearly five decades of experimentation at various scales. This paper shows that those strategies can be effectively applied to move from a journal to an article level classificationre for an existing taxonomy of science, subject to the existence of a seed dataset (the Science-Metrix classification was used to seed subfields to articles, based on the subfield of the journals in which they were published). This is quite different from the bottom-up, emergent clustering frequently done with those similarity metrics.
As multiple prior studies have reported, different classification methods are associated with trade-offs, and it may be difficult to single out one clearly superior approach [ 17 , 20 ]. The findings of this experiment support the view that a toolset of classification approaches is available to deal with multiple sources of information, contexts, and goals and audiences for bibliometric work.
The techniques used in the present experiment made it possible to classify both articles and journals. This enables continuity with the classification schemes already used by stakeholders. As an example, the article-level DL algorithm presented here was recently used to improve the classification scheme underpinning bibliometric data production as part of the National Science Board’s Science and Engineering Indicators 2020 series of reports. The algorithm made it possible to redistribute articles from multidisciplinary journals within the 176 subfields of the Science-Metrix classification, in an effort that also involved achieving concordances with the National Science Foundation’s own Taxonomy of Disciplines.
Using the same classification scheme for articles and for journals has yielded results that further support the use of article-level classifications of science when computing metrics at the article level. Classifying articles on an individual basis yields more precise results than using journal-level classes at the article level, as practitioners often do when using the journal-based National Science Foundation classification or those offered in the Web of Science and Scopus.
DL presents the benefit of being able to classify articles even in the absence of reference/citation-related information, with more work needed to confirm this potential. DL also has the potential to aggregate features that were usually kept apart. As a first step toward that, this version of the DL model combined topical information (from the titles, keywords, and abstracts) with affiliation information (such as authors’ department names) and citation information (in the form of the distribution of classified references), and the appropriate weighting of those sources of information was tuned through the training of the model. It is conceivable that the Herfindahl index could be used in the creation of a loss function, which would let the model optimize that metric. Finally, there is nothing precluding the addition to the model of data obtained by BC and DC, and DL therefore appears to be highly promising as a solution to help classify both journals and articles in a cost-effective, big data production context.
There has been recurring debate about the best methods for establishing and improving on the taxonomies and classifications of science used in the macro-organization of science, including for science policy planning, large-scale research assessments, and grant management. While bibliometric researchers tend to favor classifications developed with bottom-up clustering approaches, science policy bodies and funders still use and establish manually derived (i.e., reliant on expert judgment) rather than algorithmically derived classifications because of the continuity they offer with established institutional practices.
In this article, we presented a new approach to science classification that draws on a combination of deep learning approaches and bibliographic coupling that bridges article-level, bottom-up classifications of research work and predefined categories. The three approaches performed similarly to experts manual classification when task with creating an article-level classification from a journal-level classification. In addition, we hypothesize that the deep learning approach has high potential for further improvement and refinement going forward, notably by experimenting with graph neural networks to take advantage of the citation network and the author’s collaboration network, or by including the Herfindahl index in the loss function, or simply by better combining bibliographic coupling and direct citation with the modified character-based neural network presented here.
Supporting information
Acknowledgments.
We would like to thank Alexandre Bédard-Vallée, Grégoire Côté, Paul Khayat, Isabelle Labrosse, Christian Lefebvre, Simon Provençal, Henrique Pinheiro, and Guillaume Roberge for their assistance in manually classifying scientific publications. We would also like to thank Beverley Mitchell for copy editing the article and David Campbell for his feedback regarding the methodological design.
Funding Statement
The funder, Elsevier BV and its daughter company Science-Metrix Inc., 1science, provided support in the form of salaries for authors MR, EVG, EA, but did not have any additional role in the study design, data collection and analysis, decision to publish, or preparation of the manuscript. The specific roles of these authors are articulated in the ‘author contributions’ section.
Data Availability

We apologize for the inconvenience...
To ensure we keep this website safe, please can you confirm you are a human by ticking the box below.
If you are unable to complete the above request please contact us using the below link, providing a screenshot of your experience.
https://ioppublishing.org/contacts/
Comparing paper level classifications across different methods and systems: an investigation of Nature publications
- Published: 26 March 2022
- Volume 127 , pages 7633–7651, ( 2022 )
Cite this article

- Lin Zhang ORCID: orcid.org/0000-0003-0526-9677 1 , 2 , 3 ,
- Beibei Sun 1 , 2 , 3 ,
- Fei Shu 4 &
- Ying Huang 1 , 2 , 3
1078 Accesses
10 Citations
3 Altmetric
Explore all metrics
The classification of scientific literature into appropriate disciplines is an essential precondition of valid scientometric analysis and significant to the practice of research assessment. In this paper, we compared the classification of publications in Nature based on three different approaches across three different systems. These were: Web of Science (WoS) subject categories (SCs) provided by InCites, which are based on the disciplinary affiliation of the majority of a paper’s references; Fields of Research (FoR) classification provided by Dimensions, which are derived from machine learning techniques; and subjects classification provided by Springer Nature, which are based on author-selected subject terms in the publisher’s tagging system. The results show, first, that the single category assignment in InCites is not appropriate for a large number of papers. Second, only 27% of papers share the same fields between FoR classification in Dimensions and subjects classification in Springer Nature, revealing great inconsistencies between these machine-determined versus human-judged approaches. Being aware of the characteristics and limitations of the ways we categorize research publications is important to research management.
This is a preview of subscription content, log in via an institution to check access.
Access this article
Subscribe and save.
- Get 10 units per month
- Download Article/Chapter or eBook
- 1 Unit = 1 Article or 1 Chapter
- Cancel anytime
Price includes VAT (Russian Federation)
Instant access to the full article PDF.
Rent this article via DeepDyve
Institutional subscriptions
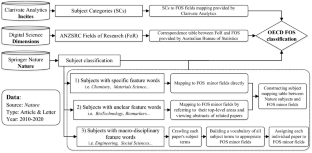
Similar content being viewed by others

A logical set theory approach to journal subject classification analysis: intra-system irregularities and inter-system discrepancies in Web of Science and Scopus

The accuracy of field classifications for journals in Scopus

Analyzing journal category assignment using a paper-level classification system: multidisciplinary sciences journals
Explore related subjects.
- Artificial Intelligence
The document types, article and letter, are defined on the Nature website. Both are peer-reviewed research papers published in Nature .
ANZSRC FoR classification have now been updated to 2020 and are significantly different to the 2008 version. However, since our data was exported from Dimensions in which only FoR 2008 is available, we applied FoR 2008 in this study.
https://www.nature.com/nature/browse-subjects .
https://incites.help.clarivate.com/Content/Research-Areas/oecd-category-schema.htm .
https://www.abs.gov.au/AUSSTATS/[email protected]/DetailsPage/1297.02008?OpenDocument .
Authors are required to choose the most relevant subject categories (including the top-level subject areas, the second level subjects, and the more fine-grained levels of specific subject terms) when submitting their manuscripts to Springer Nature. These fine-grained subject terms are presented on the webpage of each paper.
Abramo, G., D’Angelo, C. A., & Zhang, L. (2018). A comparison of two approaches for measuring interdisciplinary research output: The disciplinary diversity of authors vs the disciplinary diversity of the reference list. Journal of Informetrics, 12 (4), 1182–1193.
Article Google Scholar
Ahlgren, P., Chen, Y., Colliander, C., et al. (2020). Enhancing direct citations: A comparison of relatedness measures for community detection in a large set of PubMed publications. Quantitative Science Studies, 1 (2), 714–729.
Google Scholar
Baharudin, B., Lee, L. H., & Khan, K. (2010). A review of machine learning algorithms for text-documents classification. Journal of Advances in Information Technology, 1 , 4–20.
Ballesta, S., Shi, W., Conen, K. E., et al. (2020). Values encoded in orbitofrontal cortex are causally related to economic choices. Nature, 588 (7838), 450–453.
Bornmann, L. (2018). Field classification of publications in Dimensions: A first case study testing its reliability and validity. Scientometrics, 117 (1), 637–640.
Boyack, K. W., Newman, D., Duhon, R. J., et al. (2011). Clustering more than two million biomedical publications: Comparing the accuracies of nine text-based similarity approaches. Plos One, 6 (3), e18029.
Carley, S., Porter, A. L., Rafols, I., et al. (2017). Visualization of disciplinary profiles: Enhanced science overlay maps. Journal of Data and Information Science, 2 (3), 68–111.
Chapman, H. N., Fromme, P., Barty, A., et al. (2011). Femtosecond X-ray protein nanocrystallography. Nature, 470 (7332), 73–77.
Dehmamy, N., Milanlouei, S., & Barabási, A.-L. (2018). A structural transition in physical networks. Nature, 563 (7733), 676–680.
Eykens, J., Guns, R., & Engels, T. C. E. (2019). Article level classification of publications in sociology: An experimental assessment of supervised machine learning approaches. In: Proceedings of the 17th International Conference on Scientometrics & Informetrics , Rome (Italy), 2–5 September, 738–743.
Glänzel, W., & Debackere, K. (2021). Various aspects of interdisciplinarity in research and how to quantify and measure those. Scientometrics . https://doi.org/10.1007/s11192-11021-04133-11194
Glänzel, W., & Schubert, A. (2003). A new classification scheme of science fields and subfields designed for scientometric evaluation purposes. Scientometrics, 56 (3), 357–367.
Glänzel, W., Thijs, B., & Huang, Y. (2021). Improving the precision of subject assignment for disparity measurement in studies of interdisciplinary research. FEB Research Report MSI_2104 , 1–12.
Gläser, J., Glänzel, W., & Scharnhorst, A. (2017). Same data—Different results? Towards a comparative approach to the identification of thematic structures in science. Scientometrics, 111 (2), 981–998.
Gómez-Núñez, A. J., Batagelj, V., Vargas-Quesada, B., et al. (2014). Optimizing SCImago Journal & Country Rank classification by community detection. Journal of Informetrics, 8 (2), 369–383.
Gómez-Núñez, A. J., Vargas-Quesada, B., & de Moya-Anegón, F. (2016). Updating the SCImago journal and country rank classification: A new approach using Ward’s clustering and alternative combination of citation measures. Journal of the Association for Information Science and Technology, 67 (1), 178–190.
Haunschild, R., Schier, H., Marx, W., et al. (2018). Algorithmically generated subject categories based on citation relations: An empirical micro study using papers on overall water splitting. Journal of Informetrics, 12 (2), 436–447.
Janssens, F., Zhang, L., Moor, B. D., et al. (2009). Hybrid clustering for validation and improvement of subject-classification schemes. Information Processing & Management, 45 (6), 683–702.
Kandimalla, B., Rohatgi, S., Wu, J., et al. (2021). Large scale subject category classification of scholarly papers with deep attentive neural networks. Frontiers in Research Metrics and Analytics, 5 , 31.
Klavans, R., & Boyack, K. W. (2017). Which type of citation analysis generates the most accurate taxonomy of scientific and technical knowledge? Journal of the Association for Information Science and Technology, 68 (4), 984–998.
Leydesdorff, L., & Bornmann, L. (2016). The operationalization of “fields” as WoS subject categories (WCs) in evaluative bibliometrics: The cases of “library and information science” and “science & technology studies.” Journal of the Association for Information Science and Technology, 67 (3), 707–714.
Leydesdorff, L., & Rafols, I. (2009). A global map of science based on the ISI subject categories. Journal of the American Society for Information Science and Technology, 60 (2), 348–362.
Liu, X., Glänzel, W., & De Moor, B. (2012). Optimal and hierarchical clustering of large-scale hybrid networks for scientific mapping. Scientometrics, 91 (2), 473–493.
McGillivray, B., & Astell, M. (2019). The relationship between usage and citations in an open access mega-journal. Scientometrics, 121 (2), 817–838.
Milojević, S. (2020). Practical method to reclassify Web of Science articles into unique subject categories and broad disciplines. Quantitative Science Studies, 1 (1), 183–206.
Nam, S., Jeong, S., Kim, S.-K., et al. (2016). Structuralizing biomedical abstracts with discriminative linguistic features. Computers in Biology and Medicine, 79 , 276–285.
Park, I.-U., Peacey, M. W., & Munafò, M. R. (2014). Modelling the effects of subjective and objective decision making in scientific peer review. Nature, 506 (7486), 93–96.
Porter, A. L., & Rafols, I. (2009). Is science becoming more interdisciplinary? Measuring and mapping six research fields over time. Scientometrics, 81 (3), 719–745.
Rafols, I., & Leydesdorff, L. (2009). Content-based and algorithmic classifications of journals: Perspectives on the dynamics of scientific communication and indexer effects. Journal of the American Society for Information Science and Technology, 60 (9), 1823–1835.
Roach, N. T., Venkadesan, M., Rainbow, M. J., et al. (2013). Elastic energy storage in the shoulder and the evolution of high-speed throwing in Homo. Nature, 498 (7455), 483–486.
Rutishauser, U., Ross, I. B., Mamelak, A. N., et al. (2010). Human memory strength is predicted by theta-frequency phase-locking of single neurons. Nature, 464 (7290), 903–907.
Shu, F., Julien, C.-A., Zhang, L., et al. (2019). Comparing journal and paper level classifications of science. Journal of Informetrics, 13 (1), 202–225.
Shu, F., Ma, Y., Qiu, J., et al. (2020). Classifications of science and their effects on bibliometric evaluations. Scientometrics, 125 (3), 2727–2744.
Small, H. (1973). Co-citation in the scientific literature: A new measure of the relationship between two documents. Journal of the American Society for Information Science, 24 (4), 265–269.
Article MathSciNet Google Scholar
Szomszor, M., Adams, J., Pendlebury, D. A., et al. (2021). Data categorization: Understanding choices and outcomes. The Global Research Report from the Institute for Scientific Information .
Tannenbaum, C., Ellis, R. P., Eyssel, F., et al. (2019). Sex and gender analysis improves science and engineering. Nature, 575 (7781), 137–146.
Thijs, B., Zhang, L., & Glänzel, W. (2015). Bibliographic coupling and hierarchical clustering for the validation and improvement of subject-classification schemes. Scientometrics, 105 (3), 1453–1467.
Traag, V. A., Waltman, L., & van Eck, N. J. (2019). From Louvain to Leiden: Guaranteeing well-connected communities. Scientific Reports, 9 (1), 5233.
Van Eck, N. J., Waltman, L., Van Raan, A. F. J., et al. (2013). Citation analysis may severely underestimate the impact of clinical research as compared to basic research. PLoS ONE, 8 (4), e0062395.
Waltman, L., & van Eck, N. J. (2012). A new methodology for constructing a publication-level classification system of science. Journal of the American Society for Information Science and Technology, 63 (12), 2378–2392.
Waltman, L., & Van Eck, N. J. (2013). Source normalized indicators of citation impact: An overview of different approaches and an empirical comparison. Scientometrics, 96 (3), 699–716.
Waltman, L., & van Eck, N. J. (2019). Field normalization of scientometric indicators. In W. Glänzel, H. F. Moed, U. Schmoch, et al. (Eds.), Springer Handbook of Science and Technology Indicators (pp. 281–300). Springer.
Waltman, L., Van Eck, N. J., & Noyons, E. C. M. (2010). A unified approach to mapping and clustering of bibliometric networks. Journal of Informetrics, 4 (4), 629–635.
Zhang, L., Janssens, F., Liang, L., et al. (2010). Journal cross-citation analysis for validation and improvement of journal-based subject classification in bibliometric research. Scientometrics, 82 (3), 687–706.
Zhang, L., Rousseau, R., & Glänzel, W. (2016). Diversity of references as an indicator of the interdisciplinarity of journals: Taking similarity between subject fields into account. Journal of the Association for Information Science and Technology, 67 (5), 1257–1265.
Zhang, L., Sun, B., Chinchilla-Rodríguez, Z., et al. (2018). Interdisciplinarity and collaboration: On the relationship between disciplinary diversity in departmental affiliations and reference lists. Scientometrics, 117 (1), 271–291.
Zhang, L., Sun, B., Jiang, L., et al. (2021a). On the relationship between interdisciplinarity and impact: Distinct effects on academic and broader impact. Research Evaluation, 30 (3), 256–268.
Zhang, L., Sun, B., Shu, F., et al. (2021b). Comparing paper level classifications across different methods and systems: An investigation on Nature publications . In: Proceedings of the 18th International Conference on Scientometrics and Informetrics , Leuven (Belgium), 12–15 July, 1319–1324.
Download references
Acknowledgements
The present study is an extended version of an article presented at the 18th International Conference on Scientometrics and Informetrics, Leuven (Belgium), 12–15 July 2021 (Zhang et al. 2021b ). The authors would like to acknowledge support from the National Natural Science Foundation of China (Grant Nos. 71974150, 72004169, 72074029), the National Laboratory Centre for Library and Information Science at Wuhan University, and the project “Interdisciplinarity & Impact” (2019–2023) funded by the Flemish Government.
Author information
Authors and affiliations.
School of Information Management, Wuhan University, Wuhan, China
Lin Zhang, Beibei Sun & Ying Huang
Center for Science, Technology & Education Assessment, Wuhan University, Wuhan, China
Department of MSI & ECOOM, KU Leuven, Leuven, Belgium
Chinese Academy of Science and Education Evaluation, Hangzhou Dianzi University, Hangzhou, China
You can also search for this author in PubMed Google Scholar
Corresponding author
Correspondence to Lin Zhang .
Ethics declarations
Conflict of interest.
The first author (Lin Zhang) is the Co-Editor-in-Chief of Scientometrics .
Rights and permissions
Reprints and permissions
About this article
Zhang, L., Sun, B., Shu, F. et al. Comparing paper level classifications across different methods and systems: an investigation of Nature publications. Scientometrics 127 , 7633–7651 (2022). https://doi.org/10.1007/s11192-022-04352-3
Download citation
Received : 23 October 2021
Accepted : 11 March 2022
Published : 26 March 2022
Issue Date : December 2022
DOI : https://doi.org/10.1007/s11192-022-04352-3
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Paper level classifications
- WoS subject categories
- Fields of research (FoR)
- Nature subjects; InCites; Dimensions; Springer Nature
- Find a journal
- Publish with us
- Track your research
ORIGINAL RESEARCH article
Large scale subject category classification of scholarly papers with deep attentive neural networks.

