- IEEE Brain Career Center
- IEEE Brain Community
Podcasts Listen to industry and research specialists discuss cutting-edge neurotechnology and associated career paths.
Webinars Learn from top subject matter experts in brain research and neurotechnology.
eLearning Modules Dive deep with subject experts into key brain-related topic areas.
Video Series Access conversations with the industry's best of the best.
Presentations Discover more about the future of neurotechnology.
BrainInsight Featuring news and forward-looking commentary on neurotechnology research.
IEEE Neuroethics Framework Examining the ethical, legal, social, and cultural issues that arise with development and use of neurotechnologies.
IEEE Brain Talks Highlighting Q&As with brain experts and industry leaders.
Research & White Papers Identifying key challenges and advances required to successfully develop next generation neurotechnologies.
Brain Topics Learn more about the brain and neurotechnology research.
Standards Consider guidelines for neurotechnology development and use.
TED Talks Explore ground-breaking ideas in brain and neurotechnology development.
Career Center Find information on brain-related careers.
In by Adriel Carridice September 10, 2024

The 2025 IEEE International Symposium on Biomedical Imaging (ISBI) Call for Papers is now open! ISBI 2025 will be held in Houston, Texas, United States, from 14-17 April 2024.
This vibrant setting provides unparalleled opportunities to bridge the gap between cutting-edge biomedical imaging technologies and frontline clinicians, ultimately enhancing patient care.
ISBI 2025 is a scientific conference dedicated to the mathematical, algorithmic, and computational aspects of biological and biomedical imaging, across all scales of observation. It fosters knowledge transfer among different imaging communities, including technological, clinical and industrial communities, and contributes to an integrative approach to biomedical imaging.
| . To encourage attendance by a broader audience of imaging scientists and clinical professionals, ISBI 2024 will continue to have a second track featuring posters selected from 1-page abstract submissions without subsequent archival publication. 1-page abstracts will not be published in IEEE . High-quality papers are solicited containing original contributions in the topics of interest.
Submit your paper by 11 October 2024 to be considered. Learn more about the submission requirements and guidelines . |
To register for this event please visit the following URL: https://biomedicalimaging.org/2025/ →

Date And Time
Event types, event category, share with friends.

Over the last decade, the field of neuroscience has seen great advancements. Multiple efforts, both public and private, are underway to develop new tools to deepen our understanding of the brain and to create novel technologies that can record, decode, and sense brain signals as well as stimulate, modify, and augment brain function with improved efficacy and safety.
Although current research into and early deployment of neurotechnologies has predominantly focused on medical and therapeutic uses, there are already examples pointing to the push for the commercialization of these technologies for other applications, such as wellness, education, or gaming. As part of our effort to support the neuroengineering community, the IEEE Brain Neuroethics Subcommittee is developing a neuroethical framework for evaluating the ethical, legal, social, and cultural issues that may arise with the deployment of such neurotechnologies. The IEEE Brain neuroethical framework is organized as a matrix of specific types of contemporary neurotechnologies and their current and potential applications.
In this framework, we explore the ethical, legal, social, and cultural issues (ELSCI) that are generated by different types of neurotechnologies when used in specific applications. Key areas identified for potential neurotechnology implementation include medicine, wellness, education, work and employment, military and national security, sports and competitions, entertainment, the legal system, as well as marketing and advertising.
We recognize that neurotechnologies are constantly changing, both in terms of the translational pathway and the scope of applications for which they are used. A given neurotechnology might not flourish for a given application but may be used in ways not originally intended. Similarly, the ELSCI of a given device might change based on the particular social context and culture at hand. Accordingly, this framework is intended to serve as a living document, such that the themes and principles only capture a particular moment in time and will need to be revised as neuroscience, neurotechnologies, and their uses evolve. Furthermore, it is intended to facilitate further discussion by inviting input and new perspectives from a wide range of individuals with an interest in neurotechnologies.
While the focus is primarily on current technologies, we discuss potential risks and benefits of technologies for which only limited data is available. Our hope is for the proliferation of research in this field, and we look forward to issuing supplementary resources. Finally, while we acknowledge that there are different ways in which neurotechnologies can be conceptualized, here we focus on neurotechnologies as devices or physical modifications that interface with the human body, supplement pharmaceutical interventions, or that integrate with pharmaceutical agents. We focus on those interventions that use electricity, magnetic pulses, light, or other non-pharmacological agents to bring about their goal. In some cases, these techniques may incorporate genetic modification to the target tissue; however, pure gene therapies that do not involve an associated electronic device are outside the scope of this document.
Each application begins by defining the use case. Next, it identifies and describes existing key examples of the use of neurotechnology in the relevant application area as well as both near-term and long-term applications and the technologies that will enable them. After examining the ethical, legal, social, and cultural considerations for neurotechnologies in that given application, we highlight some examples of regulatory considerations, relevant standards, and a few case studies.
The documentation that supports this framework is the result of ongoing collaboration and dialogue among teams of engineers, scientists, clinicians, ethicists, sociologists, lawyers, and other stakeholders. This document has set the foundation for the ongoing development of socio-technical standards with a focus on neurotechnology (IEEE SA P7700) for engineers, researchers, applied scientists, practitioners, and neurotechnology companies that will help ensure the responsible development and use of new neurotechnologies. This framework will also be of interest to a wide range of audiences and stakeholders interested in neuroethics and the ethical, legal, social, and cultural implications (ELSCI) of these emerging technologies.
IEEE TRANSACTIONS ON MEDICAL IMAGING (TMI) encourages the submission of manuscripts on imaging of body structure, morphology and function, including cell and molecular imaging and all forms of microscopy. The journal publishes original contributions on medical imaging achieved by modalities including ultrasound, x-rays, magnetic resonance, radionuclides, microwaves, and optical methods. Contributions describing novel acquisition techniques, medical image processing and analysis, visualization and performance, pattern recognition, machine learning, and related methods are encouraged. Studies involving highly technical perspectives are most welcome.
The focus of the journal is on unifying the sciences of medicine, biology, and imaging. It emphasizes the common ground where instrumentation, hardware, software, mathematics, physics, biology, and medicine interact through new analysis methods. Strong application papers that describe novel methods are particularly encouraged. Papers describing important applications based on medically adopted and/or established methods without significant innovation in methodology will be directed to other journals.
A Publication of
Sponsor societies:.

Home / Publications / IEEE Photonics Journal
IEEE Photonics Journal
The society’s open access journal providing rapid publication of top-quality peer-reviewed papers at the forefront of photonics research..

IEEE Photonics Journal is an online-only rapid publication archival journal of top quality research at the forefront of photonics. Photonics integrates quantum electronics and optics to accelerate progress in the generation of novel photon sources and in their utilization in emerging applications at the micro and nano scales spanning from the far-infrared/THz to the x-ray region of the electromagnetic spectrum.
Time to Publication
Impact Factor
What's Popular
- Reconfigurable Integrated Photonic Unitary Neural Networks With Phase Encoding Enabled by In-Situ Training Source: IEEE Photonics Journal - popular articles Published on 2024-09-03
- High-Quality and Enhanced-Resolution Single-Pixel Imaging Based on Spiral Line Array Laser Source Source: IEEE Photonics Journal - popular articles Published on 2024-08-30
- Experimental Investigation of Si/SnOx Heterojunction for Its Tunable Optoelectronic Properties Source: IEEE Photonics Journal - popular articles Published on 2024-08-30
- Design and Demonstration of MOCVD-Grown p-Type AlxGa1-xN/GaN Quantum Well Infrared Photodetector Source: IEEE Photonics Journal - popular articles Published on 2024-08-29
- Design and Optimization of InAs Waveguide- Integrated Photodetectors on Silicon via Heteroepitaxial Integration for Mid- Infrared Silicon Photonics Source: IEEE Photonics Journal - popular articles Published on 2024-08-27
See all articles for this month >
OPEN CALLS FOR PAPERS
Information on current calls for papers for IEEE Photonics Society journals.
SPECIAL ISSUES
Further information on selected and published IEEE Photonics Society special issues.
Description
Technical areas, information for authors, editorial board, publication office, open access.
IEEE Photonics Journal is an open access, online-only rapid publication archival journal of top-quality research at the forefront of photonics. Contributions addressing issues ranging from fundamental understanding to emerging technologies and applications are within the scope of the Journal.
IEEE Photonics Journal is published online only. This platform offers capabilities to enhance published articles; all articles are published in color. Authors have the opportunity to submit supplemental material which may include but is not limited to: multimedia presentations, simulations, webinars, etc. Authors can also store their data in IEEE DataPort, and receive a DOI for their dataset https://ieee-dataport.org . In their final form, all articles contain a cover page with a “Graphic Abstract.”
The journal offers a thorough review process that is a signature of IEEE Publications. Upon acceptance papers receive a Digital Object Identifier and are published in the Early Access section on IEEE Xplore https://ieeexplore.ieee.org/ . At this stage, papers are fully citable. The final published version of the papers is copy edited by IEEE to ensure higher production quality.
Breakthroughs in the generation of light and its control and utilization have given rise to the field of Photonics; a rapidly expanding area of science and technology with major technological and economic impacts. Photonics integrates quantum electronics and optics to accelerate progress in the generation of novel photon sources and in their utilization in emerging applications at the micro- and nano-scales spanning from the far-infrared/THz to the x-ray region of the electromagnetic spectrum.
We welcome original contributions addressing issues ranging from fundamental understanding to emerging technologies and applications:
- Photon sources from far infrared to x-rays
- Photonics materials and engineered photonic structures
- Integrated optics and optoelectronic
- Ultrafast, attosecond, high field and short wavelength photonics
- Biophotonics including DNA photonics
- Nano-photonics
- Magneto-photonics
- Fundamentals of light propagation and interaction; nonlinear effects
- Optical data storage
- Fiber optics and optical communications devices, systems, and technologies
- Solar Cells
- Micro Opto Electro Mechanical Systems (MOEMS)
- Microwave photonics
- Optical sensors
Area 1: Optical Networks and Systems, Senior Editor: Ben Puttnam, Junior Editor: Andrea Sgambelluri
Optical core, metro, access, and data center networks; fiber optics links; free-space communications; underwater communications; optical cryptography.
Area 2: Fiber Optics Devices and Subsystems, Senior Editor: Fan Zhang, Junior Editor: Yang Du
Optical sources, devices, and subsystems for fiber communications; multimode and multicore fibers; optical frequency combs; amplifiers; multiplexers; interconnects; modulators; switches.