- 1 Computer Science and Engineering, Pennsylvania State University, University Park, PA, United States
- 2 Information Sciences and Technology, Pennsylvania State University, University Park, PA, United States
- 3 Computer Science, Old Dominion University, Norfolk, VA, United States
Subject categories of scholarly papers generally refer to the knowledge domain(s) to which the papers belong, examples being computer science or physics. Subject category classification is a prerequisite for bibliometric studies, organizing scientific publications for domain knowledge extraction, and facilitating faceted searches for digital library search engines. Unfortunately, many academic papers do not have such information as part of their metadata. Most existing methods for solving this task focus on unsupervised learning that often relies on citation networks. However, a complete list of papers citing the current paper may not be readily available. In particular, new papers that have few or no citations cannot be classified using such methods. Here, we propose a deep attentive neural network (DANN) that classifies scholarly papers using only their abstracts. The network is trained using nine million abstracts from Web of Science (WoS). We also use the WoS schema that covers 104 subject categories. The proposed network consists of two bi-directional recurrent neural networks followed by an attention layer. We compare our model against baselines by varying the architecture and text representation. Our best model achieves micro- F 1 measure of 0.76 with F 1 of individual subject categories ranging from 0.50 to 0.95. The results showed the importance of retraining word embedding models to maximize the vocabulary overlap and the effectiveness of the attention mechanism. The combination of word vectors with TFIDF outperforms character and sentence level embedding models. We discuss imbalanced samples and overlapping categories and suggest possible strategies for mitigation. We also determine the subject category distribution in CiteSeerX by classifying a random sample of one million academic papers.
1 Introduction
A recent estimate of the total number of English research articles available online was at least 114 million ( Khabsa and Giles, 2014 ). Studies indicate the number of academic papers doubles every 10–15 years ( Larsen and von Ins, 2010 ). The continued growth of scholarly papers increases the challenges to accurately find relevant research papers, especially when papers in different subject categories (SCs) are mixed in a search engine’s collection. Searches based on only keywords may no longer be the most efficient method ( Matsuda and Fukushima, 1999 ) to use. This often happens when the same query terms appear in multiple research areas. For example, querying “neuron” in Google Scholar returns documents in both computer science and neuroscience. Search results can also belong to diverse domains when the query terms contain acronyms. For example, querying “NLP” returns documents in linguistics (meaning “neuro-linguistic programming”) and computer science (meaning “natural language processing”). If the SCs of documents are available, the users can narrow search results by specifying an SC, which effectively increases the precision of the query results, assuming SCs are accurately assigned to documents. Also, delineation of scientific domains is a preliminary tasks of many bibliometric studies at the meso-level. Accurate categorization of research articles is a prerequisite for discovering various dimensions of scientific activity in epistemology ( Collins, 1992 ) and sociology ( Barnes et al., 1996 ), as well as the invisible colleges, which are implicit academic networks ( Zitt et al., 2019 ). To build a web-scale knowledge system, it is necessary to organize scientific publications into a hierarchical concept structure, which further requires categorization of research articles by SCs ( Shen et al., 2018 ).
As such, we believe it is useful to build a classification system that assigns SCs to scholarly papers. Such a system could significantly impact scientific search and facilitate bibliometric evaluation. It can also help with Science of Science research ( Fortunato et al., 2018 ), an area of research that uses scholarly big data to study the choice of scientific problems, scientist career trajectories, research trends, research funding, and other research aspects. Also, many have noted that it is difficult to extract SCs using traditional topic models such as Latent Dirichlet Allocation (LDA), since it only extracts words and phrases present in documents ( Gerlach et al., 2018 ). An example is that a paper in computer science is rarely given its SC in the keyword list.
In this work, we pose the SC problem as one of multiclass classifications in which one SC is assigned to each paper. In a preliminary study, we investigated feature-based machine learning methods to classify research papers into six SCs ( Wu et al., 2018 ). Here, we extend that study and propose a system that classifies scholarly papers into 104 SCs using only abstracts. The core component is a neural network classifier trained on millions of labeled documents that are part of the WoS database. In comparison with our preliminary work, our data is more heterogeneous (more than 100 SCs as opposed to six), imbalanced, and complicated (data labels may overlap). We compare our system against several baselines applying various text representations, machine learning models, and/or neural network architectures.
SC classification is usually based on a universal schema for a specific domain or for all domains. Many schemas for scientific classification systems are publisher domain specific. For example, ACM has its own hierarchical classification system 1 , NLM has medical subject headings 2 , and MSC has a subject classification for mathematics 3 . The most comprehensive and systematic classification schemas seem to be from WoS 4 and the Library of Congress (LOC) 5 . The latter was created in 1897 and was driven by practical needs of the LOC rather than any epistemological considerations and is most likely out of date.
To the best of our knowledge, our work is the first example of using a neural network to classify scholarly papers into a comprehensive set of SCs. Other work focused on unsupervised methods and most were developed for specific category domains. In contrast, our classifier was trained on a large number of high quality abstracts from WoS and can be applied directly to abstracts without any citation information. We also develop a novel representation of scholarly paper abstracts using ranked tokens and their word embedding representations. This significantly reduces the scale of the classic Bag of Word (BoW) model. We also retrained FastText and GloVe word embedding models using WoS abstracts. The subject category classification was then applied to the CiteSeerX collection of documents. However, it could be applied to any similar collection.
2 Related Work
Text classification is a fundamental task in natural language processing. Many complicated tasks use it or include it as a necessary step, such as part-of-speech tagging, e.g., Ratnaparkhi (1996) , sentiment analysis, e.g., Vo and Zhang (2015) , and named entity recognition, e.g., Nadeau and Sekine (2007) . Classification can be performed at many levels: word, phrase, sentence, snippet (e.g., tweets, reviews), articles (e.g., news articles), and others. The number of classes usually ranges from a few to nearly 100. Methodologically, a classification model can be supervised, semi-supervised, and unsupervised. An exhaustive survey is beyond the scope of this paper. Here we briefly review short text classification and highlight work that classifies scientific articles.
Bag of words (BoWs) is one of the most commonly used representations for text classification, an example being keyphrase extraction ( Caragea et al., 2016 ; He et al., 2018 ). BoW represents text as a set of unordered word-level tokens, without considering syntactical and sequential information. For example, Nam et al. (2016) combined BoW with linguistic, grammatical, and structural features to classify sentences in biomedical paper abstracts. In Li et al. (2010) , the authors treated the text classification as a sequence tagging problem and proposed a Hidden Markov Model used for the task of classifying sentences into mutually exclusive categories, namely, background, objective, method, result, and conclusions. The task described in García et al. (2012) classifies abstracts in biomedical databases into 23 categories (OHSUMED dataset) or 26 categories (UVigoMED dataset). The author proposed a bag-of-concept representation based on Wikipedia and classify abstracts using the SVM model.
Recently, word embeddings (WE) have been used to build distributed dense vector representations for text. Embedded vectors can be used to measure semantic similarity between words ( Mikolov et al., 2013b ). WE has shown improvements in semantic parsing and similarity analysis, e.g., Prasad et al. (2018) . Other types of embeddings were later developed for character level embedding ( Zhang et al., 2015 ), phrase embedding ( Passos et al., 2014 ), and sentence embedding ( Cer et al., 2018 ). Several WE models have been trained and distributed; examples are word2vec ( Mikolov et al., 2013b ), GloVe ( Pennington et al., 2014 ), FastText ( Grave et al., 2017 ), Universal Sentence Encoder ( Cer et al., 2018 ), ELMo ( Peters et al., 2018 ), and BERT ( Devlin et al., 2019 ). Empirically, Long Short Term Memory [LSTM; Hochreiter and Schmidhuber (1997) ], Gated Recurrent Units [GRU; Cho et al. (2014) ], and convolutional neural networks [CNN; LeCun et al. (1989) ] have achieved improved performance compared to other supervised machine learning models based on shallow features ( Ren et al., 2016 ).
Classifying SCs of scientific documents is usually based on metadata, since full text is not available for most papers and processing a large amount of full text is computationally expensive. Most existing methods for SC classification are unsupervised. For example, the Smart Local Moving Algorithm identified topics in PubMed based on text similarity ( Boyack and Klavans, 2018 ) and citation information ( van Eck and Waltman, 2017 ). K-means was used to cluster articles based on semantic similarity ( Wang and Koopman, 2017 ). The memetic algorithm, a type of evolutionary computing ( Moscato and Cotta, 2003 ), was used to classify astrophysical papers into subdomains using their citation networks. A hybrid clustering method was proposed based on a combination of bibliographic coupling and textual similarities using the Louvain algorithm-a greedy method that extracted communities from large networks ( Glänzel and Thijs, 2017 ). Another study constructed a publication-based classification system of science using the WoS dataset ( Waltman and van Eck, 2012 ). The clustering algorithm, described as a modularity-based clustering, is conceptually similar to k -nearest neighbor ( k NN). It starts with a small set of seed labeled publications and grows by incrementally absorbing similar articles using co-citation and bibliographic coupling. Many methods mentioned above rely on citation relationships. Although such information can be manually obtained from large search engines such as Google Scholar, it is non-trivial to scale this for millions of papers.
Our model classifies papers based only on abstracts, which are often available. Our end-to-end system is trained on a large number of labeled data with no references to external knowledge bases. When compared with citation-based clustering methods, we believe it to be more scalable and portable.
3 Text Representations
For this work, we represent each abstract using a BoW model weighted by TF-IDF. However, instead of building a sparse vector for all tokens in the vocabulary, we choose word tokens with the highest TF-IDF values and encode them using WE models. We explore both pre-trained and re-trained WE models. We also explore their effect on classification performance based on token order. As evaluation baselines, we compare our best model with off-the-shelf text embedding models, such as the Unified Sentence Encoder [USE; Cer et al. (2018) ]. We show that our model which uses the traditional and relatively simple BoW representation is computationally less expensive and can be used to classify scholarly papers at scale, such as those in the CiteSeerX repository ( Giles et al., 1998 ; Wu et al., 2014 ).
3.1 Representing Abstracts
First, an abstract is tokenized with white spaces, punctuation, and stop words were removed. Then a list A of word types (unique words) w i is generated after lemmatization which uses the WordNet database ( Fellbaum, 2005 ) for the lemmas.
Next the list A f is sorted in descending order by TF-IDF giving A sorted . TF is the term frequency in an abstract and IDF is the inverse document frequency calculated using the number of abstracts containing a token in the entire WoS abstract corpus.
Because abstracts may have different numbers of words, we chose the top d elements from A sorted to represent the abstract. We then re-organize the elements according to their original order in the abstract forming a sequential input. If the number of words is less than d , we pad the feature list with zeros. The final list is a vector built by concatenating all word level vectors v → ′ k , k ∈ { 1 , ⋯ , d } into a D WE dimension vector. The final semantic feature vector A f is:
3.2 Word Embedding
To investigate how different word embeddings affect classification results, we apply several widely used models. An exhaustive experiment for all possible models is beyond the scope of this paper. We use some of the more popular ones as now discussed.
GloVe captures semantic correlations between words using global word-word co-occurrence, as opposed to local information used in word2vec ( Mikolov et al., 2013a ). It learns a word-word co-occurrence matrix and predicts co-occurrence ratios of given words in context ( Pennington et al., 2014 ). Glove is a context-independent model and outperformed other word embedding models such as word2vec in tasks such as word analogy, word similarity, and named entity recognition tasks.
FastText is another context-independent model which uses sub-word (e.g., character n -grams) information to represent words as vectors ( Bojanowski et al., 2017 ). It uses log-bilinear models that ignore the morphological forms by assigning distinct vectors for each word. If we consider a word w whose n -grams are denoted by g w , then the vector z g is assigned to each n -gram in g w . Each word is represented by the sum of the vector representations of its character n -grams. This representation is incorporated into a Skip Gram model ( Goldberg and Levy, 2014 ) which improves vector representation for morphologically rich languages.
SciBERT is a variant of BERT, a context-aware WE model that has improved the performance of many NLP tasks such as question answering and inference ( Devlin et al., 2019 ). The bidirectionally trained model seems to learn a deeper sense of language than single directional transformers. The transformer uses an attention mechanism that learns contextual relationships between words. SciBERT uses the same training method as BERT but is trained on research papers from Semantic Scholar. Since the abstracts from WoS articles mostly contain scientific information, we use SciBERT ( Beltagy et al., 2019 ) instead of BERT. Since it is computationally expensive to train BERT (4 days on 4–16 Cloud TPUs as reported by Google), we use the pre-trained SciBERT.
3.3 Retrained WE Models
Though pretrained WE models represent richer semantic information compared with traditional one-hot vector methods, when applied to text in scientific articles the classifier does not perform well. This is probably because the text corpus used to train these models are mostly from Wikipedia and Newswire. The majority of words and phrases included in the vocabulary extracted from these articles provides general descriptions of knowledge, which are significantly different from those used in scholarly articles which describe specific domain knowledge. Statistically, the overlap between the vocabulary of pretrained GloVe (six billion tokens) and WoS is only 37% ( Wu et al., 2018 ). Nearly all of the WE models can be retrained. Thus, we retrained GloVe and FastText using 6.38 million abstracts in WoS (by imposing a limit of 150k on each SC, see below for more details). There are 1.13 billion word tokens in total. GloVe generated 1 million unique vectors, and FastText generated 1.2 million unique vectors.
3.4 Universal Sentence Encoder
For baselines, we compared with Google’s Universal Sentence Encoder (USE) and the character-level convolutional network (CCNN). USE uses transfer learning to encode sentences into vectors. The architecture consists of a transformer-based sentence encoding ( Vaswani et al., 2017 ) and a deep averaging network (DAN) ( Iyyer et al., 2015 ). These two variants have trade-offs between accuracy and compute resources. We chose the transformer model because it performs better than the DAN model on various NLP tasks ( Cer et al., 2018 ). CCNN is a combination of character-level features trained on temporal (1D) convolutional networks [ConvNets; Zhang et al. (2015) ]. It treats input characters in text as a raw-signal which is then applied to ConvNets. Each character in text is encoded using a one-hot vector such that the maximum length l of a character sequence does not exceed a preset length l 0 .
4 Classifier Design
The architecture of our proposed classifier is shown in Figure 1 . An abstract representation previously discussed is passed to the neural network for encoding. Then the label of the abstract is determined by the output of the sigmoid function that aggregates all word encodings. Note that this architecture is not applicable for use by CCNN or USE. For comparison, we used these two architectures directly as described from their original publications.

FIGURE 1 . Subject category (SC) classification architecture.
LSTM is known for handling the vanishing gradient that occurs when training recurrent neural networks. A typical LSTM cell consists of three gates: input gate i t , output gate o t and forget gate f t . The input gate updates the cell state; the output gate decides the next hidden state, and the forget gate decides whether to store or erase particular information in the current state h t . We use tanh ( ⋅ ) as the activation function and the sigmoid function σ ( ⋅ ) to map the output values into a probability distribution. The current hidden state h t of LSTM cells can be implemented with the following equations:
At a given time step t , x t represents the input vector; c t represents cell state vector or memory cell; z t is a temporary result. W and U are weights for the input gate i , forget gate f , temporary result z , and output gate o .
GRU is similar to LSTM, except that it has only a reset gate r t and an update gate z t . The current hidden state h t at a given timestep t can be calculated with:
with the same defined variables. GRU is less computationally expensive than LSTM and achieves comparable or better performance for many tasks. For a given sequence, we train LSTM and GRU in two directions (BiLSTM and BiGRU) to predict the label for the current position using both historical and future data, which has been shown to outperform a single direction model for many tasks.
Attention Mechanism The attention mechanism is used to weight word tokens deferentially when aggregating them into a document level representations. In our system ( Figure 1 ), embeddings of words are concatenated into a vector with D WE dimensions. Using the attention mechanism, each word t contributes to the sentence vector, which is characterized by the factor α t such that
in which h t = [ h → t ; h ← t ] is the representation of each word after the BiLSTM or BiGRU layers, v t is the context vector that is randomly initialized and learned during the training process, W is the weight, and b is the bias. An abstract vector v is generated by aggregating word vectors using weights learned by the attention mechanism. We then calculate the weighted sum of h t using the attention weights by:
5 Experiments
Our training dataset is from the WoS database for the year 2015. The entire dataset contains approximately 45 million records of academic documents, most having titles and abstracts. They are labeled with 235 SCs at the journal level in three broad categories–Science, Social Science, and Art and Literature. A portion of the SCs have subcategories, such as “Physics, Condensed Matter,” “Physics, Nuclear,” and “Physics, Applied.” Here, we collapse these subcategories, which reduces the total number of SCs to 115. We do this because the minor classes decrease the performance of the model (due to the less availability of that data). Also, we need to have an “others” class to balance the data samples. We also exclude papers labeled with more than one category and papers that are labeled as “Multidisciplinary.” Abstracts with less than 10 words are excluded. The final number of singly labeled abstracts is approximately nine million, in 104 SCs. The sample sizes of these SCs range from 15 (Art) to 734k (Physics) with a median about 86k. We randomly select up to 150k abstracts per SC. This upper limit is based on our preliminary study ( Wu et al., 2018 ). The ratio between the training and testing corpus is 9:1.
The median of word types per abstract is approximately 80–90. As such, we choose the top d = 80 elements from A sorted to represent the abstract. If A sorted has less than d elements, we pad the feature list with zeros. The word vector dimensions of GloVe and FastText are set to 50 and 100, respectively. This falls into the reasonable value range (24–256) for WE dimensions ( Witt and Seifert, 2017 ). When training the BiLSM and BiGRU models, each layer contains 128 neurons. We investigate the dependency of classification performance on these hyper-parameters by varying the number of layers and neurons. We varied the number of word types per abstract d and set the dropout rate to 20% to mitigate overfitting or underfitting. Due to their relatively large size, we train the neural networks using mini-batch gradient descent with Adam for gradient optimization and one word cross entropy as the loss function. The learning rate was set to 10 − 3 .
6 Evaluation and Comparison
6.1 one-level classifier.
We first classify all abstracts in the testing set into 104 SCs using the retrained GloVe WE model with BiGRU. The model achieves a micro- F 1 score of 0.71. The first panel in Figure 2 shows the SCs that achieve the highest F 1 ’s; the second panel shows SCs that achieve relatively low F 1 ’s. The results indicate that the classifier performs poorer on SCs with relatively small sample sizes than SCs with relatively large sample sizes. The data imbalance is likely to contribute to the significantly different performances of SCs.

FIGURE 2 . Number of training documents (blue bars) and the corresponding F 1 values (red curves) for best performance (top) and worst performance (bottom) SC’s. Green line shows improved F 1 ’s produced by the second-level classifier.
6.2 Two-Level Classifier
To mitigate the data imbalance problems for the one-level classifier, we train a two-level classifier. The first level classifies abstracts into 81 SCs, including 80 major SCs and an “Others” category, which incorporates 24 minor SCs. “Others” contains the categories with training data < 10k abstracts. Abstracts that fall into the “Others” are further classified by a second level classifier, which is trained on abstracts belonging to the 24 minor SCs.
6.3 Baseline Methods
For comparison, we trained five supervised machine learning models as baselines. They are Random Forest (RF), Naïve Bayes (NB, Gaussian), Support Vector Machine (SVM, linear and Radial Basis Function kernels), and Logistic Regression (LR). Documents are represented in the same way as for the DANN except that no word embedding is performed. Because it takes an extremely long time to train these models using all data used for training DANN, and the implementation does not support batch processing, we downsize the training corpus to 150k in total and keep training samples in each SC in proportion to those used in DANN. The performance metrics are calculated based on the same testing corpus as the DANN model.
We used the CCNN architecture ( Zhang et al., 2015 ), which contains six convolutional layers each including 1,008 neurons followed by three fully connected layers. Each abstract is represented by a 1,014 dimensional vector. Our architecture for USE ( Cer et al., 2018 ) is an MLP with four layers, each of which contains 1,024 neurons. Each abstract is represented by a 512 dimensional vector.
6.4 Results
The performances of DANN in different settings and a comparison between the best DANN models and baseline models are illustrated in Figure 3 . The numerical values of performance metrics using the two-level classifier are tabulated in Supplementary Table S1 . Below are the observations from results.
(1) FastText + BiGRU + Attn and FastText+BiLSTM + Attn achieve the highest micro- F 1 of 0.76. Several models achieve similar results:GloVe + BiLSTM + Attn (micro- F 1 = 0.75), GloVe + BiGRU + Attn (micro- F 1 = 0.74), FastText + LSTM + Attn (micro- F 1 = 0.75), and FastText + GRU + Attn (micro- F 1 = 0.74). These results indicate that the attention mechanism significantly improves the classifier performance.
(2) Retraining FastText and GloVe significantly boosted the performance. In contrast, the best micro- F 1 achieved by USE is 0.64, which is likely resulted from its relatively low vocabulary overlap. Another reason could be is that the single vector of fixed length only encodes the overall semantics of the abstract. The occurrences of words are better indicators of sentences in specific domains.
(3) LSTM and GRU and their bidirectional counterparts exhibit very similar performance, which is consistent with a recent systematic survey ( Greff et al., 2017 ).
(4) For FastText + BiGRU + Attn, the F 1 measure varies from 0.50 to 0.95 with a median of 0.76. The distribution of F 1 values for 81 SCs is shown in Figure 4 . The F 1 achieved by the first-level classifier with 81 categories (micro- F 1 = 0.76) is improved compared with the classifier trained on 104 SCs (micro- F 1 = 0.70)
(5) The performance was not improved by increasing the GloVe vector dimension from 50 to 100 (not shown) under the setting of GloVe + BiGRU with 128 neurons on two layers which is consistent with earlier work ( Witt and Seifert, 2017 ).
(6) Word-level embedding models in general perform better than the character-level embedding models (i.e., CCNN). CCNN considers the text as a raw-signal, so the word vectors constructed are more appropriate when comparing morphological similarities. However, semantically similar words may not be morphologically similar, e.g., “Neural Networks” and “Deep Learning.”
(7) SciBERT’s performance is 3–5% below FastText and GloVe, indicating that re-trained WE models exhibit an advantage over pre-trained WE models. This is because SciBERT was trained on the PubMed corpus which mostly incorporates papers in biomedical and life sciences. Also, due to their large dimensions, the training time was greater than FastText under the same parameter settings.
(8) The best DANN model beats the best machine learning model (LR) by about 10%.