Area 3: Light Sources , Senior Editor: Paul Crump, Junior Editor: Xin Wang
Lasers; coherent optical sources; LED; OLED; QLED; lightning; incoherent optical sources; semiconductor lasers; visual perception.
Area 4: Detection, Sensing, and Energy, Senior Editor: Young Min Song, Junior Editor: Zunaid Omair
Optical detectors; sensors; solar cells; display technology; photovoltaics; thermophotovoltaics; vision; colors; visual optics; environmental optics; photonics measurements; energy optics (solar concentrators, daylighting design, solar fuels); measurement for industrial inspection.
Area 5: Integrated Systems, Circuits and Devices: Design, Fabrication and Materials, Senior Editor: Sylwester Latkowski, Junior Editor,
Integrated photonics systems; waveguides; integrated photonic devices; ring resonators; filters; multiplexers; liquid crystals; photonics manufacturing.
Area 6: Plasmonics and Metamaterials , Senior Editor: Jacob Khurgin, Junior Editor: Haifeng Hu
Micro photonics; nanophotonics; metamaterials; plasmonics; mid-Infrared and THz photonics; acoustic metamaterials; optomechanics; 2D material plasmonics and metasurfaces; nanowires; quantum dots; micro and nanoantennas; photonic bandgap structures.
Area 7: Biophotonics and Medical Optics, Senior Editor: Qiyin Fang
Biomedical optics, spectroscopy and microscopy; diffuse tomography; tissue imaging; nanoscopy; optical coherent tomography; bioimaging; optical biophysics; photophysics; photochemistry; biosensors; optical manipulation and molecular probes, imaging and drug delivery; photonics and the brain.
Area 8: Computational Photonics, Senior Editor: Jose Azana, Junior Editor: Maria del Rosario Fernandez Ruiz
Fourier optics; statistical optics; coherence; signal and image processing; microwave photonics; electromagnetics; artificial vision; lidar; computational imaging; diffractive optics.
Area 9: Propagation, Imaging, and Spectroscopy, Senior Editor : Stefan Stanciu , Junior Editor: Roxana Totu
Microscopy (diffraction-limited and super-resolution techniques); spectroscopy (UV/VIS, infrared, THz); nanoscopy; adaptive optics; holography; scattering; diffraction; gratings; physical optics; diffuse optics; polarization, luminescence, fluorescence, vibrational, nonlinear, photoacoustic, plasmonic and multimodal imaging; image processing and analysis (restoration, classification, and augmentation); methods for inspection, characterization, and imaging; photonics for arts, architecture, and archaeology.
Area 10: Quantum Photonics, Senior Editor: Niels Gregersen, Junior Editor: Jun Liu
Quantum sources and detection; single-photon emission and detection; entanglement; integrated quantum optics; quantum cryptography; quantum computation; quantum simulation.
Area 11: Nonlinear Photonics and Novel Optical Phenomena, Senior Editor: Michelle Sander, Junior Editor: Huanyu Song
Nonlinear photonics and phenomena; Terahertz; ultrahigh field and ultrafast photonics; nonlinear pulse propagation and interaction; high power systems; X-rays and plasma; attosecond science; high precision metrology and frequency comb technology; magnetophotonics; acoustophotonics; photoacoustic effects .
Area: 12 Optical Data Science and Machine Intelligence in Photonics , Senior Editor: Salah Obayya, Junior Editor: Jingxi Li
Machine learning-based solutions to inverse problems in optics; machine learning for life sciences imaging and microscopy; inverse design; materials for optical neural networks; photonic reservoir computing; photonic hardware accelerators; co-design of photonic systems and downstream algorithms; machine learning for ultrafast optics, for photonic material discovery and for optical storage.
Starting July 2021, papers are published in the IEEE two-column format. A template is available to guide Authors in the preparation of the manuscript and in estimating the total number of pages. Click here for the IEEE Template Selector .
Manuscripts are submitted in *PDF or in Microsoft Word form for review, and in LaTex for later processing by IEEE publications. Authors can submit supplemental multimedia files, such as animation, movies, data sets, sound files, and other forms of enhanced, multi-media content. Authors are encouraged to use high-quality color graphics. In addition, Authors can store their data in IEEE DataPort https://ieee-dataport.org.
The Journal uses a ‘Graphic Abstract’ as the cover page, and Authors are required to submit one piece of artwork or identify a figure in the paper that best describes the results of their work.
The use of artificial intelligence (AI)–generated text in an article shall be disclosed in the acknowledgments section of any paper submitted to an IEEE Conference or Periodical. The sections of the paper that use AI-generated text shall have a citation to the AI system used to generate the text.
IEEE Tools for Authors offers a reference validation tool to check the format and completeness of references. Analyze your article’s LaTeX files prior to submission to avoid delays in publishing. The IEEE LaTeX Analyzer will identify potential setbacks such as incomplete files or different versions of LaTeX. The use of these tools simplifies the copy-editing process which in turn reflects into a faster time-to-publication.
English language editing services can help refine the language of your article and reduce the risk of rejection without review. IEEE Authors are eligible for discounts at several language editing services; visit IEEE Author Center to learn more. Please note these services are fee-based and do not guarantee acceptance.