FIGURE 3 . Top: Micro- F 1 ’s of our DANN models that classify abstracts into 81 SCs. Variants of models within each group are color-coded. Bottom: Micro- F 1 ’s of our best DANN models that classify abstracts into 81 SCs, compared with baseline models.

FIGURE 4 . Distribution of F 1 ’s across 81 SC’s obtained by the first level classifier.
We also investigated the dependency of classification performance on key hyper-parameters. The settings of GLoVe + BiGRU with 128 neurons on two layers are considered as the “reference setting.” With the setting of GloVe + BiGRU, we increase the neuron number by factor of 10 (1,280 neurons on two layers) and obtained marginally improved performance by 1% compared with the same setting with 128 neurons. We also doubled the number of layers (128 neurons on four layers). Without attention, the model performs worse than the reference setting by 3%. With the attention mechanism, the micro- F 1 = 0.75 is marginally improved by 1% with respect to the reference setting. We also increase the default number of neurons of USE to 2048 neurons for four layers. The micro- F 1 improves marginally by 1%, reaching only 0.64. The results indicate that adding more neurons and layers seem to have little impact to the performance improvement.
The second-level classifier is trained using the same neural architecture as the first-level on the “Others” corpus. Figure 2 (Right ordinate legend) shows that F 1 ’s vary from 0.92 to 0.97 with a median of 0.96. The results are significantly improved by classifying minor classes separately from major classes.
7 Discussion
7.1 sampling strategies.
The data imbalance problem is ubiquitous in both multi-class and multi-label classification problems ( Charte et al., 2015 ). The imbalance ratio (IR), defined as the ratio of the number of instances in the majority class to the number of samples in the minority class ( García et al., 2012 ), has been commonly used to characterize the level of imbalance. Compared with the imbalance datasets in Table 1 of ( Charte et al., 2015 ), our data has a significantly high level of imbalance. In particular, the highest IR is about 49,000 ( # Physics/#Art). One commonly used way to mitigate this problem is data resampling. This method is based on rebalancing SC distributions by either deleting instances of major SCs (undersampling) or supplementing artificially generated instances of the minor SCs (oversampling). We can always undersample major SCs, but this means we have to reduce sample sizes of all SCs down to about 15 (Art; Section 5), which is too small for training robust neural network models. The oversampling strategies such as SMOTE ( Chawla et al., 2002 ) works for problems involving continuous numerical quantities, e.g., SalahEldeen and Nelson (2015) . In our case, the synthesized vectors of “abstracts” by SMOTE will not map to any actual words because word representations are very sparsely distributed in the large WE space. Even if we oversample minor SCs using semantically dummy vectors, generating all samples will take a large amount of time given the high dimensionality of abstract vectors and high IR. Therefore, we only use real data.

TABLE 1 . Results of the top 10 SCs of classifying one million research papers in CiteSeerX, using our best model.
7.2 Category Overlapping
We discuss the potential impact on classification results contributed by categories overlapping in the training data. Our initial classification schema contains 104 SCs, but they are not all mutually exclusive. Instead, the vocabularies of some categories overlap with the others. For example, papers exclusively labeled as “Materials Science” and “Metallurgy” exhibit significant overlap in their tokens. In the WE vector space, the semantic vectors labeled with either category are overlapped making it hard to differentiate them. Figure 5 shows the confusion matrices of the closely related categories such as “Geology,” “Mineralogy,” and “Geochemistry Geophysics.” Figure 6 is the t -SNE plot of abstracts of closely related SCs. To make the plot less crowded, we randomly select 250 abstracts from each SC as shown in Figure 5 . Data points representing “Geology,” “Mineralogy,” and “Geochemistry Geophysics” tend to spread or are overlapped in such a way that are hard to be visually distinguished.

FIGURE 5 . Normalized Confusion Matrix for closely related classes in which a large fraction of “Geology” and “Mineralogy” papers are classified into “GeoChemistry GeoPhysics” (A) , and a large fraction of Zoology papers are classified into “biology” or “ecology” (B) , a large fraction of “TeleCommunications,” “Mechanics” and “EnergyFuels” papers are classified into “Engineering” (C) .

FIGURE 6 . t -SNE plot of closely related SCs.
One way to mitigate this problem is to merge overlapped categories. However, special care should be taken on whether these overlapped SCs are truly strongly related and should be evaluated by domain experts. For example, “Zoology,” “PlantSciences,” and “Ecology” can be merged into a single SC called “Biology” (Gaff, 2019; private communication). “Geology,” “Mineralogy,” and “GeoChemistry GeoPhysics” can be merged into a single SC called “Geology.” However, “Materials Science” and “Metallurgy” may not be merged (Liu, 2019; private communication) to a single SC. By doing the aforementioned merges, the number of SCs is reduced to 74. As a preliminary study, we classified the merged dataset using our best model (retrained FastText + BiGRU + Attn) and achieved an improvement with an overall micro- F 1 score of 0.78. The classification performance of “Geology” after merging has improved from 0.83 to 0.88.
7.3 Limitations
Compared with existing work, our models are trained on a relatively comprehensive, large-scale, and clean dataset from WoS. However, the basic classification of WoS is at the journal level and not at the article level. We are also aware that the classification schema of WoS may change over time. For example, in 2018, WoS introduced three new SCs such as Quantum Science and Technology, reflecting emerging research trends and technologies ( Boletta, 2019 ). To mitigate this effect, we excluded papers with multiple SCs and assume that the SCs of papers studied are stationary and journal level classifications represent the paper level SCs.
Another limitation is the document representation. The BoW model ignores the sequential information. Although we experimented on the cases in which we keep word tokens in the same order as they appear in the original documents, the exclusion of stop words breaks the original sequence, which is the input of the recurrent encoder. We will address this limitation in future research by encoding the whole sentences, e.g., Yang et al. (2016) .
8 Application to CITESEERX
CiteSeerX is a digital library search engine that was the first to use automatic citation indexing ( Giles et al., 1998 ). It is an open source search engine that provides metadata and full-text access for more than 10 million scholarly documents and continues to add new documents ( Wu et al., 2019 ). In the past decade, it has incorporated scholarly documents in diverse SCs, but the distribution of their subject categories is unknown. Using the best neural network model in this work (FreeText + BiGRU + Attn), we classified one million papers randomly selected from CiteSeerX into 104 SCs ( Table 1 ). The fraction of Computer Science papers (19.2%) is significantly higher than the results in Wu et al. (2018) , which was 7.58%. The F 1 for Computer Science was about 0.94 for Computer Science which is higher than this work (about 0.80). Therefore, the fraction may be overestimated here. However Wu et al. (2018) , had only six classes and this model classifies abstracts into 104 SCs, so although this compromises the accuracy (by around 7% on average), our work can still be used as a starting point for a systematic SC classification. The classifier classifies one million abstracts in 1,253 s implying that will be scalable on multi-millions of papers.
9 Conclusion
We investigated the problem of systematically classifying a large collection of scholarly papers into 104 SC’s using neural network methods based only on abstracts. Our methods appear to scale better than existing clustering-based methods relying on citation networks. For neural network methods, our retrained FastText or GloVe combined with BiGRU or BiLSTM with the attention mechanism gives the best results. Retraining WE models and using an attention mechanism play important roles in improving the classifier performance. A two-level classifier effectively improves our performance when dealing with training data that has extremely imbalanced categories. The median F 1 ’s under the best settings are 0.75–0.76.
One bottleneck of our classifier is the overlapping categories. Merging closely related SCs is a promising solution, but should be under the guidance of domain experts. The TF-IDF representation only considers unigrams. Future work could consider n -grams or concepts ( n ≥ 2 ) and transfer learning to adopt word/sentence embedding models trained on non-scholarly corpora ( Arora et al., 2017 ; Conneau et al., 2017 ). One could investigate models that also take into account stop-words, e.g., Yang et al. (2016) . One could also explore alternative optimizers of neural networks besides Adam, such as the Stochastic Gradient Descent (SGD). Our work falls into the multiclass classification, which classifies research papers into flat SCs. In the future, we will investigate hierarchical multilabel classification that assigns multiple SCs at multiple levels to papers.
Data Availability Statement
The Web of Science (WoS) dataset used for this study is proprietary and can be purchased from Clarivate 6 . The implementation software is open accessible from GitHub 7 . The testing datasets and CiteSeerX classification results are available on figshare 8 .
Author Contributions
BK designed the study and implemented the models. He is responsible for analyzing the results and writing the paper. SR is responsible for model selection, experiment design, and reviewing methods and results. JW was responsible for data management, selection, and curation. He reviewed related works and contributed to the introduction. CG is responsible for project management, editing, and supervision.
This research is partially funded by the National Science Foundation (Grant No: 1823288).
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
We gratefully acknowledge partial support from the National Science Foundation. We also acknowledge Adam T. McMillen for technical support, and Holly Gaff, Old Dominion University and Shimin Liu, Pennsylvania State University as domain experts respectively in biology and the earth and mineral sciences.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/frma.2020.600382/full#supplementary-material .
1 https://www.acm.org/about-acm/class
2 https://www.ncbi.nlm.nih.gov/mesh
3 http://msc2010.org/mediawiki/index.php?title=Main_Page
4 https://images.webofknowledge.com/images/help/WOS/hp_subject_category_terms_tasca.html
5 https://www.loc.gov/aba/cataloging/classification/
6 https://clarivate.libguides.com/rawdata
7 https://github.com/SeerLabs/sbdsubjectclassifier
8 https://doi.org/10.6084/m9.figshare.12887966.v2
Arora, S., Liang, Y., and Ma, T. (2017). “A simple but tough-to-beat baseline for sentence embeddings,” in ICLR, Toulon, France, April 24-26, 2017 .
Google Scholar
Barnes, B., Bloor, D., and Henry, J. (1996). Scientific knowledge: a sociological analysis . Chicago IL: University of Chicago Press .
Beltagy, I., Cohan, A., and Lo, K. (2019). Scibert: pretrained contextualized embeddings for scientific text. arXiv:1903.10676.
CrossRef Full Text | Google Scholar
Bojanowski, P., Grave, E., Joulin, A., and Mikolov, T. (2017). Enriching word vectors with subword information. Trans. Assoc. Comput. 5, 135–146. doi:10.1162/tacl_a_00051
Boletta, M. (2019). New web of science categories reflect ever-evolving research. Available at: https://clarivate.com/webofsciencegroup/article/new-web-of-science-categories-reflect-ever-evolving-research/ (Accessed January 24, 2019).
Boyack, K. W., and Klavans, R. (2018). Accurately identifying topics using text: mapping pubmed . Leiden, Netherlands: Centre for Science and Technology Studies (CWTS) , 107–115.
Caragea, C., Wu, J., Gollapalli, S. D., and Giles, C. L. (2016). “Document type classification in online digital libraries,” in Proceedings of the 13th AAAI conference, Phoenix, AZ, USA, February 12-17, 2016 .
Cer, D., Yang, Y., Kong, S., Hua, N., Limtiaco, N., John, R. S., et al. (2018). “Universal sentence encoder for English,” in Proceedings of EMNLP conference, Brussels, Belgium, October 31-November 4, 2018 .
Charte, F., Rivera, A. J., del Jesús, M. J., and Herrera, F. (2015). Addressing imbalance in multilabel classification: measures and random resampling algorithms. Neurocomputing 163, 3–16. doi:10.1016/j.neucom.2014.08.091
Chawla, N. V., Bowyer, K. W., Hall, L. O., and Kegelmeyer, W. P. (2002). Smote: synthetic minority over-sampling technique. Jair 16, 321–357. doi:10.1613/jair.953
Cho, K., Van Merrienboer, B., Gülçehre, C., Bahdanau, D., Bougares, F., Schwenk, H., et al. (2014). “Learning phrase representations using RNN encoder-decoder for statistical machine translation,” in Proceedings of the 2014 conference on empirical methods in natural language processing, EMNLP 2014, Doha Qatar, October 25-29, 2014 , 1724–1734.
Collins, H. M. (1992). “Epistemological chicken hm collins and steven yearley,” in Science as practice and culture . Editor A. Pickering ( Chicago, IL: University of Chicago Press ), 301.
Conneau, A., Kiela, D., Schwenk, H., Barrault, L., and Bordes, A. (2017). “Supervised learning of universal sentence representations from natural language inference data,” in Proceedings of the EMNLP conference, Copenhagen, Denmark, September 9-11, 2017 .
Devlin, J., Chang, M., Lee, K., and Toutanova, K. (2019). “BERT: pre-training of deep bidirectional transformers for language understanding,” in NAACL-HLT, Minneapolis, MN, USA, June 2-7, 2019 .
Fellbaum, C. (2005). “Wordnet and wordnets,” in Encyclopedia of language and linguistics . Editor A. Barber ( Elsevier ), 2–665.
Fortunato, S., Bergstrom, C. T., Börner, K., Evans, J. A., Helbing, D., Milojević, S., et al. (2018). Science of science. Science 359, eaao0185. doi:10.1126/science.aao0185
García, V., Sánchez, J. S., and Mollineda, R. A. (2012). On the effectiveness of preprocessing methods when dealing with different levels of class imbalance. Knowl. Base Syst. 25, 13–21. doi:10.1016/j.knosys.2011.06.013
Gerlach, M., Peixoto, T. P., and Altmann, E. G. (2018). A network approach to topic models. Sci. Adv. 4, eaaq1360. doi:10.1126/sciadv.aaq1360
PubMed Abstract | CrossRef Full Text | Google Scholar
Giles, C. L., Bollacker, K. D., and Lawrence, S. (1998). “CiteSeer: An automatic citation indexing system,” in Proceedings of the 3rd ACM international conference on digital libraries , June 23–26, 1998 , Pittsburgh, PA, United States , 89–98.
Glänzel, W., and Thijs, B. (2017). Using hybrid methods and ‘core documents’ for the representation of clusters and topics: the astronomy dataset. Scientometrics 111, 1071–1087. doi:10.1007/s11192-017-2301-6
Goldberg, Y., and Levy, O. (2014). Word2vec explained: deriving mikolov et al.’s negative-sampling word-embedding method. preprint arXiv:1402.3722.
Grave, E., Mikolov, T., Joulin, A., and Bojanowski, P. (2017). “Bag of tricks for efficient text classification,” in Proceedings of the 15th EACL, Valencia, Span, April 3-7, 2017 .
Greff, K., Srivastava, R. K., Koutník, J., Steunebrink, B. R., and Schmidhuber, J. (2017). LSTM: a search space odyssey. IEEE Trans. Neural Networks Learn. Syst. 28, 2222–2232. doi:10.1109/TNNLS.2016.2582924
He, G., Fang, J., Cui, H., Wu, C., and Lu, W. (2018). “Keyphrase extraction based on prior knowledge,” in Proceedings of the 18th ACM/IEEE on joint conference on digital libraries, JCDL, Fort Worth, TX, USA, June 3-7, 2018 .
Hochreiter, S., and Schmidhuber, J. (1997). Long short-term memory. Neural Comput. 9, 1735–1780.
Iyyer, M., Manjunatha, V., Boyd-Graber, J., and Daumé, H. (2015). “Deep unordered composition rivals syntactic methods for text classification,” in Proceedings ACL, Beijing, China, July 26-31, 2015 .
Khabsa, M., and Giles, C. L. (2014). The number of scholarly documents on the public web. PloS One 9, e93949. doi:10.1371/journal.pone.0093949
Larsen, P., and von Ins, M. (2010). The rate of growth in scientific publication and the decline in coverage provided by science citation index. Scientometrics 84, 575–603. doi:10.1007/s11192-010-0202-z
LeCun, Y., Boser, B. E., Denker, J. S., Henderson, D., Howard, R. E., Hubbard, W. E., et al. (1989). “Handwritten digit recognition with a back-propagation network,” in Advances in neural information processing systems [NIPS conference], Denver, Colorado, USA, November 27-30, 1989.
Li, Y., Lipsky Gorman, S., and Elhadad, N. (2010). “Section classification in clinical notes using supervised hidden markov model,” in Proceedings of the 1st ACM international health informatics symposium, Arlington, VA, USA, November 11-12, 2010 (New York, NY : Association for Computing Machinery ), 744–750.
Matsuda, K., and Fukushima, T. (1999). Task-oriented world wide web retrieval by document type classification. In Proceedings of CIKM, Kansas City, Missouri, USA, November 2-6, 1999 .
Mikolov, T., Chen, K., Corrado, G., and Dean, J. (2013a). Efficient estimation of word representations in vector space. arXiv:1301.3781.
Mikolov, T., Yih, W., and Zweig, G. (2013b). “Linguistic regularities in continuous space word representations,” in Proceedings of NAACL-HLT, Atlanta, GA, USA, June 9-14, 2013 .
Moscato, P., and Cotta, C. (2003). A gentle introduction to memetic algorithms . Boston, MA: Springer US , 105–144.
Nadeau, D., and Sekine, S. (2007). A survey of named entity recognition and classification. Lingvisticæ Investigationes 30, 3–26. doi:10.1075/li.30.1.03nad
Nam, S., Jeong, S., Kim, S.-K., Kim, H.-G., Ngo, V., and Zong, N. (2016). Structuralizing biomedical abstracts with discriminative linguistic features. Comput. Biol. Med. 79, 276–285. doi:10.1016/j.compbiomed.2016.10.026
Passos, A., Kumar, V., and McCallum, A. (2014). “Lexicon infused phrase embeddings for named entity resolution,” in Proceedings of CoNLL, Baltimore, MD, USA, June, 26-27, 2014 .
Pennington, J., Socher, R., and Manning, C. D. (2014). “Glove: global vectors for word representation,” in Proceedings of the EMNLP conference, Doha, Qatar, October 25-29, 2014 .
Peters, M. E., Neumann, M., Iyyer, M., Gardner, M., Clark, C., Lee, K., et al. (2018). “Deep contextualized word representations,” in NAACL-HLT, New Orleans, LA,, USA, June 1-6, 2018 .
Prasad, A., Kaur, M., and Kan, M.-Y. (2018). Neural ParsCit: a deep learning-based reference string parser. Int. J. Digit. Libr. 19, 323–337. doi:10.1007/2Fs00799-018-0242-1
Ratnaparkhi, A. (1996). “A maximum entropy model for part-of-speech tagging,” in The proceedings of the EMNLP conference, Philadelphia, PA, USA, May 17-18, 1996 .
Ren, Y., Zhang, Y., Zhang, M., and Ji, D. (2016). “Improving twitter sentiment classification using topic-enriched multi-prototype word embeddings,” in AAAI, Phoenix, AZ, USA, February 12-17, 2016 .
SalahEldeen, H. M., and Nelson, M. L. (2015). “Predicting temporal intention in resource sharing,” in Proceedings of the 15th JCDL conference, Knoxville, TN, USA, June 21-25, 2015 .
Shen, Z., Ma, H., and Wang, K. (2018). “A web-scale system for scientific knowledge exploration,” in Proceedings of ACL 2018, system demonstrations (Melbourne, Australia: Association for Computational Linguistics ), 87–92.
van Eck, N. J., and Waltman, L. (2017). Citation-based clustering of publications using citnetexplorer and vosviewer. Scientometrics 111, 1053–1070. doi:10.1007/s11192-017-2300-7
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., et al. (2017). “Attention is all you need,” in NIPS, Long Beach, CA, USA, December 4-9, 2017 .
Vo, D.-T., and Zhang, Y. (2015). “Target-dependent twitter sentiment classification with rich automatic features,” In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, IJCAI 2015, Buenos Aires, Argentina, July 25-31, 2015, Editors Q. Yang and M. J. Wooldridge (AAAI Press), 1347–1353.
Waltman, L., and van Eck, N. J. (2012). A new methodology for constructing a publication-level classification system of science. JASIST 63, 2378–2392. doi:10.1002/asi.22748
Wang, S., and Koopman, R. (2017). Clustering articles based on semantic similarity. Scientometrics 111, 1017–1031. doi:10.1007/s11192-017-2298-x
Witt, N., and Seifert, C. (2017). “Understanding the influence of hyperparameters on text embeddings for text classification tasks,” in TPDL conference, Thessaloniki, Greece, September 18-21, 2017 .
Wu, J., Kandimalla, B., Rohatgi, S., Sefid, A., Mao, J., and Giles, C. L. (2018). “Citeseerx-2018: a cleansed multidisciplinary scholarly big dataset,” in IEEE big data, Seattle, WA, USA, December 10-13, 2018 .
Wu, J., Kim, K., and Giles, C. L. (2019). “CiteSeerX: 20 years of service to scholarly big data,” in Proceedings of the AIDR conference, Pittsburgh, PA, USA, May 13-15, 2019 .
Wu, J., Williams, K., Chen, H., Khabsa, M., Caragea, C., Ororbia, A., et al. (2014). “CiteSeerX: AI in a digital library search engine,” in Proceedings of the twenty-eighth AAAI conference on artificial intelligence .
Yang, Z., Yang, D., Dyer, C., He, X., Smola, A. J., and Hovy, E. H. (2016). “Hierarchical attention networks for document classification,” in The NAACL-HLT conference .
Zhang, X., Zhao, J., and LeCun, Y. (2015). “Character-level convolutional networks for text classification,” in Proceedings of the NIPS conference, Montreal, Canada, December 7-12, 2015 .
Zitt, M., Lelu, A., Cadot, M., and Cabanac, G. (2019). “Bibliometric delineation of scientific fields,” in Handbook of science and technology indicators . Editors W. Glänzel, H. F. Moed, U. Schmoch, and M. Thelwall ( Springer International Publishing ), 25–68.
Keywords: text classification, text mining, scientific papers, digital library, neural networks, citeseerx, subject category classification
Citation: Kandimalla B, Rohatgi S, Wu J and Giles CL (2021) Large Scale Subject Category Classification of Scholarly Papers With Deep Attentive Neural Networks. Front. Res. Metr. Anal. 5:600382. doi: 10.3389/frma.2020.600382
Received: 29 August 2020; Accepted: 24 December 2020; Published: 10 February 2021.
Reviewed by:
Copyright © 2021 Kandimalla, Rohatgi, Wu and Giles.. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Bharath Kandimalla, [email protected] ; Jian Wu, [email protected]
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research paper classification systems based on TF-IDF and LDA schemes
- December 2019
- Human-centric Computing and Information Sciences 9(1)
- This person is not on ResearchGate, or hasn't claimed this research yet.
Abstract and Figures