All IEEE Journals require an Open Researcher and Contributor ID (ORCID) for all Authors. ORCID is a persistent unique identifier for researchers and functions similarly to an article’s Digital Object Identifier (DOI). ORCIDs enable accurate attribution and improved discoverability of an Author’s published work. Researchers can sign up for an ORCID for free via an easy registration process on orcid.org . Learn more at http://orcid.org/content/about-orcid or in a video at https://vimeo.com/97150912. Authors who do not have an ORCID in their ScholarOne user account will be prompted to provide one during submission.
Author submissions are done through the IEEE Author Portal. Click here to the IEEE Author Portal .
The login and password for IEEE Photonics Technology Letters, IEEE Journal of Quantum Electronics, IEEE Journal of Selected Topics in Quantum Electronics, IEEE/Optic Publishing Group Journal of Light Wave Technology, or IEEE Journal of Display Technologies will also work on the IEEE Photonics Journal IEEE Author Portal site.
Submissions are reviewed by the Editorial Office for completeness and language proficiency. Submissions that are deficient will be sent back to the Authors. Articles are screened for plagiarism before being sent for review.
During the submission process, Authors select one of the 12 Technical Areas that best identifies the subject of their paper, and the manuscript is assigned to the corresponding Senior Editor (SE).
Authors are encouraged to suggest an Associate Editor (AE) to handle the review process. The Editor in Chief (EiC) will consider this suggestion, however, he/she reserves the option to use other AEs based on their loads. The file of the AE’s names and their area of expertise is available in the IEEE Author Portal https://ieee.atyponrex.com/journal/pj-ieee in the ‘Instructions and Forms’ tab.
Upon submission, your manuscript will be checked for formal template compliance before the Senior Editor examines the paper for scope compliance, language proficiency, as well as basic technical content and novelty. Out-of-scope papers, as well as papers of insufficient technical content or quality, may be immediately rejected upon consultation within the Editorial Board. Additional information on the journal scope and topic categories can be found here https://ieeephotonics.org/publications/photonics-journal/ .
After passing these initial editorial steps, the Senior Editor assigns your manuscript to an Associate Editor who is an expert in the respective paper’s topic area. Authors also have the opportunity to suggest a preferred Associate Editor (or to exclude certain Associate Editors as “non-preferred”) upon submission. We will always honor non-preferred Associate Editor selections if these are based on clear precedence that could lead to a potentially biased review process. (The mere fact that an Associate Editor may also be a competitor working in the exact same field as your paper is not a reason for exclusion.) We will try to honor preferred Associate Editor choices, but only if your preferences make technical sense and if the current Associate Editor workload permits the assignment.
The Associate Editor selects a minimum of two reviewers who are experts in the field of your paper. Authors can track the status of their submission at any time through their Author Portal . Please note that all technical work performed in this paper handling process, including all work performed by the Editor-in-Chief, the Senior Editors, the Associate Editors, and the Reviewers, is based on volunteers. While we constantly strive to keep reviewing times to a minimum, we place strong emphasis on technical quality. The average turn-around time (from submission to decision) is currently about 77 days.
PJ allows for one revision cycle. Should your manuscript require more than one revision, it may be rejected, but you are encouraged to resubmit so you can fully address all reviewer concerns. Once accepted, your paper will be placed on-line in the queue for the journal within 2-3 days. At that point it can be fully referenced using the digital object identifier (DOI), even if it hasn’t yet appeared in a printed issue. The articles in this journal are peer reviewed in accordance with the requirements set forth in the IEEE Publication Services and Products Board Operations Manual ( https://pspb.ieee.org/images/files/files/opsmanual.pdf , section 8.2.2). Each published article is reviewed by a minimum of two independent reviewers using a single-anonymous process, where the identities of the reviewers are not known to the authors, but the reviewers know the identities of the authors. Articles will be screened for plagiarism before acceptance.
Appeals must be directed to the EiC, in the form of a letter that clearly explains the rationale for the appeal. The submitted documentation should also include a copy of the rejection letter and of the reviews. The IEEE appeal process calls for the establishment of an independent group of evaluators that will review the Authors’ rebuttal, the decision of the AE, and the Reviewers comments. The process takes on average 6-8 weeks. Once the EiC has reached a decision, it will be communicated to the authors by email.
Publishing within IEEE is governed by Principles of Scholarly publishing developed in 2007 and found at: http://www.ieee.org/web/publications/rights/PublishingPrinciples.html
IEEE Statement on the Appropriate use of Bibliometrics: https://www.ieee.org/publications/rights/bibliometrics-statement.html
IEEE Photonics Journal Editor-in-Chief
Senior editors.
Jose Azana, INRS-EMT, Canada
Paul Crump, Ferdinand-Braun Institute for Hoechstfrequenztechnik, Germany
Qiyin Fang, McMaster University, Canada
Niels Gregersen, Technical University of Denmark, Denmark
Jacob Khurgin, John Hopkins University, USA
Sylwester Latkowski, Eindhoven University of Technology, Netherlands
Salah Obayya, Zewail City of Science and Technology, Egypt
Benjamin Puttnam, Dokuritsu Gyosei Hojin Joho Tsushin Kenkyu Kiko, Japan
Michelle Y. Sander, Boston University, USA
Young Min Song, Gwangju Institute of Science & Technology, Korea
Stefan Stanciu, University of “Politehnica” of Bucharest, Romania
Fan Zhang, Peking University, China
Associate Editors
Nicola Andriolli, CNR IEIIT, Italy
Amir Arbabi, University of Massachusetts Amherst, USA
Marco Bellini, Istituto Nazionale di Ottica Consiglio Nazionale delle Ricerche, Italy
Francesco Bertazzi, Politecnico di Torino, Italy
Paolo Bianchini, Istituto Italiano di Tecnologia, Italy
Thomas Bocklitz, Leibniz Institute of Photonic Technology, Germany
Luigi Bonacina, Universite’ de Geneve, Switzerland
Ahmed Bukhamseen, Saudi Aramco, Saudi Arabia
Chi Wai Chow, National Yang Ming Chiao Tung University, Taiwan
Caterina Ciminelli, Politecnico di Bari, Italy
Giulio Cossu, Scuola Superiore Sant‘Anna, Italy
Fei Ding, University of Southern Denmark, Denmark
Lu Ding, Institute of Materials Research & Engineering, Singapore
Hery S. Djie, Lumentum LLC, USA
Dror Fixler, Bar Ilan University, Israel
Lan Fu, Australian National University, Australia
Songnian Fu, Guangdong University of Technology, China
Fei Gao, ShanghaiTech University, China
Haoshuo Chen, Nokia Bell Labs, USA
Hao Huang, Lumentum Operations LLC, USA
Satoshi Ishii, Busshitsu Zairyo Kenkyu Kiko Kokusai Nanoarchitectonics Kenkyu Kyoten, Japan
Zhensheng Jia, Cable Television Laboratories, USA
Antonio Jurado-Navas, University of Malaga, Spain
Mukesh Kumar, Indian Institute of Technology, India
Jiun-Haw Lee, National Taiwan University, Taiwan
Yan Li, Shanghai Jiao Tong University, China
Peter Liu, State University of NY at Buffalo, USA
Muhammad Qasim Mehmood, Information Technology University (ITU) of the Punjab, Lahore, Pakistan
MD. Jarez Miah, Bangladesh University of Engineering and Technology, Bangladesh
S.M.Abdur Razzak, Rajshahi University of Engineering & Technology, Bangladesh
Anurag Sharma, Indian Institute of Technology Delhi, India
Chao Shen, Fudan University, China
Lei Shi, Fudan University, China
Zachary Smith, University of Science and Technology of China, China
Jingbo Sun, Tsinghua University, China
Eduward Tangdiongga, Eindhoven University of Technology, The Netherlands
Alberto Tibaldi, IEIIT-CNR, Italy
Georgios Veronis, Louisiana State University, USA
Luca Vincetti, University of Modena and Reggio Emilia, Italy
Yating Wan, KAUST, Saudi Arabia
Shang Wang, Stevens Institute of Technology, USA
Hai Xiao, Clemson University, USA
Shumin Xiao, Harbin Institute of Technology, China
He-Xiu Xu, Air Force Engineering University, China
Yu Yao, Arizona State University, USA
Shu-Chi Yeh, University of Rochester Medical Center, USA
Changyuan Yu, Hong Kong Polytechnic University, Hong Kong
Alessandro Zavatta, Consiglio Nazionale delle Ricerche, Italy
Jinwei Zeng, Huazhong University of Science and Technology, China
Junwen Zhang, Fudan University, China
Lin Zhang, Tianjin University, China
Xiaobei Zhang, Shanghai University, China
Chao Zhou, Washington University in Saint Louis, USA
Xian Zhou, University of Science and Technology Beijing and Beijing, China
Xinxing Zhou, Hunan Normal University, China
Yeyu Zhu, Lumentum Operations LLC, USA
Junior Editors
Jing Du, Huazhong University of Science and Technology, China
Xin Wang, Southeast University, China
Zunaid Omair, Standford University, USA
Haifeng Hu, University of Shanghai for Science and Technology, China
Maria Fernandez-Ruiz, Universidad de Alala, Spain
Roxana Totu, University Politehnica of Bucharest, Romania
Jingxi Li, University of California Los Angeles, USA
Andrea Sgambelluri, Scuola Superiore Sant’Anna, Italy
Huanyu Song, SLAC National Accelerator Laboratory, USA
Yang Du, Leibniz Institute of Photonic Technology, Germany
Jun Liu, Huazhong University of Science and Technology
Publications Coordinator
Yvette Charles IEEE Photonics Society 445 Hoes Lane Piscataway, NJ 08854-1331, USA Phone: +1 732 981 3457 Email: [email protected]
Publications Portfolio Manager
Laura A. Lander IEEE Photonics Society 445 Hoes Lane Piscataway, New Jersey 08854, USA Phone: +1 732 465 6479 Email: [email protected]
Open Access Rights Management
Article processing charge (apc): us$1995.
IEEE Photonics Journal is a fully Open Access Journal, compliant with funder mandates, including Plan S.
For papers submitted in 2024, the APC is US$1995 plus applicable local taxes.
- IEEE Members receive a 5% discount.
- IEEE Society Members receive a 20% discount.
Discounts do not apply to undergraduate and graduate students. These discounts cannot be combined.