Discover the world's research
- 25+ million members
- 160+ million publication pages
- 2.3+ billion citations
- Dionisia Bhisetya Rarasati
- Huanhuan Cheng
- Roberto Garc

- Flordeliza P. Poncio
- Muhammad Syiarul Amrullah

- Carmen Manteca
- Ángel Yedra
- Abraham Casas
- Jhansi Yellapu
- Kancharla Sunil Kumar Reddy
- Gandham Vijaya Lakshmi
- Tella Subash Kishore
- Kiet Nguyen Tuan
- Thin Dang Van

- Ruijie Wang
- Abraham Bernstein
- Alfatha Fitrah Insan
- Detty Purnamasari

- CMC-COMPUT MATER CON

- V. Subramaniam

- Lukáš Havrlant
- NEUROCOMPUTING
- G.V. Oliveira

- Ricardo J. G. B. Campello

- Recruit researchers
- Join for free
- Login Email Tip: Most researchers use their institutional email address as their ResearchGate login Password Forgot password? Keep me logged in Log in or Continue with Google Welcome back! Please log in. Email · Hint Tip: Most researchers use their institutional email address as their ResearchGate login Password Forgot password? Keep me logged in Log in or Continue with Google No account? Sign up
Help | Advanced Search
Computer Science > Computer Vision and Pattern Recognition
Title: image classification with classic and deep learning techniques.
Abstract: To classify images based on their content is one of the most studied topics in the field of computer vision. Nowadays, this problem can be addressed using modern techniques such as Convolutional Neural Networks (CNN), but over the years different classical methods have been developed. In this report, we implement an image classifier using both classic computer vision and deep learning techniques. Specifically, we study the performance of a Bag of Visual Words classifier using Support Vector Machines, a Multilayer Perceptron, an existing architecture named InceptionV3 and our own CNN, TinyNet, designed from scratch. We evaluate each of the cases in terms of accuracy and loss, and we obtain results that vary between 0.6 and 0.96 depending on the model and configuration used.
| Subjects: | Computer Vision and Pattern Recognition (cs.CV) |
| Cite as: | [cs.CV] |
| (or [cs.CV] for this version) | |
| Focus to learn more arXiv-issued DOI via DataCite |
Submission history
Access paper:.
- Other Formats
References & Citations
- Google Scholar
- Semantic Scholar
DBLP - CS Bibliography
Bibtex formatted citation.
Bibliographic and Citation Tools
Code, data and media associated with this article, recommenders and search tools.
- Institution
arXivLabs: experimental projects with community collaborators
arXivLabs is a framework that allows collaborators to develop and share new arXiv features directly on our website.
Both individuals and organizations that work with arXivLabs have embraced and accepted our values of openness, community, excellence, and user data privacy. arXiv is committed to these values and only works with partners that adhere to them.
Have an idea for a project that will add value for arXiv's community? Learn more about arXivLabs .
Reference management. Clean and simple.
Types of research papers

Analytical research paper
Argumentative or persuasive paper, definition paper, compare and contrast paper, cause and effect paper, interpretative paper, experimental research paper, survey research paper, frequently asked questions about the different types of research papers, related articles.
There are multiple different types of research papers. It is important to know which type of research paper is required for your assignment, as each type of research paper requires different preparation. Below is a list of the most common types of research papers.
➡️ Read more: What is a research paper?
In an analytical research paper you:
- pose a question
- collect relevant data from other researchers
- analyze their different viewpoints
You focus on the findings and conclusions of other researchers and then make a personal conclusion about the topic. It is important to stay neutral and not show your own negative or positive position on the matter.
The argumentative paper presents two sides of a controversial issue in one paper. It is aimed at getting the reader on the side of your point of view.
You should include and cite findings and arguments of different researchers on both sides of the issue, but then favor one side over the other and try to persuade the reader of your side. Your arguments should not be too emotional though, they still need to be supported with logical facts and statistical data.
Tip: Avoid expressing too much emotion in a persuasive paper.
The definition paper solely describes facts or objective arguments without using any personal emotion or opinion of the author. Its only purpose is to provide information. You should include facts from a variety of sources, but leave those facts unanalyzed.
Compare and contrast papers are used to analyze the difference between two:
Make sure to sufficiently describe both sides in the paper, and then move on to comparing and contrasting both thesis and supporting one.
Cause and effect papers are usually the first types of research papers that high school and college students write. They trace probable or expected results from a specific action and answer the main questions "Why?" and "What?", which reflect effects and causes.
In business and education fields, cause and effect papers will help trace a range of results that could arise from a particular action or situation.
An interpretative paper requires you to use knowledge that you have gained from a particular case study, for example a legal situation in law studies. You need to write the paper based on an established theoretical framework and use valid supporting data to back up your statement and conclusion.
This type of research paper basically describes a particular experiment in detail. It is common in fields like:
Experiments are aimed to explain a certain outcome or phenomenon with certain actions. You need to describe your experiment with supporting data and then analyze it sufficiently.
This research paper demands the conduction of a survey that includes asking questions to respondents. The conductor of the survey then collects all the information from the survey and analyzes it to present it in the research paper.
➡️ Ready to start your research paper? Take a look at our guide on how to start a research paper .
In an analytical research paper, you pose a question and then collect relevant data from other researchers to analyze their different viewpoints. You focus on the findings and conclusions of other researchers and then make a personal conclusion about the topic.
The definition paper solely describes facts or objective arguments without using any personal emotion or opinion of the author. Its only purpose is to provide information.
Cause and effect papers are usually the first types of research papers that high school and college students are confronted with. The answer questions like "Why?" and "What?", which reflect effects and causes. In business and education fields, cause and effect papers will help trace a range of results that could arise from a particular action or situation.
This type of research paper describes a particular experiment in detail. It is common in fields like biology, chemistry or physics. Experiments are aimed to explain a certain outcome or phenomenon with certain actions.

IEEE Account
- Change Username/Password
- Update Address
Purchase Details
- Payment Options
- Order History
- View Purchased Documents
Profile Information
- Communications Preferences
- Profession and Education
- Technical Interests
- US & Canada: +1 800 678 4333
- Worldwide: +1 732 981 0060
- Contact & Support
- About IEEE Xplore
- Accessibility
- Terms of Use
- Nondiscrimination Policy
- Privacy & Opting Out of Cookies
A not-for-profit organization, IEEE is the world's largest technical professional organization dedicated to advancing technology for the benefit of humanity. © Copyright 2024 IEEE - All rights reserved. Use of this web site signifies your agreement to the terms and conditions.
- Resources
- Prospective Students
- Current Students
- Faculty & Staff
- Alumni & Friends
- News & Media
Entry Points to Your Own Work
Adapted from Wendy Belcher’s Writing Your Journal Article in 12 Weeks (2019)
What is your entry point?
Your entry point is how your argument enters the debate occurring in the previous research on the topic.
Types of entry points
- finding the previous research inadequate or nonexistent and filling the gap
- finding it sound and supporting it or extending it
- finding it unsound and correcting it
Entry Point Type 1: Addressing a Gap in Previous Research
Identifying a gap (or gaps) in the related scholarly literature and setting out to fill it is one of the most common entry points in academic writing. In the humanities, gap claims often relate to sources, with scholars claiming that there is a gap in attention given to certain authors or texts, or to particular types of authors, texts, or textual themes. In the professions, social sciences, or health sciences, gap claims often relate to problems-many scholars claim that there is a gap in attention given to certain equality challenges in politics, economics, society, health, and so on. Filling gaps is a strong claim for significance. However, the success of this claim rests on having a good grasp of the research.
Here is an example from a published article of an author announcing a gap entry point into previous research.
“Listening is surprisingly and problematically overlooked in the large body of literature on organization-public communication including government, political, corporate, and marketing communication. Based on critical analysis of relevant literature and primary research among 36 organizations in three countries, this analysis identifies a ‘crisis listening' in organization-public communication and proposes strategies to address gaps in theory and practice including attention to the work of listening and the creation of an architecture of listening in organizations, which can offer significant stakeholder. societal. and organizational benefits.” (from Macnamara 2016, 133)
Entry Point Type 2: Supporting Previous Research
Approving of and using other scholars’ theories to analyze new subjects is another common
scholarly entry point. Thus, naming authors or articles you find useful is part of positioning
your article vis-a-vis the previous research. This can be as simple as identifying the school, camp, movement, or tradition your research participates in. In all disciplines, supporting or extending previous research often relates to theorists, with scholars claiming that a particular theorist's work, idea(s), or definition is especially helpful in understanding the subject at hand (or that a group of theorists or a school of theory is helpful). Bridging two discussions in the related literature is another way of supporting or extending research.
Here are examples from published articles of authors announcing supportive entry points into previous research.
Extending the related literature. “Although some evidence indicates that personality characteristics, such as extroversion and proactivity, are related to career success, scholars have called for research to understand how such effects occur…. Consistent with prior research…, we theorize that personality traits, specifically extroversion and proactivity, influence mentoring received, which in turn influences career success.” (from Turban et al. 2016, 21)
Bridging two bodies of related literature. "We bring together two long-standing rural sociological traditions to address debates framed at the national level and for Appalachian communities facing the throes of transition from the coal industry. From rural sociology’s
‘poverty and place’ tradition and from natural resources sociology, we examine the relationship between coal employment and communities' economic well-being as indicated by poverty, household income, and unemployment. Our findings extend the poverty and place literature and the natural resources literature and underscore why a just transition away from coal should focus on moving communities toward sectors offering better future livelihoods.” (from Lobao et al. 2016, 343)
Bridging a debate in the related literature. “Recent statistics on African American readers outline distinct trends that are difficult to reconcile with each other: …. trailing in proficiency yet thriving in general book reading…. A roiling debate…. focuses on whether readers' preoccupation with urban fiction is symbolic of black literacy's triumph or downfall in the twenty-first century .... I examine the motivating factors…. of these positions in the debate. First I discuss democratizers who ... advocate ... bringing urban fiction into the classroom. I then consider cultural gatekeepers who bemoan mass book reading as a kind of rampant false consciousness …. I turn, finally, to a position between them that values urban fiction in those spaces and situations that are friendly to its consumption…. I characterize the position as merely reading…. adjustable to its surroundings and supple in its execution, it is compatible with serious reading and other literate behaviors.” (from Nishikawa 2015, 697, 698, 702)
Entry Point Type 3: Correcting Previous Research
The most common entry point into the previous research is stating that previous scholarly approaches to a subject are erroneous, and that your article will overturn these misconceptions. Such corrections of the related literature take many forms, from weighing in on a debate (whether choosing one side or saying both are wrong) ; questioning a policy, practice, or interpretation; addressing a contradiction; or offering a solution.
Here is an example of criticizing a theorist .
“Giorgio Agamben's formulations of ‘the state of exception’ and ‘bare life’ have become touchstones for analyses of sovereign violence and biopolitics, yet it seems to have escaped note that Agamben’s use of these terms is marked by a peculiar oversight. While Agamben's Eurocentrism has been redressed by scholars such as… , even his most careful readers do not comment on Agamben's treatment of a word that he takes from Primo Levi as the key to understanding politics and ethics after World War II…. (from Jarvis 2014, 707, 710)
- Search Menu
- Sign in through your institution
- Advance Articles
- Author Guidelines
- Open Access Options
- Self-Archiving Policy
- About International Journal of Low-Carbon Technologies
- Editorial Board
- Advertising and Corporate Services
- Journals Career Network
- Dispatch Dates
- Journals on Oxford Academic
- Books on Oxford Academic