Photonics Journal has a waiver policy for authors from low-income countries. Corresponding authors from low-income countries (as classified by the World Bank) are eligible for a 100% waiver on APCs. Corresponding authors from lower-middle-income countries are also eligible for a discount on APCs ranging from 25% to 50% based on the GDP of the country of the corresponding author.
author center
Resources and tools to help you write, prepare, and share your research work more effectively.
open access
Special issue in IEEE Transactions on Medical Imaging: Advancements in Foundation Models for Medical Imaging
- February 7, 2024
Foundation models, e.g., ChatGPT/GPT-4/GPT-4V, at the forefront of artificial intelligence (AI) and deep learning, represent a pivotal leap in the domain of computational intelligence. This special issue aims to explore and showcase cutting-edge research in the development and application of foundation models for medical imaging within the field of healthcare. Οriginal and innovative methodological contributions are invited, which address the key challenges in developing, validating and applying foundation models for medical imaging. This is an open call for papers. Stay tuned for more details!
Share this page:
Deep Learning Applications in Medical Image Analysis

The tremendous success of machine learning algorithms at image recognition tasks in recent years intersects with a time of dramatically increased use of electronic medical records and diagnostic imaging. This review introduces the machine learning algorithms as applied to medical image analysis, focusing on convolutional neural networks, and emphasizing clinical aspects of the field. The advantage of machine learning in an era of medical big data is that significant hierarchal relationships within the data can be discovered algorithmically without laborious hand-crafting of features. We cover key research areas and applications of medical image classification, localization, detection, segmentation, and registration. We conclude by discussing research obstacles, emerging trends, and possible future directions.
View this article on IEEE Xplore
At a Glance
- Journal: IEEE Access
- Format: Open Access
- Frequency: Continuous
- Submission to Publication: 4-6 weeks (typical)
- Topics: All topics in IEEE
- Average Acceptance Rate: 27%
- Impact Factor: 3.4
- Model: Binary Peer Review
- Article Processing Charge: US $1,995
Featured Articles
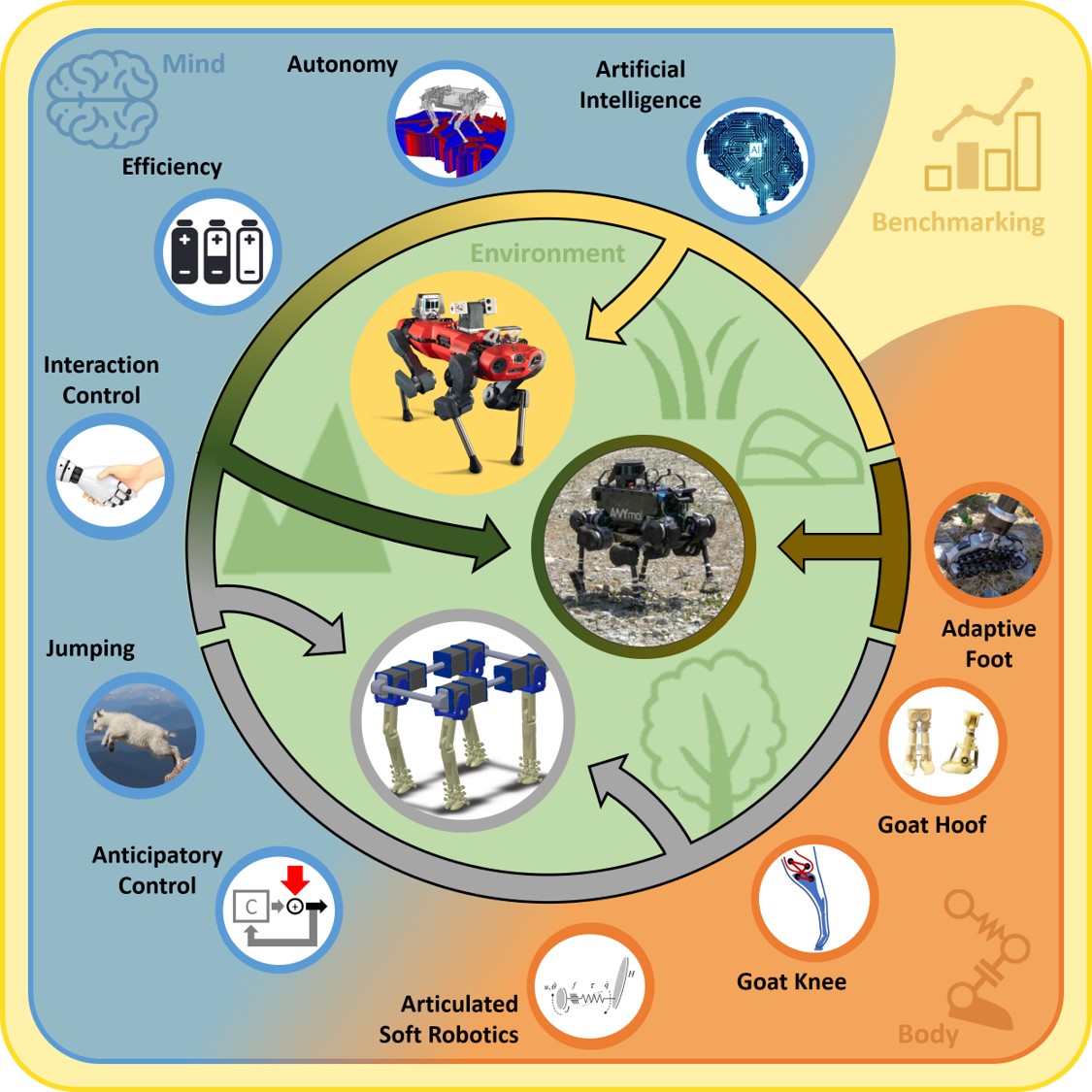
Robotic Monitoring of Habitats: The Natural Intelligence Approach
View in IEEE Xplore
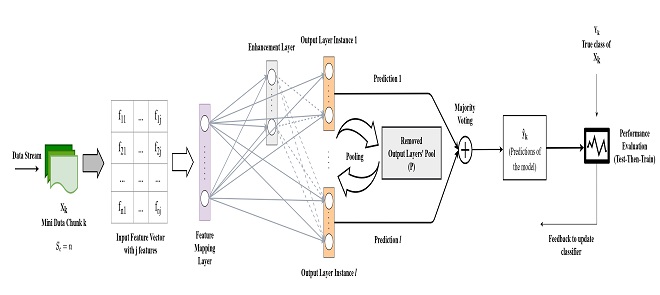
A Broad Ensemble Learning System for Drifting Stream Classification
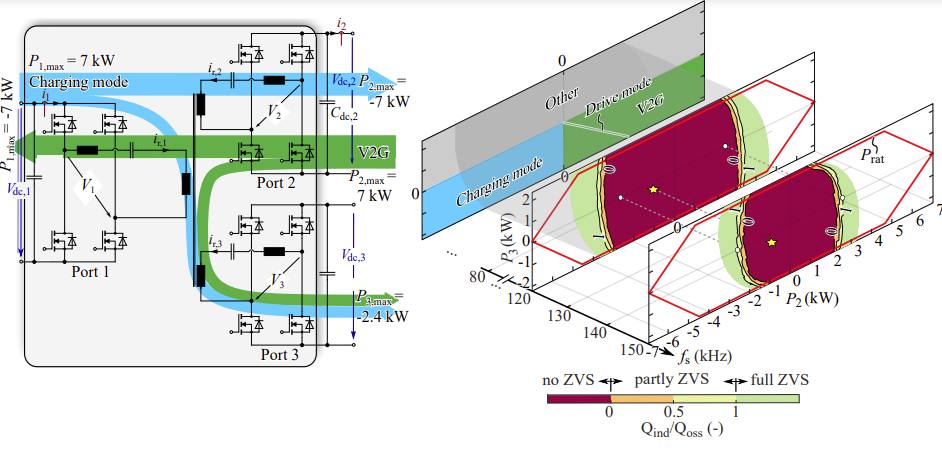
Increasing Light Load Efficiency in Phase-Shifted, Variable Frequency Multiport Series Resonant Converters
Submission guidelines.
© 2024 IEEE - All rights reserved. Use of this website signifies your agreement to the IEEE TERMS AND CONDITIONS.
A not-for-profit organization, IEEE is the world’s largest technical professional organization dedicated to advancing technology for the benefit of humanity.
AWARD RULES:
NO PURCHASE NECESSARY TO ENTER OR WIN. A PURCHASE WILL NOT INCREASE YOUR CHANCES OF WINNING.
These rules apply to the “2024 IEEE Access Best Video Award Part 2″ (the “Award”).
- Sponsor: The Sponsor of the Award is The Institute of Electrical and Electronics Engineers, Incorporated (“IEEE”) on behalf of IEEE Access , 445 Hoes Lane, Piscataway, NJ 08854-4141 USA (“Sponsor”).
- Eligibility: Award is open to residents of the United States of America and other countries, where permitted by local law, who are the age of eighteen (18) and older. Employees of Sponsor, its agents, affiliates and their immediate families are not eligible to enter Award. The Award is subject to all applicable state, local, federal and national laws and regulations. Entrants may be subject to rules imposed by their institution or employer relative to their participation in Awards and should check with their institution or employer for any relevant policies. Void in locations and countries where prohibited by law.
- Agreement to Official Rules : By participating in this Award, entrants agree to abide by the terms and conditions thereof as established by Sponsor. Sponsor reserves the right to alter any of these Official Rules at any time and for any reason. All decisions made by Sponsor concerning the Award including, but not limited to the cancellation of the Award, shall be final and at its sole discretion.
- How to Enter: This Award opens on July 1, 2024 at 12:00 AM ET and all entries must be received by 11:59 PM ET on December 31, 2024 (“Promotional Period”).
Entrant must submit a video with an article submission to IEEE Access . The video submission must clearly be relevant to the submitted manuscript. Only videos that accompany an article that is accepted for publication in IEEE Access will qualify. The video may be simulations, demonstrations, or interviews with other experts, for example. Your video file should not exceed 100 MB.
Entrants can enter the Award during Promotional Period through the following method:
- The IEEE Author Portal : Entrants can upload their video entries while submitting their article through the IEEE Author Portal submission site .
- Review and Complete the Terms and Conditions: After submitting your manuscript and video through the IEEE Author Portal, entrants should then review and sign the Terms and Conditions .