Article Contents
1 introduction, 2 classification of solar still, 3 why solar distillation is important, 4 external and internal modifications in still to enhance the yield rate, 5 the importance of pyramid solar still, 6 challenges and conclusions, 7 future scope, acknowledgements.
- < Previous
Revolutionizing solar water distillation: maximizing efficiency with pyramid solar stills enhanced by fins, evacuated tubes, nanomaterial, and phase change materials—a comprehensive review
- Article contents
- Figures & tables
- Supplementary Data
Vijay Kishorbhai Mehta, Hitesh Panchal, Bharat Singh, Laveet Kumar, Revolutionizing solar water distillation: maximizing efficiency with pyramid solar stills enhanced by fins, evacuated tubes, nanomaterial, and phase change materials—a comprehensive review, International Journal of Low-Carbon Technologies , Volume 19, 2024, Pages 1996–2009, https://doi.org/10.1093/ijlct/ctae116
- Permissions Icon Permissions
The availability of water and energy is crucial for human survival, yet rising industrialization and population growth have escalated demand, particularly in developing economies. Despite efforts to address water scarcity, contamination persists, leading to widespread diseases. Conventional purification methods like reverse osmosis are effective but expensive and energy-intensive while boiling exacerbates air pollution. In this context, solar still systems present a promising solution, harnessing abundant sunlight to distill seawater into drinkable water. By integrating phase change material (PCM) and sensible heat storage, these systems can enhance efficiency and reduce energy consumption. This article explores the optimization of solar still systems through the selection of suitable PCM and sensible heat storage materials. The primary objectives are to improve distillation efficiency and heat recovery, making the process more eco-friendly and cost-effective. By addressing water scarcity and energy consumption simultaneously, these optimized systems offer a sustainable approach to water production, particularly in regions with ample sunlight. Through a comprehensive review, this research aims to advance the understanding of solar still technology and facilitate its widespread adoption, ultimately contributing to global efforts toward water security and environmental sustainability.
Water is indispensable for human survival and essential for various daily activities such as bathing, cooking, and drinking, with individuals typically utilizing 20–50 liters of water per day [ 1 ]. However, a pressing global concern looms over water scarcity, prompting researchers to explore alternative solutions [ 2 ]. Despite the abundance of seawater, its high total dissolved solid content, ranging from 35,000 to 45,000 parts per million (ppm), poses a significant challenge [ 3 ]. The scarcity of clean drinking water is increasingly alarming, affecting all living organisms [ 4 ]. Moreover, Earth’s freshwater resources, including lakes, rivers, glaciers, and ice caps, are grappling with contamination due to human activities, rendering many water sources unusable. This pollution has led to the prevalence of waterborne diseases caused by harmful bacteria and viruses, underscoring the critical importance of ensuring water purity [ 5 ]. To combat contamination, purification systems like reverse osmosis (RO) are indispensable [ 6 ]. However, RO systems come with a drawback: they consume a substantial amount of energy, approximately 0.70–0.75 kilowatt-hour (kWh) to distillate 1 cubic meter (m 3 ) of freshwater [ 7 ].
The energy-intensive nature of current water purification methods exacerbates environmental challenges, underscoring the urgent need for more sustainable alternatives. Compounding this issue is India’s rapidly expanding population, which directly correlates with the escalating demand for freshwater [ 8 ]. Projections indicate that India’s population could reach 1.60 billion by 2050, inevitably intensifying water scarcity concerns. By 2040, India is expected to rank 41 st globally in terms of water shortage [ 9 ]. India’s extensive coastline, spanning 7517 km, presents a strategic opportunity for leveraging desalination as a smart and environmentally friendly solution to meet the escalating demand for freshwater [ 10 ].
The rapid expansion of global population and industrialization has exacerbated the issue of water scarcity worldwide [ 11 ]. Investigating various design and performance parameters is essential for improving the productivity of solar stills, despite being among the low water production desalination systems [ 12 ]. In response to this challenge, innovative methods for desalinating saltwater have emerged, driven by concerns over global warming and the heightened salt levels in natural water resources [ 13 ]. Among these desalination techniques, solar distillation has gained prominence due to its remarkably low energy consumption compared to methods like RO or boiling. By mirroring the natural evaporation cycle, solar distillation emphasizes simplicity and uniqueness [ 14 ]. The development of eco-friendly technologies is anticipated to play a crucial role in addressing water scarcity, with solar stills proving effective in providing ample potable water for agricultural and household needs [ 15 , 16 ]. Despite various desalination methods available, solar distillation is widely recognized as the most efficient and cost-effective option, notwithstanding some limitations in productivity [ 17 , 18 ]. Ongoing research aims to enhance the performance and affordability of solar stills, thereby making them a versatile solution for diverse applications. These include water heating, crop drying, and even electricity generation from solar panels in both urban and rural settings [ 19–21 ]. Solar stills are commonly categorized into two main types: passive and active solar stills [ 22 ]. Passive solar stills are known for their straightforward operation, ease of construction, compactness, and cost-effectiveness. They operate solely on sunlight and do not require any external energy source. However, their productivity is relatively lower compared to active solar stills. Active solar stills enhance evaporation by utilizing an external energy source in addition to solar energy. These systems can incorporate components such as heat exchangers, solar collectors, and heat pipes to optimize performance [ 21 , 23 ]. In recent times, various advancements in solar still technology have been gaining attention. These include the use of evacuated tube-type designs, different sensible heat storage materials, various fin geometries, phase change materials (PCMs), and nanomaterials. These innovations offer advantages such as ease of production, greater efficiency, lower maintenance requirements, and relative cost-effectiveness [ 24 , 25 ].
Emphasize recent efforts to integrate renewable energy sources, such as solar and wind power, into water desalination processes to enhance sustainability and reduce reliance on fossil fuels [ 26 ].
As depicted in Fig. 1 , there are two main categories of solar stills: passive and active [ 22 ]. In terms of cost, size, and operation simplicity, passive solar stills are more economical, compact, and user-friendly. They operate solely on sunlight. In contrast, active solar stills, while incorporating additional external sources to enhance evaporation alongside conventional sunlight, tend to have higher output levels. Active solar stills can integrate solar energy with various components like heat exchangers, collectors, and heat pipes to optimize their efficiency. Solar stills are also classified based on various geometrical shapes as shown in Fig. 1 .
![Classification of solar still [27–29].](https://oup.silverchair-cdn.com/oup/backfile/Content_public/Journal/ijlct/19/10.1093_ijlct_ctae116/3/m_ctae116f1.jpeg?Expires=1728510911&Signature=p8BF16nYvRNGWyny-TFXhEVk4rrqX3bJMJeze5QE7qXebouFqBajzK6TgNVxE5Euf0XRRaRpwoQYAOO-tmSr-YWuwv-zSCnelgsSQQs7eI5lquCGHuhmjtfycjTEAcDOW53TKfr56tk4jOxlWI7~1WYSrgv5dNMnzxkxypZbVYAPdAi7fTRhUvzrptQD-si6apOrUmgKMV0SWOoumdbysShaRFnl933dxD-2njby~R5nK06jbQi5V053xmQafjsocOX6-M~LLOT5JhKIXhZq7EPUBxKikAGvvLY-Fq9PwjL7Kfw4jl3tD8l0KEQ98APYQhoBY3A4CLRmPD8Ax3Fl1Q__&Key-Pair-Id=APKAIE5G5CRDK6RD3PGA "research paper about classification")
Classification of solar still [ 27–29 ].
The conventional distillation method consumes huge power, between 2 kwh to 5 kwh per cubic meter of the water distillation process. In contrast, solar still consumes nearly negligible power because solar energy is free of energy. In conventional methods, high investment, higher carbon footprints owing to high energy consumed, good materials required to avoid corrosion in case of multistage flash and multiple effect distillation, short life of the membrane, more operational costs for membrane replacement, and high pressure causes mechanical failures in case of RO [ 27 , 28 ].
Conventional distillation techniques consume huge power. So, to fulfill the population’s demand and industrial growth, the focus on renewable energy is very important. Conventional solar still (CSS) will give less productivity without any modification that can be increased by using various attachment types like evacuated tubes, reflectors nanomaterial/nanofluids, PCMs, reflectors, and solar trackers [ 30 , 31 ].
Solar stills offer several advantages over conventional distillation techniques. They are compact, featuring a simple design and easy installation process. Additionally, they are eco-friendly, utilizing renewable solar energy for operation. Unlike some complex distillation systems, solar stills do not require extensive technical knowledge to operate, making them accessible to a wide range of users. Furthermore, they require minimal maintenance and have low operating costs, contributing to their cost-effectiveness. As water purification using solar energy gains popularity due to its cost-effectiveness and environmental friendliness, solar still water distillation emerges as a promising solution to address the global challenge of water scarcity [ 32 ].
The solar distillation efficiency is directly associated with the surface area of saline water for evaporation, with an increase in surface areas, the vaporization rate also increases. Large external surface area means more surface area covered by absorber for evaporation that is exposed to the sunlight directly, hence additional increase in basin water temperature and improved productivity of stills [ 33 ]. The use of various geometry of fins in solar stills has been initiated to cause substantial progress in their performance. The longer the fins are and the larger the still’s absorber area, the less time the salt water needs to be preheated [ 34 ]. Because fins increase the still’s surface area for heat transfer, its efficiency grows as compared with CSSs. Fins with a variety of geometries, such as spiral, square, triangle, and circular shapes, are often used to improve the efficiency of solar stills [ 35 , 36 ].
4.2 Thermal energy storage
The primary energy storage technologies fall into two categories: sensible heat and latent heat. Sensible heat storage involves manipulating the temperature of the material during the charging and discharging phases to store thermal energy. When energy is absorbed, the material’s temperature increases, and when it is released, the temperature decreases. Latent heat storage, in contrast, stores energy by monitoring how a phase’s latent heat changes in a given storage medium. This method works especially well with PCMs because they have higher thermal energy-storing densities than other heat-storage materials and can absorb or release large amounts of heat energy while maintaining a steady temperature. [ 37 ]. Figure 2 represents the classification of the thermal energy storage (TES) system. Figure 3 represent the major selection criteria for the TES system. Selecting the right TES technique is crucial for efficiency and effectiveness. Key criteria include temperature range, energy density, storage capacity, thermal efficiency, cost, scalability, cycle life, safety, environmental impact, and compatibility with existing infrastructure [ 38 ].

Classification of thermal energy storage system.

Major selection criteria for thermal energy storage system.
4.2.1 Sensible heat storage
There are three types of storage
(a) Solid medium storage
(b) Liquid medium storage and
(c) Dual medium storage
In solid storage materials brick, sand, aluminum, steel, iron, concrete, rock pebbles, etc. are used while in liquid storage materials therminol, engine oil, ethanol, butane, propane, octane, calorie HT43, etc. are used [ 39 ]. Table 1 represents the thermal properties of solid sensible heat-storage materials.
Thermal capacities of solid sensible storage materials [ 40–50 ].
| Sr. No. . | Material . | Temperature range (°C) . | Density (kg/m ) . | Specific thermal capacity kJ/(kg K) . | Volumetric thermal capacity kJ/(m K) . | Reference . |
|---|---|---|---|---|---|---|
| 1 | Iron | 20 | 7900 | 0.452 | 3571 | [ ] |
| 2 | Steel | 20 | 7850 | 0.48 | 3800 | [ ] |
| 4 | Magnetite | 20 | 5177 | 0.752 | 3893 | [ , ] |
| 5 | Sand | 20 | 1555 | 0.8 | 1244 | [ ] |
| 6 | Glass | 20 | 2710 | 0.837 | 2268 | [ ] |
| 7 | Brick | 0–1000 | 1400–1900 | 0.84 | 1176–1596 | [ ] |
| 8 | Rock pebbles | 20 | 510 | 0.88 | 1410 | [ ] |
| 9 | Concrete | 20 | 2000 | 0.88 | 1760 | [ ] |
| 10 | Aluminium | 20 | 2710 | 0.896 | 2428 | [ ] |
| 11 | Sodium | 100–800 | 975–1203 | 1.3 | 750–925 | [ ] |
| 12 | Gravelly earth | 20 | 2050 | 1.84 | 3772 | [ ] |
| 13 | Wood | 20 | 700 | 2.39 | 1673 | [ ] |
| Sr. No. . | Material . | Temperature range (°C) . | Density (kg/m ) . | Specific thermal capacity kJ/(kg K) . | Volumetric thermal capacity kJ/(m K) . | Reference . |
|---|---|---|---|---|---|---|
| 1 | Iron | 20 | 7900 | 0.452 | 3571 | [ ] |
| 2 | Steel | 20 | 7850 | 0.48 | 3800 | [ ] |
| 4 | Magnetite | 20 | 5177 | 0.752 | 3893 | [ , ] |
| 5 | Sand | 20 | 1555 | 0.8 | 1244 | [ ] |
| 6 | Glass | 20 | 2710 | 0.837 | 2268 | [ ] |
| 7 | Brick | 0–1000 | 1400–1900 | 0.84 | 1176–1596 | [ ] |
| 8 | Rock pebbles | 20 | 510 | 0.88 | 1410 | [ ] |
| 9 | Concrete | 20 | 2000 | 0.88 | 1760 | [ ] |
| 10 | Aluminium | 20 | 2710 | 0.896 | 2428 | [ ] |
| 11 | Sodium | 100–800 | 975–1203 | 1.3 | 750–925 | [ ] |
| 12 | Gravelly earth | 20 | 2050 | 1.84 | 3772 | [ ] |
| 13 | Wood | 20 | 700 | 2.39 | 1673 | [ ] |
Solar stills, despite their numerous advantages, often face limitations in terms of productivity and efficiency, particularly during periods of low sunlight or fluctuating environmental conditions. To address these challenges and optimize their performance, the integration of sensible heat storage materials has gained significant attention in recent research.
Sensible heat storage materials, such as salts or rocks, can store thermal energy and release it gradually, thereby extending the operational hours of solar stills and improving overall efficiency. By incorporating these materials into solar still design, researchers aim to mitigate the effects of intermittent sunlight and enhance water production rates.
A recent study explores the use of nanomaterial as sensible heat storage agents in solar stills. The research investigates the thermal properties and performance characteristics of nanomaterial-based storage systems and highlights their potential to enhance energy efficiency and operational flexibility in solar distillation processes [ 51 ].
Furthermore, recent advancements in nanotechnology have opened up new possibilities for enhancing the performance of solar stills. Research conducted by researchers explores the integration of nanomaterial into sensible heat storage systems, resulting in improved thermal conductivity and heat transfer within the solar still, thereby increasing overall productivity [ 52 ].
These developments underscore the importance of ongoing research in optimizing solar still technology through the utilization of sensible heat storage materials. By addressing the limitations associated with intermittent sunlight and fluctuating environmental conditions, these innovations contribute to the feasibility and scalability of solar distillation as a sustainable solution for addressing water scarcity.
The alternating nature of solar energy availability necessitates the implementation of energy storage techniques to enhance the efficiency of solar stills, particularly during periods of low sunlight, such as at night [ 53 ]. Among the various PCMs recommended for this purpose, paraffin wax stands out due to its remarkable latent heat capacity. Research has shown that integrating paraffin wax into solar stills leads to greater daily output compared to those without PCM. Furthermore, combining PCM with nanomaterial has been found to further increase still productivity. Studies indicate that the addition of nanoparticles to PCM reduces the melting temperature of the PCM, attributed to the superior thermal conductivity of nanomaterial [ 37 , 54 ].
Figure 4 provides a classification of PCMs based on their organic structure, highlighting their potential applications in solar distillation systems.

Classification of phase change material (PCM).
Furthermore, combining PCM with nanomaterial has been shown to further enhance the efficiency of solar stills. Nanoparticles dispersed in PCM facilitate faster heat transfer and reduce the melting temperature of the PCM, leading to improved thermal performance and overall system efficiency.
The utilization of energy storage techniques, particularly PCM integration, in solar stills addresses the challenge of intermittent sunlight availability, thereby maximizing system efficiency and productivity. This approach contributes to sustainable water desalination and addresses water scarcity concerns.
4.3 Using evacuated tubes integrated with solar still
Evacuated tube collectors for hot water typically comprise sealed glass tubes housing an internal absorber plate, along with either a heat pipe or copper rods. These tubes are strategically integrated into solar still systems to augment the evaporation rate of saline water, consequently boosting the productivity of the solar still [ 55 , 56 ].
Figure 5 demonstrates that the combination of solar stills with evacuated tubes forces convection.
![Solar still arrangement with multiple evacuated tubes [15].](https://oup.silverchair-cdn.com/oup/backfile/Content_public/Journal/ijlct/19/10.1093_ijlct_ctae116/3/m_ctae116f5.jpeg?Expires=1728510911&Signature=draNmyzDRWXJRgvTq9Glmzdag7~llmgYJOUaZ5V2sAcrePQhE~xQiFZRR8kne2BNZRn9BYN6e~zX8QlrSoBmSrJSkcMH2HbYUnCR7friEGx1xFuQSwDfZe2f~nIa0V-SAOQnGP-7ywM-lqyFTiKgQnh782d~XRukUoJzjKuszxiripBqWLxUWEtVwaAHJNyeS4NVTyAqzrYamZIP-staz34k-EbHBe7Ok8BQ~y57f1gXPE5zCDD96YXYsl8Mkll71rekcNMFVxxjSa9aNWugPEVoN8N8RX0WzCAGbxcmHDxA~E3jDJjpjwU6Yz9wSxDg0mc00fBAln80KDftk64jqw__&Key-Pair-Id=APKAIE5G5CRDK6RD3PGA "research paper about classification")
Solar still arrangement with multiple evacuated tubes [ 15 ].
The size of the tubes and the distance between the two tubes, respectively, also affect the outcome of the solar still. Smaller-size tubes exhibited better thermal performance than larger-size evacuated tubes. Transportation may cause damage to longer tubes; thus, many researchers suggest utilizing shorter tubes in conjunction with solar stills to enhance the productivity of the stills [ 57 , 58 ].
4.4 Nanomaterial/nanofluids
Nanomaterials are defined as substances that possess dimensions ranging from 1 to 100 nm, exhibiting distinctive features that arise from their minuscule size. These materials, such as nanoparticles and nanotubes, have heightened reactivity, strength, and conductivity. Nanomaterials are extensively employed in the fields of health, electronics, and energy to facilitate precise drug administration, enhance electronic components, and improve energy storage systems. Their adaptability provides innovative solutions in the field of materials science, encompassing a wide range of applications such as reinforced composites and catalysis. The ethical and safety concerns of nanomaterials remain under examination in research and development, notwithstanding their advantages [ 58 , 59 ].
Nanofluids are precisely crafted mixtures of nanoparticles and a base fluid, which display exceptional thermal and fluidic characteristics. Nanofluids are usually made up of nanoparticles, whether metallic or non-metallic, that are evenly distributed in liquids like water, oil, or glycol. These nanofluids have the advantage of increased thermal conductivity, greater efficiency in transferring heat, and modified rheological properties. Nanofluids possess distinct attributes due to their large surface area and strong reactivity, which render them highly desirable in diverse applications. Industries utilize nanofluids to enhance heat exchange in electronics cooling, sophisticated cooling systems, and heat transfer fluids. Furthermore, nanofluids are being investigated in medical applications specifically for targeted hyperthermia treatments. Ongoing study is necessary to completely comprehend and optimize the use of nanofluids in various domains due to problems linked to stability, cost, and long-term consequences, despite their potential advantages [ 60–62 ].
Figure 6 illustrates the categorization of nanomaterials according to the various groups and criteria that are under consideration [ 60 ]. The morphology, dimensionality, condition, and organic structure of these organisms are typically used to characterize them. In addition, the classification of NMs is dependent on their diameters, which can range anywhere from 1 to 100 mn [ 61 ].
![Categorize nanomaterial based on different criteria [60].](https://oup.silverchair-cdn.com/oup/backfile/Content_public/Journal/ijlct/19/10.1093_ijlct_ctae116/3/m_ctae116f6.jpeg?Expires=1728510911&Signature=p4xrgOxJMYpUNkC-7pT0DnorBQ~a2DsEou~UiU~~ziyldAh4W0-EORofXruJ6P39QR-Y59NV4REsz2sP1IRXxvHAy-c9y7Ln9quhHgGOd7IJJZkqZLJaN-GE8O5KL3iMzjbt4mF3S0EKSY8fB~QELMVNHGieOsZweumRJjQb4vqnGnEzjNIy0t6p24WG5Ze1OTAEK4hczqJwKcTxUgULCfFpdOMXmw363BrtbQ-p8tgnPCoIhySG-6hAPQmPOayziKQ3yyjAdv1flinVtwFREA43xs7nnvbNlNpyX8JWjsYxN51c4peKx-JteIrAY~AUXYffqfWG~8ygwtEq~ZlkpA__&Key-Pair-Id=APKAIE5G5CRDK6RD3PGA "research paper about classification")
Categorize nanomaterial based on different criteria [ 60 ].
4.5 Use of integrated structures
The efficiency of solar stills is significantly improved through the utilization of reflectors and concentrators. Reflectors are not only inexpensive but also advantageous in terms of enhancing the still’s overall productivity. The additional solar energy that was not falling on the evaporative surfaces of solar stills was focused back into the evaporative surfaces by reflectors, which received the additional solar radiation. This rise in the rate of vaporization within the solar still contributes to an increase in the productivity of solar distillation. The objective of solar concentrators is to capture and concentrate the sun’s rays in order to generate extremely high temperatures. This is accomplished by the utilization of mirrors and parabolic reflectors of a channel, tower, and dish or a refractive lens, which ultimately results in an increase in the productivity of solar energy [ 63 ].
Figure 7 represents the modified Solar still with external and internal reflectors, and Fig. 8 represents the solar still modification with a parabolic-type solar concentrator and receiver.
![Solar Still basin with reflector [63].](https://oup.silverchair-cdn.com/oup/backfile/Content_public/Journal/ijlct/19/10.1093_ijlct_ctae116/3/m_ctae116f7.jpeg?Expires=1728510911&Signature=vEWlOi-bHn1MoD3LWeH76x~jZ0t2qx4Lq09SFRNZHTSKPfQ6f7O3mRnLqDKK4imLhy4cChpTncTWmEY3aFFBoB1EqPyARt-alRGLSXx7SF~ZFXyWbZ0cIviaKAQwnIb~eGZj-wJl66IFvAyalhyoS8xVxMwWgv2J0P92rhbGbmJSwY4t3xeTB~lEcS9g4QlWZuWqHlT1rkmjIcpMlk1BBeD4grtgHkgoepehE5X2nMmakmVOzu~bARiOv7mzQxnrVVy2hc-a3GqdbOmMQgePfOOJRY46gXwhsfoiRvl7SwF~tVN4Sni3VX4ggO8BG9stECo7QEpP42VA2rfctYCRww__&Key-Pair-Id=APKAIE5G5CRDK6RD3PGA "research paper about classification")
Solar Still basin with reflector [ 63 ].
![Solar still with receiver and concentrator [64].](https://oup.silverchair-cdn.com/oup/backfile/Content_public/Journal/ijlct/19/10.1093_ijlct_ctae116/3/m_ctae116f8.jpeg?Expires=1728510911&Signature=w2in5aqWaObTnwgIShfWCPGuGaKcohg0PRFv9UasfQ11xDf61sfYvbC~SU0F9RdWETwFL6TXAvCEkft1S6toZyQMc8HYeTQ4uHPbhogQVDCPjjRuBcawpXOdweFP7XZq2LXGbcApWaKFxg5KBcXQIcmLZIwDaPbTJQap3s~o9Kgs-tTM30edxC26Nr-MmrMJ1YmHofJ07XHGarC~RZ22k9GTbf6d6nmKE85343aQ69COpQ5UqsnYInmyKD-syCzf6VOCCV6kk5iF5d6Y2YC8qLW5OdF20SGWc41jVBdWSq6Focn-8fqBU5XPpZ5E2sSFyGGda9LKomquqfEZGqPO1g__&Key-Pair-Id=APKAIE5G5CRDK6RD3PGA "research paper about classification")
Solar still with receiver and concentrator [ 64 ].
4.6 Climate parameters
The major stills include a variety of different materials and patterns that have been transformed. The quantity of water that may be generated varies widely and is under the control of a number of numerical characteristics (See Fig. 9 ). These parameters include general meteorological circumstances, operational tactics, and the design of solar still, among others. Because it has relatively minimal costs of operation. The process of solar distillation is viable for commercial use [ 77–73 ].

Meteorological parameters.
Four triangular condensing covers join together at the top vertices of a pyramid-shaped solar still, which is also called a pyramid-type solar still (PSS). An increase in the area where condensation is occurring allows more radiation to enter the basin [ 65 ].
The condensing surface area of a PSS is greater than that of a conventional single-slope solar still. Consequently, compared to other kinds of sun stills, PSSs produce more condensation [ 66 ]. This is due to the fact that solar stills shaped like pyramids have a larger condensing area.
Based on previous experimental results, the use of hollow fins raises productivity to 5.75 L/m 2 /day, which is a 43% improvement over the daily productivity output of the (CPSS) classic PSS. Production rates of up to 8.1 L/m 2 /day, or 101.5% higher, were observed in PSSs that had PCM added compared to those without [ 67 ].
5.1 Literature survey on PSS
Kianifar and Mahian [ 68 ] conducted both analytical and practical investigations into the forced convective heat transfer in square pyramid-type solar stills with a single basin [ 68 ]. Their experimental approach included the installation of a small DC fan in the solar still ( Fig. 10 ) to induce constant turbulence in the evaporated water vapor flow. A variety of factors, including wind speed, Reynolds number, water level, and insulation thickness, can affect the efficiency of PSSs. To test this, researchers used both free and forced convection models, with the former using no fan and the latter using a small fan. According to the reference, pyramid-type solar stills that have small DC fans installed can increase their daily average yield by 15–20% [ 69 ].
![Forced convective heat transfer in active pyramid solar still using small DC fan [68].](https://oup.silverchair-cdn.com/oup/backfile/Content_public/Journal/ijlct/19/10.1093_ijlct_ctae116/3/m_ctae116f10.jpeg?Expires=1728510911&Signature=IG2Zz18cqXe1lgYNGX3SVvxzhMkPowMAW56aTuUqbOIvkxqXfefBvUBPBYplqqgew4qKnallXxNERZus1okVW5fWd44~cqxe7Re1YbEsZuJi9XomvSNP4zu-al1tNE8fMN~FeF2WIStP17cHPetPtSzB47sXIi25W5h14BfeqKEqaZ6e~c7gDpJzv6oO0hXmyLqR6NZSxxQs1wiFBf4UXO1uhoZESbHcNFQpBCCQTQRywISqdMha2C5ugkOzN4UrXK71TW~uDNTqig~zI7cxoF-nsRo66uDymXW7qntrGqPMInFSI~Xj3RbSxt7zOga6WhU6flQyv~97kdzXQf-Krg__&Key-Pair-Id=APKAIE5G5CRDK6RD3PGA "research paper about classification")
Forced convective heat transfer in active pyramid solar still using small DC fan [ 68 ].
Taamneh et al. [ 70 ] conducted a performance evaluation of solar stills in Tafila City, Jordan, comparing models with and without fans. Figure 11 (a) shows the installation of a small DC fan (~10 W) on the glass cover of the PSS, which was driven by a solar photovoltaic panel, in order to induce air circulation within the still. The effect of forced convection on the efficiency of solar stills of the pyramid type was the subject of experimental investigations. In comparison to free convection, their research showed that systems using forced convection via fans enhanced freshwater production by about 25%. By constantly stirring up air currents on the water’s surface, fans hasten the evaporation process and make it easier to remove the vapor. The researchers stressed that a simple and inexpensive way to increase the effectiveness of pyramid-type solar stills is to install a fan.
![Square pyramid solar still (a) active solar still with a fan (b) passive solar still without a fan [70].](https://oup.silverchair-cdn.com/oup/backfile/Content_public/Journal/ijlct/19/10.1093_ijlct_ctae116/3/m_ctae116f11.jpeg?Expires=1728510911&Signature=yrNbO913GG3~-~FmbaMs9r5artTG~5eduKeIwAi8J~cZHas1V0dZ8isnB16hHkhClnng6dsyXjI7m7ewFaLINmIngu2CdF0wvResFOgw1o0V4sAS8ybo9qYb5fGBiz-dpfiVVAFA8iU0q~EaYI1LHhOa6sh4xvaTLS1~asz9V7idZ3T35ETd1Evk71Iy06yKE1hzNsIY83zT0PyLoYin3hrw3NqZrJXEEnB1NbzmL1mKpRzD8kw3w0oK-Sm~jN11EhfRJtFwM4rbmukug-p-muzAiYVn1AQbVyAkWTep2lMQdHXXrgxNcTqitYrQCPYtRR8nYr7MtankRbJhnx1d5g__&Key-Pair-Id=APKAIE5G5CRDK6RD3PGA "research paper about classification")
Square pyramid solar still (a) active solar still with a fan (b) passive solar still without a fan [ 70 ].
Kabeel et al. [ 71 ] investigated the impact of different condensing surface inclination angles on the performance of square PSSs under the climatic conditions of Tanta City, Egypt (φ = 30.47°N). Figures 12 and 13 show the three square pyramid-type solar stills that were built for the study. Angles of 30, 47, and 50 degrees were established for the glass covers. The experiment, conducted in a basin with a salinity level of 2 cm, revealed that at an angle of 30.47°, the three systems achieved a still productivity of 4.3 l/m 2 , at 40°, of 3.5 l/m 2 , and at 50°, of 2.93 l/m 2 , as illustrated in Fig. 12 . As the glass cover angle increased beyond the latitude angle, the researchers saw a notable decline in the output of PSSs.
![Experimental Setup of comparison at three different top glass cover angles [71].](https://oup.silverchair-cdn.com/oup/backfile/Content_public/Journal/ijlct/19/10.1093_ijlct_ctae116/3/m_ctae116f12.jpeg?Expires=1728510911&Signature=WdgH4i13mjadF3SAhUlyCv18EM7e60YwvrcRFRXmrq1ij3pP~FOreA~-MzV68scAgjtVMrzsZSIblseK4ZWH8B37oANAtDtlDcPA9TnQGb5rS3eQ4TuIqAv8BGwCTfhHWVYVvPi16JQ8GEz8sr9Krq4-Vu8XJWysKKbkh6PVKXUxMPgEk7ehDCRBok4Ve1vKyh1z9g724na~hu-ujYxTjY5FG8XhnbgO9giC6M96Vsoj7ErL24vfE0D379KJ7jYPcPJxR1eQWPmwWVEhPlOQ~EEU0lxkh2PYzK1x5ks7nwy61NVjHtCikATa33bkfVBHNWI92NDgusPHMU5JoCQpfQ__&Key-Pair-Id=APKAIE5G5CRDK6RD3PGA "research paper about classification")
Experimental Setup of comparison at three different top glass cover angles [ 71 ].
![Schematic of Square pyramid solar stills at different top glass cover angles [71].](https://oup.silverchair-cdn.com/oup/backfile/Content_public/Journal/ijlct/19/10.1093_ijlct_ctae116/3/m_ctae116f13.jpeg?Expires=1728510911&Signature=oouH67g0HDL5OeaWl25gg5Dm6WK3y3vsEDBv~SHYfWuSngIYVS9FkT1ZLyXvzi7~AkM738cs-kwBdo7L-GbpxIF0gtGPgiDtsnwjeaVViZh8Uo6XAqfgor1Cw9UJsTbvIuTm3VZOsgnXkG1cCNN~r4M09uj1sCmH5NczwkiPkP0AhfJecKmOtHiNBWX~fDeJux6tUPkqhimU2pm0HHK9GSAEDcswakPuzwYIS7VZFmWJ-PGDL9E92qt0VtcjkvxkZ2F6Gw4HIsovFcTZlBi0Fzda6Yak8zu9gVKcq~WZG-xmdzg9ZQWsdrDTsi1zvo7lASawzeGK1mHY7av4xQpWXw__&Key-Pair-Id=APKAIE5G5CRDK6RD3PGA "research paper about classification")
Schematic of Square pyramid solar stills at different top glass cover angles [ 71 ].
Wissam et al . [ 80 ] presented a novel design enhancement for pyramid-style solar stills aimed at enhancing performance. The modification involved incorporating four rotating cylinders into the basin of the pyramid-shaped solar still. To heat the water in the basin, three electric heaters were employed, driven by the PV system depicted in Fig. 14 .
![Experimental setup (a) practically tested distillers with PV, (b) side view of solar still, (c) heaters from outside the distiller, and (d) the arrangement of the chains, pulley, and motor. [72].](https://oup.silverchair-cdn.com/oup/backfile/Content_public/Journal/ijlct/19/10.1093_ijlct_ctae116/3/m_ctae116f14.jpeg?Expires=1728510911&Signature=RFgL-aFLKp0kQjCaMGnYcn9gWz9C6ERRR0GESI2M887a741tPIP8RdPIsY24oNUt2pCGVcr9RPGRdOEWGIV4IvaxEZMOrbzqvLR-AIUkikJVAAc736Y2i3~Pi8ekPbPpRnSZYFg0FBkk5ID0ZkmQwceo~BgVixfSbR6TtvxJXlViJXbwik3NUH2Qoq4UptNzr2EoMAjnv5hRij0mdypV1q7OWx5FYGGOi~4DTSoHOvWpzG83A~k1NT4Fs-YUAyNafJTakQJL3Vf-mOnX30oRyJW9uGrxI~sNAxjvt8YzMFj1v5kD9XcQf-TT3AJzcfXyGxAUS~1V~TgtVgVfBsQOeQ__&Key-Pair-Id=APKAIE5G5CRDK6RD3PGA "research paper about classification")
Experimental setup (a) practically tested distillers with PV, (b) side view of solar still, (c) heaters from outside the distiller, and (d) the arrangement of the chains, pulley, and motor. [ 72 ].
Alawee et al . [ 72 ] conducted an evaluation of the MPSSRC’s (a modified pyramid-type solar still with revolving cylinders) performance at different revolutions per minute (rpm), spanning from 0.1 to 2.0 rpm. The MPSSRC, excluding the heaters and the reference still, exhibited a total distillate of 7.3 L/m 2 /day, compared to the reference still’s 3 L/m 2 /day, showcasing a notable 144% improvement. The inclusion of heaters in the MPSSRC resulted in a total distillate of 9.1 liters per square meter per day, marking a 24% increase in production. The optimal output was achieved at a cylinder rotation speed of 0.5 revolutions per minute. The thermal efficiency of the MPSSRC was notably increased by incorporating electric heaters rotating at a speed of 0.5 revolutions per minute, reaching 66% efficiency with heaters and 54% without heaters.
A new solar still design, the multi-sided stepped square pyramid-type solar still (MSSPSS) ( Fig. 15 ), was introduced by Beik et al . [ 73 ]. Using a salt-gradient solar pond, the system was tested in both active and passive modes, both in theory and practice. In the winter, the average purification yield per square meter was 1.92 L/day, whereas in the summer, it increased to 12.16 L/day. In accordance with the suggested setup, the MSSPSS should be able to produce around 2538 L/m 2 per year while keeping an average efficiency of about 50%.
![Schematic diagram of multi-side-stepped square pyramid solar still. [73].](https://oup.silverchair-cdn.com/oup/backfile/Content_public/Journal/ijlct/19/10.1093_ijlct_ctae116/3/m_ctae116f15.jpeg?Expires=1728510911&Signature=BO2cY0RHkV41ADWUXSQawX7~PDMHxtQJbfULNYNC7ZUYTr9YaTdMLC~mgogYQl4fqmVa3NGwu95~zn46HHOYLnQF6BpEflgRQjhuLJ48KaiqPvNMbGyiV7Iq8VLd5TwOVvqHctCCnGP39oLsZiM-TxTpm4IPe6G4IneObZJb7hh3Gr~8KgM-obxJJj5UkQyuvrephghDc8~yYCITu5vzisTwHUmLex5m5Ye4cwVgnbm~gBdUKyq1KrC6j~1KoGsjOJq-XPd06rsP~63NwJ5-6aGbMTav7Q3SIs6RCudJSlEgPyBTNmPwRS9EcFAkWb7h7k1pE5mhuO76Azf5kwg25A__&Key-Pair-Id=APKAIE5G5CRDK6RD3PGA "research paper about classification")
Schematic diagram of multi-side-stepped square pyramid solar still. [ 73 ].
Figure 16 shows the results of an experiment that Sharshir et al . [ 74 ] ran to test a PSS with evacuated tubes. To improve the stills’ thermal efficiency, they added nanofluids. An economical reference CSS, a conventional pyramid solar still (CPSS), and a modified pyramid solar still (MPSS) were the three units tested in the studies. In terms of overall freshwater output, the results showed that MPSS was superior to CPSS and CSS, with a 4.77% and 26.6% advantage, respectively.
![Modified pyramid solar still combined with evacuated tubes. [74].](https://oup.silverchair-cdn.com/oup/backfile/Content_public/Journal/ijlct/19/10.1093_ijlct_ctae116/3/m_ctae116f16.jpeg?Expires=1728510911&Signature=SN9Y7iCxssIlwH5RnycqWDpxgi2aO~hKFhXaoN3Fea7A4-GuZqFlXVik7kpTB9kRVAaHB6Km6H~vQRygf3FMN7aZEEa~ABzdBBrP~XDFAeZEr30j-MQpzdgahLrWlBms2-zvEouScDX1uS2ZcgGvW6b6-Fru0JdmCf~I8iQT-8kOnmvxRHfYcfcIUX9gQtjx3WtQVzGfLSkhvMOtXTnHYVo9bw~4XFse6KXuNAunbBeFrWxYXIQejZgFb5A8n4Lnfs47MB2ESntv8fRg-K7S89SfbvX7dZDFXokxrCmjjafOlzxzA-vb6g2QC7jIOYJdNaFhSScAXVc5iqd128Jjgg__&Key-Pair-Id=APKAIE5G5CRDK6RD3PGA "research paper about classification")
Modified pyramid solar still combined with evacuated tubes. [ 74 ].
Additionally, when MPSS with copper oxide was utilized rather than CPSS and CSS, the total amount of freshwater was increased by roughly 27.25% and 54.48%, respectively.
In the case of MPSS with copper oxide over CPSS and CSS, the enhancement percentage in total freshwater was 33.59%. For MPSS with carbon black over CPSS and CSS, the enhancement percentage reached 57%. Moreover, the daily efficiency (η d ) of MPSS was 50%. In comparison, it reached 61% and 64.5% for MPSS with copper oxide and carbon black, respectively. On the other hand, η d reached 48% for CPSS and 30% for CSS. Finally, the cost analysis conducted indicates that the proposed MPSS with nanofluids offers optimal thermal performance at an economically reasonable cost [ 74 ].
In their investigation of a triangular pyramidal solar still, Ravi Shankar et al . used paraffin wax as the PCM of choice. Despite the extreme heat in Chennai, India, the research was carried out as shown in Fig. 17 , which shows the model diagram. With a thickness of 10 mm and a coating of black paint, the PCM was placed toward the basin’s base to reduce heat loss.
![Schematic diagram of the pyramid-shaped solar still with hollow circular fins and PCM [67].](https://oup.silverchair-cdn.com/oup/backfile/Content_public/Journal/ijlct/19/10.1093_ijlct_ctae116/3/m_ctae116f17.jpeg?Expires=1728510911&Signature=AELRY1p9sCFcNcL73pvYZ-VYi1L7edulRZubAMoudSLJYN4KFQcY8pU~ck6kmlR-0SiX9v0eq7wvhxhtowiynHTI9ve68gZNVuL3Si8GgJTxb5BEZLPo8SmOUif3TUVyTOOxiAFqmr-tYGUfDx2vQzDLpPmYDvCe-WUwg0ukc-WeNAoBrwjv-8g7mbgGjwX6vrIeYF2Tfnm4DQ~Mllw9JHAN~W-nNaoXIckMJ9YMfkX6kpisTu-HrNHtjqi02P-AS0JnoyJDhlXkUeWBXpHDurHhN3yy-HlLsDsNs8cCp~PFWe~TKUmh77~MzFSsadolMh94srzDA9T4E4-SezVu~Q__&Key-Pair-Id=APKAIE5G5CRDK6RD3PGA "research paper about classification")
Schematic diagram of the pyramid-shaped solar still with hollow circular fins and PCM [ 67 ].
Kabeel et al . [ 67 ] demonstrated enhancements to PSSs by incorporating a copper fin array onto the absorber plate and integrating a PCM tank at the bottom. They examined three configurations: a standard PSS, one with hollow circular fins, and another with hollow circular fins combined with PCM. While the standard model yielded a maximum of 4.02 L/m 2 /day, the version with hollow fins produced 5.75 L/m 2 /day, marking a 43% daily production increase.
Essa et al. [ 75 ] investigate the impact of various longitudinal and square baffle designs within the basin of the CPSS on its performance, with and without the incorporation of Ag nanoparticles. The study also explores methods for enhancing evaporation and condensation levels through the introduction of reflectors and vapor extraction in CPSS. Furthermore, a thermo-enviro-economic analysis was conducted to assess the economic viability of the proposed system. The findings revealed significant improvements in distillation efficiency with square baffles (CPSS-SB) and lined baffles (CPSS-LB), achieving productivity increases of 193% and 162% over the standard PSS, respectively. The utilization of reflectors with CPSS-SB further augmented productivity by approximately 233% compared to PSS. Introducing a fan and reflectors led to a production boost of around 257% for CPSS. Moreover, CPSS-SB with Ag nanoparticles demonstrated a productivity increase of 274% over PSS. With Ag nanoparticles, the productivity enhancement for CPSS (with reflectors and fan) reached 274% and 282%, accompanied by thermal efficiencies of 68.8% and 70% at 25 and 35 cords, respectively. The reported expenses for treated water were $0.0141/L and $0.01/L for PSS and CPSS-SB-Ag, respectively. Additionally, CPSS-SB-Ag had an environmental impact of 28.71 tons of CO 2 annually.
After making certain adjustments, Essa [ 67 ] studied a solar still that was based on a triangle pyramid. A pyramid absorber, which increases the surface area for vaporization, was used in place of the flat absorber in the experiment. Multiple wick materials, such as cotton and jute cloth, were utilized in the pyramidal absorber that was the subject of the investigation. Using an extra condenser and reflectors to increase solar energy input, the performance of the modified pyramid-type solar still (MPSS) was further investigated. The MPSS’s pyramidal absorber was also used to test a PCM made of paraffin wax and Ag (silver) nanoparticles. Using the redesigned absorber increased the evaporative surface area by 40%, according to the results. Because of its better performance, jute cloth was suggested for the MPSS instead of cotton cloth. In addition, the MPSS performed best with a condenser and mirror setup, which increased production by 142% and improved distiller efficiency by 52.5%. In Figs. 18 and 19 , the study illustrates the different improvements made to PSSs [ 67 ]. The best performance of MPSS was obtained with mirrors and condenser [ 76 ] Also, utilizing reflectors with CPSS-SB increased the output over the PSS by almost 233% [ 75 ].
![Modified pyramid solar still [76].](https://oup.silverchair-cdn.com/oup/backfile/Content_public/Journal/ijlct/19/10.1093_ijlct_ctae116/3/m_ctae116f18.jpeg?Expires=1728510911&Signature=XRJwIN2JzMRE2Y7oqmu5mYTkHEHK2Sr~bYmmrOoQ5DFdJZCcEEXmzX3HWTJHy7rwQHQwd6Le88JiD751GdA4sxT14ia9U7t-xjqCEdbiQZwoQf2XlnV4nLFYcHUszV0m4lnh8VZyokdYkDv9~UYx4VM76YBs5eqBh7rr8UTeiX1yTBH2EdlDdInOgsHDJqDy9VWKgT1H855gbFnuvgnWrUsz9TGqjyoiqi3sWSI5jXOch7Rk3Z5b63JgSfP0vwzc9TweX7gVxGwiWGyuTHCsLSGSgnZxluJPSSnlZXQa~Dj959jlPl99xgTLYUQWKzDGIfgoh8ELd5PFHID0c672jw__&Key-Pair-Id=APKAIE5G5CRDK6RD3PGA "research paper about classification")
Modified pyramid solar still [ 76 ].
![Schematic diagram of modified pyramid solar still [76].](https://oup.silverchair-cdn.com/oup/backfile/Content_public/Journal/ijlct/19/10.1093_ijlct_ctae116/3/m_ctae116f19.jpeg?Expires=1728510911&Signature=xTmnfBRtZHFsDN4~Am~OOx6AMB1SMkRDyoAwdfps21nGZK3aJ4UBccuXXi13lFL3rDonds9QYO5NOJ8qU6f890yRcWUYo5dQ4JQZsViaebv48O2bIv4bW~-hhCDfoPYxvtqJQEtvH1Y7LsV-vAf4RNIIPSR7Vwvdt2873GeCO8RQ1-NVgNj5tbofHVUp4laMqeTK-HIW-xtXbxsA-E3wpK6NLIEdLRRe9XwShtVjXfuSwdyL0rYOtJDoqu1UPzt7I8XsLBiEX9gb7wNNDMN-csMKBWKlvi7s9See8cy4NUONq3okA~-WfVF2G90veooJioktl6hT~ramNitCHouguw__&Key-Pair-Id=APKAIE5G5CRDK6RD3PGA "research paper about classification")
Schematic diagram of modified pyramid solar still [ 76 ].
Table 2 represents the relative study of performance improvement of numerous types of solar stills by using several techniques to increase the efficiency of solar stills.
Previous investigations of performance improvement of pyramid solar still.
| Author with reference number . | Modifications . | Efficiency . | Productivity improved . |
|---|---|---|---|
| Fadl A. Essa [ ] | Pyramid solar still (PSS) + condenser + external mirrors | 52.50% | 142% |
| Kabeel [ ] | Pyramid-type solar still + concave wick | 30% | 95% |
| Saravanan and Murugan [ ] | Pyramid solar still + woollen cloth wick material | 29.60% | 40.30% |
| Prakash . [ ] | Pyramid-type solar still + blackened blanket (wick) | 50.25% | 17.68% |
| Sathyamurthy . [ ] | Triangular pyramid solar still + PCM | 53% | 20% |
| Kabeel . [ ] | Pyramid still + V-corrugated absorbers plate + PCM | 70% | 87.40% |
| Kabeel [ ] | PSS + fins (hollow circular) + paraffin wax | 64.30% | 101.5% |
| Kabeel and Abdelgaied [ ] | Pyramid solar still + graphite absorber plate + glass cooling | 70.98% | 107.70% |
| W.H. Alawee [ ] | Modified pyramid solar still + rotating cylinders + heaters | 65% | 214% |
| Hamdan . [ ] | Pyramid solar still + multiple basin | 44% | 24% |
| Kabeel [ ] | PSS + V-corrugated plate with PCM | – | 88% |
| Taamneh and Taamneh [ ] | Pyramid-type solar still with forced convection | – | 25% |
| Kabeel . [ ] | Solar still + fan + PV system | 38% | 25% |
| Senthil Rajan . [ ] | Pyramid-type solar still + biomass heat source | – | 84% |
| Manokar . [ ] | Pyramid solar still + insulation | 28.50% | 19.46% |
| Zeinab and Ashraf [ ] | Pyramid solar still + rotating shaft + PV system | 40% | 50% |
| Farouk [ ] | Case 1 PSS + Cu O (copper oxide) Case 2 PSS + Al O (aluminium oxide) Case 3 PSS + TiO (titanium oxide) | – | 57% 46% 36% |
| Author with reference number . | Modifications . | Efficiency . | Productivity improved . |
|---|---|---|---|
| Fadl A. Essa [ ] | Pyramid solar still (PSS) + condenser + external mirrors | 52.50% | 142% |
| Kabeel [ ] | Pyramid-type solar still + concave wick | 30% | 95% |
| Saravanan and Murugan [ ] | Pyramid solar still + woollen cloth wick material | 29.60% | 40.30% |
| Prakash . [ ] | Pyramid-type solar still + blackened blanket (wick) | 50.25% | 17.68% |
| Sathyamurthy . [ ] | Triangular pyramid solar still + PCM | 53% | 20% |
| Kabeel . [ ] | Pyramid still + V-corrugated absorbers plate + PCM | 70% | 87.40% |
| Kabeel [ ] | PSS + fins (hollow circular) + paraffin wax | 64.30% | 101.5% |
| Kabeel and Abdelgaied [ ] | Pyramid solar still + graphite absorber plate + glass cooling | 70.98% | 107.70% |
| W.H. Alawee [ ] | Modified pyramid solar still + rotating cylinders + heaters | 65% | 214% |
| Hamdan . [ ] | Pyramid solar still + multiple basin | 44% | 24% |
| Kabeel [ ] | PSS + V-corrugated plate with PCM | – | 88% |
| Taamneh and Taamneh [ ] | Pyramid-type solar still with forced convection | – | 25% |
| Kabeel . [ ] | Solar still + fan + PV system | 38% | 25% |
| Senthil Rajan . [ ] | Pyramid-type solar still + biomass heat source | – | 84% |
| Manokar . [ ] | Pyramid solar still + insulation | 28.50% | 19.46% |
| Zeinab and Ashraf [ ] | Pyramid solar still + rotating shaft + PV system | 40% | 50% |
| Farouk [ ] | Case 1 PSS + Cu O (copper oxide) Case 2 PSS + Al O (aluminium oxide) Case 3 PSS + TiO (titanium oxide) | – | 57% 46% 36% |
This assessment highlights potential modifications for future advancements in the development of pyramid-shaped solar stills. The performance of these solar stills can be significantly improved through various enhancement techniques and experimental conditions, including optimizing fin geometry, adjusting the concentration of nanomaterial in the fluid, incorporating nanocomposite, and optimizing the number of evacuated tubes and reflectors. These factors directly address concerns raised in previous studies, contributing to enhanced performance. However, challenges and difficulties in still design need continued scrutiny for further performance improvement. Current research efforts aimed at enhancing pyramid-type solar stills should be reassessed and advanced. New research under similar climatic conditions, exploring novel combinations of nanomaterial with PCM and determining the optimal number of evacuated tubes, along with identifying the most effective fin geometry, holds potential for achieving cost-effective and optimal performance. The presence of nanomaterial brings to a rise in the thermal property of the fluid, leading to an increase in the water temperature and thermal conductivity of nanofluids, as well as an increase in the distillate production.
Through the utilization of PCM, nanomaterial, and solar water heaters integrated with PSSs, the highest possible distillate has been managed to be achieved.
It has been noted in the literature that the combination of a pyramid-shaped solar still with fins enhances its performance compared to a traditional solar still. This is because the extended fins geometry increases the surface area, resulting in more efficient heat transfer to the surrounding water and reduced surface losses.
Pyramid-type solar stills that use PCM and nanomaterial are more efficient than those that use just one of these materials in conventional stills.
Technology that distils water plays a crucial role in human existence since it helps places that are short on water supply to get clean, distilled water.
In comparison to the CSS, the pyramid-type solar still was shown to have a higher distillate production.
The distillate is produced by increasing the water temperature through the use of solar collectors such as evacuated tube collectors and parabolic dish collectors, as well as flat plate collectors. One of these, the evacuated tube collector found excellent results.
Future work on PSSs and single slope solar stills could encompass several avenues of research and development to enhance water distillation efficiency and suitability for local conditions.
Investigate ways to optimize the design parameters of both types of stills to maximize distillate yield and minimize energy consumption.
Explore advanced materials for construction and components of solar stills, considering factors such as durability, cost effectiveness, and local availability.
Research the integration of innovative materials, such as advanced coatings or membranes, to enhance heat absorption and minimize heat losses.
Investigate novel heat transfer mechanisms within solar stills to improve efficiency, such as the utilization of PCMs, nanomaterial, or advanced heat exchangers.
Distillate production is facilitated by increasing water temperature using various solar collectors such as evacuated tube collectors, parabolic dish collectors, and flat plate collectors. Among these collectors, evacuated tube collectors have shown promising results.
Deploying integrated solar distillation systems equipped with PCM, nanomaterial, and solar water heaters in field settings to validate performance under practical conditions.
Open Access funding provided by the Qatar National Library. The findings herein reflect the work, and are solely the responsibility, of the authors.
None declared.
Kumar R , Chanda J , Elsheikh AH . et al. Performance improvement of single and double effect solar stills with silver balls/nanofluids for bioactivation: an experimental analysis . Sol Energy 2023 ; 259 : 452 – 63 .
Google Scholar
Modi KV , Patel PR , Patel SK . Applicability of mono-nanofluid and hybrid-nanofluid as a technique to improve the performance of solar still: a critical review . J Clean Prod 2023 ; 387 : 135875 .
El-Ghonemy AM . Performance test of a sea water multi-stage flash distillation plant: case study . Alex Eng J 2018 ; 57 : 2401 – 13 .
Gleick PH . Basic water requirements for human activities: meeting basic needs . Water Int 1996 ; 21 : 83 – 92 .
Panchal H , Patel K , Elkelawy M . et al. A use of various phase change materials on the performance of solar still: a review . Int J Ambient Energy 2021 ; 42 : 1575 – 80 .
Katekar VP , Deshmukh SS , Elsheikh AH . Assessment and way forward for Bangladesh on SDG-7: affordable and clean energy . Int Energy J 2020 ; 20 : 421 – 38 .
Saravanan R , Sathish T , Sharma K . et al. Sustainable wastewater treatment by RO and hybrid organic polyamide membrane nanofiltration system for clean environment . Chemosphere 2023 ; 337 : 139336 .
Lindström M , Heikinheimo A , Lahti P . et al. Novel insights into the epidemiology of Clostridium perfringens type a food poisoning . Food Microbiol 2011 ; 28 : 192 – 8 . https://doi.org/10.1016/j.fm.2010.03.020 .
Deshmukh MK , Deshmukh SS . System sizing for implementation of sustainable energy plan . Energy Educ Sci Technol 2006 ; 18 : 1 .
Manju S , Sagar N . Renewable energy integrated desalination: a sustainable solution to overcome future fresh-water scarcity in India . Renew Sust Energ Rev 2017 ; 73 : 594 – 609 .
Sharon HK , Reddy KS . A review of solar energy driven desalination technologies . Renew Sust Energ Rev 2015 ; 41 : 1080 – 118 .
Sonawane C , Alrubaie AJ , Panchal H . et al. Investigation on the impact of different absorber materials in solar still using CFD simulation—economic and environmental analysis . Water 2022 ; 14 : 3031 .
Ambade AS , Narekar BT , Katekar CV . 2009 . Performance evaluation of combined batch type solar water heater cum regenerative solar still. In 2009 Second International Conference on Emerging Trends in Engineering & Technology . IEEE . 1064 – 7 .
Google Preview
Peng G , Sharshir SW , Wang Y . et al. Potential and challenges of improving solar still by micro/nano-particles and porous materials-a review . J Clean Prod 2021 ; 311 : 127432 .
Kumar S , Dubey A , Tiwari GN . A solar still augmented with an evacuated tube collector in forced mode . Desalination 2014 ; 347 : 15 – 24 .
Isah AS , Takaijudin H , Singh BS . Principles and modes of distillation in desalination process . Distillation Process 2022 ; 5 : 3 .
Nehar L , Rahman T , Tuly SS . et al. Thermal performance analysis of a solar still with different absorber plates and external copper condenser . Groundw Sustain Dev 2022 ; 17 : 100763 .
Manokar AM , Murugavel KK , Esakkimuthu G . Different parameters affecting the rate of evaporation and condensation on passive solar still–a review . Renew Sust Energ Rev 2014 ; 38 : 309 – 22 .
Katekar VP , Deshmukh SS . A review on research trends in solar still designs for domestic and industrial applications . J Clean Prod 2020 ; 257 : 120544 .
Alqsair UF , Abdullah AS , El-Shafay AS . et al. Optimization and numerical study of the effect of using nanodiamond and nickel nanoparticles in solar desalination using two-phase mixture method and VOF . Eng Anal Bound Elem 2023 ; 155 : 432 – 9 .
Hammoodi KA , Dhahad HA , Alawee WH . et al. A detailed review of the factors impacting pyramid type solar still performance . Alex Eng J 2023 ; 66 : 123 – 54 .
Ramteke RJ , Dhurwey AR , Borkar HB . et al. Recent trends in solar distillation. International journal for research in applied science and engineering . Technology 2016 ; 4 : 184 – 92 .
Sivakumar V , Sundaram EG . Improvement techniques of solar still efficiency: a review . Renew Sust Energ Rev 2013 ; 28 : 246 – 64 .
Kumar PM , Mylsamy K . A comprehensive study on thermal storage characteristics of nano-CeO2 embedded phase change material and its influence on the performance of evacuated tube solar water heater . Renew Energy 2020 ; 162 : 662 – 76 .
Zhang X , You S , Xu W . et al. Experimental investigation of the higher coefficient of thermal performance for water-in-glass evacuated tube solar water heaters in China . Energy Convers Manag 2014 ; 78 : 386 – 92 .
García-Rodríguez L , Delgado-Torres AM . Renewable energy-driven desalination: new trends and future prospects of small capacity systems . Processes 2022 ; 10 : 745 .
Manchanda H , Kumar M . A comprehensive decade review and analysis on designs and performance parameters of passive solar still . Ren Wind Water Sol 2015 ; 2 : 1 – 24 .
Panchal H , Hishan SS , Rahim R . et al. Solar still with evacuated tubes and calcium stones to enhance the yield: an experimental investigation . Process Saf Environ Prot 2020 ; 142 : 150 – 5 .
Essa FA , Omara ZM , Abdullah AS . et al. Wall-suspended trays inside stepped distiller with Al2O3/paraffin wax mixture and vapor suction: experimental implementation . J Energy Storage 2020 ; 32 : 102008 .
Mevada D , Panchal H , kumar Sadasivuni K . et al. Effect of fin configuration parameters on performance of solar still: a review . Groundw Sustain Dev 2020 ; 10 : 100289 .
Thakkar H , Sankhala A , Ramana PV . et al. A detailed review on solar desalination techniques . Int J Ambient Energy 2020 ; 41 : 1066 – 87 .
Alaudeen A , Johnson K , Ganasundar P . et al. Study on stepped type basin in a solar still . J King Saud Univ-Eng Sci 2014 ; 26 : 176 – 83 .
Panchal H , Sathyamurthy R . Experimental analysis of single-basin solar still with porous fins . Int J Ambient Energy 2020 ; 41 : 563 – 9 .
Alaian WM , Elnegiry EA , Hamed AM . Experimental investigation on the performance of solar still augmented with pin-finned wick . Desalination 2016 ; 379 : 10 – 5 .
Velmurugan V , Gopalakrishnan M , Raghu R . et al. Single basin solar still with fin for enhancing productivity . Energy Convers Manag 2008 ; 49 : 2602 – 8 .
Rufuss DD , Iniyan S , Suganthi L . et al. Analysis of solar still with nanoparticle incorporated phase change material for solar desalination application. In: ISES Solar World Congress 2015, Conference Proceedings , November 2015 , 1271 – 80 .
Hailu G . 2018 . Seasonal solar thermal energy storage. In Thermal energy battery with nano-enhanced PCM . IntechOpen .
Khatod KJ , Katekar VP , Deshmukh SS . An evaluation for the optimal sensible heat storage material for maximizing solar still productivity: a state-of-the-art review . J Energy Storage 2022 ; 50 : 104622 .
Mugisidi D , Fajar B , Utomo T . 2019 . The effect of water surface level in sensible heat material on yield of Single Basin solar still: experimental study. In Journal of Physics: Conference Series , Vol. 1373, No. 1, p. 012014. IOP Publishing .
Balaji R , Aravindh V , Baburangan J . et al. Performance analysis of single slope solar still using sensible heat storage material . Appl Innov Res 2019 ; 1 : 120 – 7 .
Tiwari D , Rai DA . Effect of sensible energy storage medium on the productivity of solar still . Int J Mech Eng Technol 2016 ; 7 : 1 – 7 .
Elashmawy M . Improving the performance of a parabolic concentrator solar tracking-tubular solar still (PCST-TSS) using gravel as a sensible heat storage material . Desalination 2020 ; 473 : 114182 .
Ravichandran L , Rusovs D , Arjunan TV . et al. 2017 . Experimental study of brackish water distillation in single slope solar still using sensible heat storage materials. In International scientific conference rural development . Volume 201 pp. 391 – 6
Dumka P , Mishra DR . Performance evaluation of single slope solar still augmented with the ultrasonic fogger . Energy 2020 ; 190 : 116398 .
Panchal H , Patel DK , Patel P . Theoretical and experimental performance analysis of sandstones and marble pieces as thermal energy storage materials inside solar stills . Int J Ambient Energy 2018 ; 39 : 221 – 9 .
Attia ME , Driss Z , Kabeel AE . et al. Phosphate bags as energy storage materials for enhancement of solar still performance . Environ Sci Pollut Res 2021 ; 28 : 21540 – 52 .
Jamil B , Akhtar N . Effect of specific height on the performance of a single slope solar still: an experimental study . Desalination 2017 ; 414 : 73 – 88 .
Gugulothu R , Somanchi NS , Devi RS . et al. Experimental study of solar still with energy storage material . J Sustain Manuf Renew Energy 2014 ; 3 : 121 .
Bhalavi J , Saini R . Performance enhancement of solar still using energy storage material . Int J Curr Eng Technol 2018 ; 8 : 1047 – 51 .
Shamshirgaran SR , Khalaji Assadi M , Viswanatha SK . Application of nanomaterials in solar thermal energy storage . Heat Mass Transf 2018 ; 54 : 1555 – 77 .
Said Z , Pandey AK , Tiwari AK . et al. Nano-enhanced phase change materials: fundamentals and applications . Prog Energy Combust Sci 2024 ; 104 : 101162 .
Mousa H , Naser J , Gujarathi AM . et al. Experimental study and analysis of solar still desalination using phase change materials . J Energy Storage 2019 ; 26 : 100959 .
Safaei MR , Goshayeshi HR , Chaer I . Solar still efficiency enhancement by using graphene oxide/paraffin nano-PCM . Energies 2019 ; 12 : 2002 .
Rufuss DD , Iniyan S , Suganthi L . et al. Solar stills: a comprehensive review of designs, performance and material advances . Renew Sust Energ Rev 2016 ; 63 : 464 – 96 .
Rahul P , Ramanathan S , Dhivagar R . et al. A review on solar desalination techniques using vacuum technology . Proc Inst Mech Eng C J Mech Eng Sci 2023 ; 237 : 3086 – 102 .
Panchal H , Kumar Sadasivuni K , Suresh M . et al. Performance analysis of evacuated tubes coupled solar still with double basin solar still and solid fins . Int J Ambient Energy 2020 ; 41 : 1031 – 7 .
Elsheikh AH , Panchal H , Ahmadein M . et al. Productivity forecasting of solar distiller integrated with evacuated tubes and external condenser using artificial intelligence model and moth-flame optimizer . Case Stud Therm Eng 2021 ; 28 : 101671 .
Kabeel AE , Omara ZM , Essa FA . Numerical investigation of modified solar still using nanofluids and external condenser . J Taiwan Inst Chem Eng 2017 ; 75 : 77 – 86 .
Saleh TA . Nanomaterials: classification, properties, and environmental toxicities . Environ Technol Innov 2020 ; 20 : 101067 .
Ali AR , Salam B . A review on nanofluid: preparation, stability, thermophysical properties, heat transfer characteristics and application . SN Appl Sci 2020 ; 10 : 1636 .
Elango T , Kannan A , Murugavel KK . Performance study on single basin single slope solar still with different water nanofluids . Desalination 2015 ; 360 : 45 – 51 .
Tanaka H . Experimental study of a basin type solar still with internal and external reflectors in winter . Desalination 2009 ; 249 : 130 – 4 .
Singh SK , Bhatnagar VP , Tiwari GN . Design parameters for concentrator assisted solar distillation system . Energy Convers Manag 1996 ; 37 : 247 – 52 .
Angappan G , Pandiaraj S , Panchal H . et al. An extensive review of performance enhancement techniques for pyramid solar still for solar thermal applications . Desalination 2022 ; 532 : 115692 .
Yadav S , Sudhakar K . Different domestic designs of solar stills: a review . Renew Sust Energ Rev 2015 ; 47 : 718 – 31 .
Kabeel AE , El-Maghlany WM , Abdelgaied M . et al. Performance enhancement of pyramid-shaped solar stills using hollow circular fins and phase change materials . J Energy Storage 2020 ; 31 : 101610 .
Mahian O , Kianifar A . Mathematical modelling and experimental study of a solar distillation system . Proc Inst Mech Eng C J Mech Eng Sci 2011 ; 225 : 1203 – 12 .
Kianifar A , Heris SZ , Mahian O . Exergy and economic analysis of a pyramid-shaped solar water purification system: active and passive cases . Energy 2012 ; 38 : 31 – 6 .
Taamneh Y , Taamneh MM . Performance of pyramid-shaped solar still: experimental study . Desalination 2012 ; 291 : 65 – 8 .
Kabeel AE , Abdelgaied M , Almulla N . 2016 . Performances of pyramid-shaped solar still with different glass cover angles: experimental study. In 2016 7th International Renewable Energy Congress (IREC) . (pp. 1-6). IEEE.
Alawee WH , Mohammed SA , Dhahad HA . et al. Improving the performance of pyramid solar still using rotating four cylinders and three electric heaters . Process Saf Environ Prot 2021 ; 148 : 950 – 8 .
Beik AJ , Assari MR , Tabrizi HB . Passive and active performance of a multi-side-stepped square pyramid solar still; experimental and modeling . J Energy Storage 2020 ; 32 : 101832 .
Sharshir SW , Kandeal AW , Ismail M . et al. Augmentation of a pyramid solar still performance using evacuated tubes and nanofluid: experimental approach . Appl Therm Eng 2019 ; 160 : 113997 .
Essa FA , Alawee WH , Abdullah AS . et al. Achieving better thermo-enviro-economic performances of modified cords pyramid distiller with various arrangements of baffles, reflectors, and vapor extraction . J Therm Anal Calorim 2023 ; 148 : 13895 – 912 .
Essa FA , Alawee WH , Mohammed SA . et al. Improving the pyramid solar distiller performance by using pyramidal absorber, mirrors, condenser, and thermal storing material . Case Stud Therm Eng 2022 ; 40 : 102515 .
Kabeel AE . Performance of solar still with a concave wick evaporation surface . Energy 2009 ; 34 : 1504 – 9 .
Saravanan A , Murugan M . Performance evaluation of square pyramid solar still with various vertical wick materials–an experimental approach . Therm Sci Eng Prog 2020 ; 19 : 100581 .
Prakash A , Jayprakash R , Kumar S . Experimental analysis of pyramid wick-type solar still . Int J Sci Eng Res 2016 ; 7 : 1797 – 804 .
Sathyamurthy R , Nagarajan PK , Kennady H . et al. Enhancing the heat transfer of triangular pyramid solar still using phase change material as storage material . Front Heat Mass Transfer 2014 ; 5 : 1 – 5 .
Kabeel AE , Abdelgaied M . Enhancement of pyramid-shaped solar stills performance using a high thermal conductivity absorber plate and cooling the glass cover . Renew Energy 2020 ; 146 : 769 – 75 .
Hamdan MA , Musa AM , Jubran BA . Performance of solar still under Jordanian climate . Energy Convers Manag 1999 ; 40 : 495 – 503 .
Kabeel AE , Teamah MA , Abdelgaied M . et al. Modified pyramid solar still with v-corrugated absorber plate and PCM as a thermal storage medium . J Clean Prod 2017 ; 161 : 881 – 7 .
Kabeel AE , Hamed MH , Omara ZM . Augmentation of the basin type solar still using photovoltaic powered turbulence system . Desalin Water Treat 2012 ; 48 : 182 – 90 .
Senthil Rajan A , Raja K , Marimuthu P . Increasing the productivity of pyramid solar still augmented with biomass heat source and analytical validation using RSM . Desalin Water Treat 2016 ; 57 : 4406 – 19 .
Manokar AM , Taamneh Y , Winston DP . et al. Effect of water depth and insulation on the productivity of an acrylic pyramid solar still–an experimental study . Groundw Sustain Dev 2020 ; 10 : 100319 .
Abdel-Rehim ZS , Lasheen A . Improving the performance of solar desalination systems . Renew Energy 2005 ; 30 : 1955 – 71 .
Farouk WM , Abdullah AS , Mohammed SA . et al. Modeling and optimization of working conditions of pyramid solar still with different nanoparticles using response surface methodology . Case Stud Therm Eng 2022 ; 33 : 101984 .
Email alerts
Citing articles via, affiliations.
- Online ISSN 1748-1325
- Print ISSN 1748-1317
- Copyright © 2024 Oxford University Press
- About Oxford Academic
- Publish journals with us
- University press partners
- What we publish
- New features
- Open access
- Institutional account management
- Rights and permissions
- Get help with access
- Accessibility
- Advertising
- Media enquiries
- Oxford University Press
- Oxford Languages
- University of Oxford
Oxford University Press is a department of the University of Oxford. It furthers the University's objective of excellence in research, scholarship, and education by publishing worldwide
- Copyright © 2024 Oxford University Press
- Cookie settings
- Cookie policy
- Privacy policy
- Legal notice
This Feature Is Available To Subscribers Only
Sign In or Create an Account
This PDF is available to Subscribers Only
For full access to this pdf, sign in to an existing account, or purchase an annual subscription.
Scientists Discover Surprising New Role of Tau Protein: Promoting Healthy Aging in the Brain

A study reveals that Tau protein, typically linked to neurodegenerative diseases, also protects the brain by helping manage toxic lipids in glial cells, suggesting potential new treatments for these disorders.
Researchers at Baylor College of Medicine and the Jan and Dan Duncan Neurological Research Institute (Duncan NRI) at Texas Children’s Hospital have discovered that the protein Tau, commonly associated with neurodegenerative diseases like Alzheimer’s , also has beneficial effects in the brain. According to their study published in Nature Neuroscience , Tau helps protect neurons from damage caused by excessive reactive oxygen species (ROS), also known as free radicals, and supports healthy aging.
“ROS are natural byproducts of various cellular functions in the body. While low levels of ROS are beneficial, excess ROS is harmful to cells as it triggers the production of toxic forms of other molecules that induce oxidative stress, including peroxidated lipids,” said lead author Dr. Lindsey Goodman, a postdoctoral fellow in the lab of Dr. Hugo Bellen. “Neurons are particularly susceptible to oxidative stress and are destroyed if peroxidated lipid levels are not tightly controlled.”
Lipid droplets protect the brain from oxidative damage
There is mounting evidence supporting the notion that our brains have developed multiple neuroprotective strategies to combat ROS-induced oxidative damage.
One of the strategies, discovered in 2015 by the Bellen team, consists of neurons exporting these toxic peroxidated lipids to neighboring glial cells, which sequester them into lipid droplets for storage and future energy production. “This process effectively removes and neutralizes these toxic lipids,” Goodman said. “In the current study, we investigated the role of Tau in the formation of glial lipid droplets.”
The team found that endogenous normal Tau in flies is required for glial lipid droplet formation and for protecting against neuronal ROS. Similarly, Tau was required in glial cells obtained from rats and humans to form lipid droplets.
And while expression of normal human Tau was sufficient to restore the process of formation and maturation of glial lipid droplets in flies lacking their own Tau, when this human Tau protein carried disease-causing mutations – which are linked to an increased risk for Alzheimer’s disease – the glia were incapable of forming lipid droplets in response to neuronal ROS.
“This argues that mutations in Tau may reduce the protein’s normal ability to prevent oxidative stress in addition to causing the protein to accumulate into the typical hallmarks of disease, as described by previous work,” said Goodman. “Altogether, the findings support a new neuroprotective role for Tau against the toxicity associated with ROS.”
Further connections with the disease were discovered using established fly and rat models of Tau-mediated conditions that overexpress disease-causing human Tau protein in glia. In these scenarios, the investigators again saw defects in glial lipid droplets and glial cell demise in response to neuronal ROS. This demonstrated that Tau is a dosage-sensitive regulator of glial lipid droplets where too much or too little Tau is detrimental.
“By revealing a surprising new neuroprotective role for Tau, the study opens the door to potential new strategies to slow, reverse, and treat neurodegenerative conditions,” said Bellen, corresponding author of the work. He is a distinguished service professor in molecular biology and genetics at Baylor and holds a Chair in Neurogenetics at Duncan NRI. Bellen also is a March of Dimes Professor in Developmental Biology at Baylor.
In summary, contrary to its usual ‘bad guy’ role in neurodegenerative disease, this study demonstrates that Tau also plays a ‘good guy’ role in glia by helping sequester toxic lipids, reducing oxidative damage and, hence protecting our brains. However, when Tau is absent or when defective Tau proteins are present, this protective effect disappears, leading to disease.
Reference: “Tau is required for glial lipid droplet formation and resistance to neuronal oxidative stress” by Lindsey D. Goodman, Isha Ralhan, Xin Li, Shenzhao Lu, Matthew J. Moulton, Ye-Jin Park, Pinghan Zhao, Oguz Kanca, Ziyaneh S. Ghaderpour Taleghani, Julie Jacquemyn, Joshua M. Shulman, Kanae Ando, Kai Sun, Maria S. Ioannou and Hugo J. Bellen, 26 August 2024, Nature Neuroscience . DOI: 10.1038/s41593-024-01740-1
This work was supported by several grants from the National Institutes of Health , the Canadian Institutes of Health and Research Doctoral Award, Sloan Research Fellowship from the Alfred P. Sloan Foundation, Canada Research Chairs program, a CIHR project grant, and a Grant-in-Aid for Scientific Research on Challenging Research (Exploratory).
Related Articles
Mushrooming mystery: how fungal infections echo alzheimer’s disease in the brain, identifying “the terrorist inside my husband’s brain” – living brain imaging can clearly differentiate between types of dementia, neuroscientists discover promising way to restore cognitive function impaired by alzheimer’s disease, century of data shows covid-19 likely to impact the brain long-term, treating neurodegenerative diseases from glaucoma to alzheimer’s: new discovery on how to protect neurons and encourage their growth, long before alzheimer’s symptoms, plaque emerges deep in the brain [video], common nutrient supplement may prevent alzheimer’s disease, test for alzheimer’s may be undermining drug trials, disrupted sleep patterns linked to alzheimer’s.
Save my name, email, and website in this browser for the next time I comment.
Type above and press Enter to search. Press Esc to cancel.
IMAGES
VIDEO
COMMENTS
These approaches addressed the problem of research articles classification 4,8. Every research paper is classified into one or more categories. The issue of mapping research articles with ...
Research Paper Classification using Supervised Machine Learning Techniques. October 2020. DOI: 10.1109/IETC47856.2020.9249211. Conference: 2020 Intermountain Engineering, Technology and Computing ...
The Journal of Classification congratulates Michael Pearce, University of Washington, on winning the 2024 Classification Society Distinguished Dissertation Award. Dr. Pearce´s dissertation is entitled "Methods for the Statistical Analysis of Preferences, with Applications to Social Science Data".
Thus, GBT has demonstrated its capability in efficiently categorizing research paper abstracts, proving its robustness and efficiency as a classification technique. The model introduced in this study presents a mechanism for the automated extraction and categorization of research paper abstracts, aligning them with their respective categories.
Classification Techniques in Machine Learning: Applications and. Issues. Aized Amin Soofi * and Arshad Awan. Department of Computer Science, All ama Iqbal Open University, Islamabad, P akistan ...
In this work, different Machine Learning (ML) techniques are used and evaluated based on their performance of classifying peer reviewed published content. The ultimate objective is to extract meaningful information from published abstracts. In pursuing this objective, the ML techniques are utilized to classify different publications into three fields: Science, Business, and Social Science. The ...
In , Hanyurwimfura et al. proposed the paper classification method based on research paper's title and common terms. In , Nanbo et al. proposed the paper classification method that extracts keywords from research objectives and background and that groups papers on the basis of the extracted keywords. In these works, the results achieved on ...
In this paper, we provide a comprehensive review of more than 150 deep learning based models for text classification developed in recent years, and discuss their technical contributions, similarities, and strengths. We also provide a summary of more than 40 popular datasets widely used for text classification.
This paper shows the automatic classification of research papers published in Scopus. Our classification is based on the research lines of the university. We apply the K-nearest neighbor classifier and linear discriminant analysis (LDA). Various stages were used from...
in literature, the research community's focus shi˙ed to research paper classi˜cation. e proposed approaches in the literature that are currently state-of-the-art can be classied into two major ...
E-mail: [email protected] , 2 [email protected], [email protected]. ABSTRACT. The methods used for Classification, Recognition, Diagn osis or Clustering with details ...
Text Classification (TC), also known as Document Classification or Text Categorization, is the process of assigning several predefined categories to a set of texts, often based on its content (Jindal et al., 2015; Wang & Deng, 2017). With the advent of the era of big data, the enormous quantity and diversity of digital documents have made it ...
With the advances in information technologies, different research areas are emerging day by day and thousands of research papers are published in these fields. Papers are not presented to users grouped according to their topics. Therefore, it is getting harder and harder for people to access research papers in their field of interest. To facilitate this search process, a paper classification ...
In this paper, we compare the performance of two popular NLP models, pre-train fine-tuned BERT and BiLSTM with combined CNN, in terms of the classification and recommendation tasks of research papers. We conduct the performance evaluation of these two models with research journal benchmark dataset. Performance results show that the pre-train fine-tuned BERT model is superior to CNN-BiLSTM ...
A defining aspect of classification systems, particularly those used in research evaluation, is the level of aggregation of the classification, such as at the journal or the article level, or at the conference or the presentation level. The classification of scientific work at the journal and article levels has been extensively studied [9-12 ...
Classification Algorithms This section offers a concise explanation of all of the classification algorithms used in the proposed work. 3.1. Naive Bayesian The Bayes' Theorem is used to generate naive Bayes classifiers, which are a group of classification methods. It consists of a number of algorithms which all work on the same principle: each ...
At this time, the traditional single-label text classification is not conducive to people obtaining comprehensive and cutting-edge research papers in real life. Thus, it's of great importance to conduct a multi-label classification of research papers effectively. This paper tests the performance of multi-label learning tasks with text data ...
The classification of scientific literature into appropriate disciplines is an essential precondition of valid scientometric analysis and significant to the practice of research assessment. In this paper, we compared the classification of publications in Nature based on three different approaches across three different systems. These were: Web of Science (WoS) subject categories (SCs) provided ...
The classification performance of "Geology" after merging has improved from 0.83 to 0.88. 7.3 Limitations. Compared with existing work, our models are trained on a relatively comprehensive, large-scale, and clean dataset from WoS. However, the basic classification of WoS is at the journal level and not at the article level.
the paper classification system based on term fre quency-inverse document frequenc y. (TF-IDF) [ 2 - 4] and Latent Dirichlet allocation (LDA) [ 5] schemes. e proposed sys. tem firstly ...
To classify images based on their content is one of the most studied topics in the field of computer vision. Nowadays, this problem can be addressed using modern techniques such as Convolutional Neural Networks (CNN), but over the years different classical methods have been developed. In this report, we implement an image classifier using both classic computer vision and deep learning ...
Experimental research paper. This type of research paper basically describes a particular experiment in detail. It is common in fields like: biology. chemistry. physics. Experiments are aimed to explain a certain outcome or phenomenon with certain actions. You need to describe your experiment with supporting data and then analyze it sufficiently.
Seventy-three text classification research articles posted from January 2016 until July 2021 were retained and chosen to be explored further based on the established inclusion and exclusion criteria. This literature review was conducted in a methodical manner. A systematic literature review is defined as a method for recognizing, evaluating ...
Types of entry points. finding the previous research inadequate or nonexistent and filling the gap; finding it sound and supporting it or extending it; finding it unsound and correcting it; Entry Point Type 1: Addressing a Gap in Previous Research.
Solar stills are commonly categorized into two main types: passive and active solar stills . Passive solar stills are known for their straightforward operation, ease of construction, compactness, and cost-effectiveness. They operate solely on sunlight and do not require any external energy source. However, their productivity is relatively lower ...
A study reveals that Tau protein, typically linked to neurodegenerative diseases, also protects the brain by helping manage toxic lipids in glial cells, suggesting potential new treatments for these disorders. Researchers at Baylor College of Medicine and the Jan and Dan Duncan Neurological Researc
Objectives/background: The infectious consequences of microorganisms are varied due to resistance to existing antimicrobial drugs or new types of microbes causing lethal consequences for humans. Investigation are being performed to control different viral diseases; therefore; medicinal and herbal plants which have a variety of biological properties, can be evaluated for their anti-viral potential.