Entrants who have already submitted a manuscript to IEEE Access without a video can still submit a video for inclusion in this Award so long as the video is submitted within 7 days of the article submission date. The video can be submitted via email to the article administrator. All videos must undergo peer review and be accepted along with the article submission. Videos may not be submitted after an article has already been accepted for publication.
The criteria for an article to be accepted for publication in IEEE Access are:
- The article must be original writing that enhances the existing body of knowledge in the given subject area. Original review articles and surveys are acceptable even if new data/concepts are not presented.
- Results reported must not have been submitted or published elsewhere (although expanded versions of conference publications are eligible for submission).
- Experiments, statistics, and other analyses must be performed to a high technical standard and are described in sufficient detail.
- Conclusions must be presented in an appropriate fashion and are supported by the data.
- The article must be written in standard English with correct grammar.
- Appropriate references to related prior published works must be included.
- The article must fall within the scope of IEEE Access
- Must be in compliance with the IEEE PSPB Operations Manual.
- Completion of the required IEEE intellectual property documents for publication.
- At the discretion of the IEEE Access Editor-in-Chief.
- Disqualification: The following items will disqualify a video from being considered a valid submission:
- The video is not original work.
- A video that is not accompanied with an article submission.
- The article and/or video is rejected during the peer review process.
- The article and/or video topic does not fit into the scope of IEEE Access .
- The article and/or do not follow the criteria for publication in IEEE Access .
- Videos posted in a comment on IEEE Xplore .
- Content is off-topic, offensive, obscene, indecent, abusive or threatening to others.
- Infringes the copyright, trademark or other right of any third party.
- Uploads viruses or other contaminating or destructive features.
- Is in violation of any applicable laws or regulations.
- Is not in English.
- Is not provided within the designated submission time.
- Entrant does not agree and sign the Terms and Conditions document.
Entries must be original. Entries that copy other entries, or the intellectual property of anyone other than the Entrant, may be removed by Sponsor and the Entrant may be disqualified. Sponsor reserves the right to remove any entry and disqualify any Entrant if the entry is deemed, in Sponsor’s sole discretion, to be inappropriate.
- Entrant’s Warranty and Authorization to Sponsor: By entering the Award, entrants warrant and represent that the Award Entry has been created and submitted by the Entrant. Entrant certifies that they have the ability to use any image, text, video, or other intellectual property they may upload and that Entrant has obtained all necessary permissions. IEEE shall not indemnify Entrant for any infringement, violation of publicity rights, or other civil or criminal violations. Entrant agrees to hold IEEE harmless for all actions related to the submission of an Entry. Entrants further represent and warrant, if they reside outside of the United States of America, that their participation in this Award and acceptance of a prize will not violate their local laws.
- Intellectual Property Rights: Entrant grants Sponsor an irrevocable, worldwide, royalty free license to use, reproduce, distribute, and display the Entry for any lawful purpose in all media whether now known or hereinafter created. This may include, but is not limited to, the IEEE A ccess website, the IEEE Access YouTube channel, the IEEE Access IEEE TV channel, IEEE Access social media sites (LinkedIn, Facebook, Twitter, IEEE Access Collabratec Community), and the IEEE Access Xplore page. Facebook/Twitter/Microsite usernames will not be used in any promotional and advertising materials without the Entrants’ expressed approval.
- Number of Prizes Available, Prizes, Approximate Retail Value and Odds of winning Prizes: Two (2) promotional prizes of $350 USD Amazon gift cards. One (1) grand prize of a $500 USD Amazon gift card. Prizes will be distributed to the winners after the selection of winners is announced. Odds of winning a prize depend on the number of eligible entries received during the Promotional Period. Only the corresponding author of the submitted manuscript will receive the prize.
The grand prize winner may, at Sponsor’ discretion, have his/her article and video highlighted in media such as the IEEE Access Xplore page and the IEEE Access social media sites.
The prize(s) for the Award are being sponsored by IEEE. No cash in lieu of prize or substitution of prize permitted, except that Sponsor reserves the right to substitute a prize or prize component of equal or greater value in its sole discretion for any reason at time of award. Sponsor shall not be responsible for service obligations or warranty (if any) in relation to the prize(s). Prize may not be transferred prior to award. All other expenses associated with use of the prize, including, but not limited to local, state, or federal taxes on the Prize, are the sole responsibility of the winner. Winner(s) understand that delivery of a prize may be void where prohibited by law and agrees that Sponsor shall have no obligation to substitute an alternate prize when so prohibited. Amazon is not a sponsor or affiliated with this Award.
- Selection of Winners: Promotional prize winners will be selected based on entries received during the Promotional Period. The sponsor will utilize an Editorial Panel to vote on the best video submissions. Editorial Panel members are not eligible to participate in the Award. Entries will be ranked based on three (3) criteria:
- Presentation of Technical Content
- Quality of Video
Upon selecting a winner, the Sponsor will notify the winner via email. All potential winners will be notified via their email provided to the sponsor. Potential winners will have five (5) business days to respond after receiving initial prize notification or the prize may be forfeited and awarded to an alternate winner. Potential winners may be required to sign an affidavit of eligibility, a liability release, and a publicity release. If requested, these documents must be completed, signed, and returned within ten (10) business days from the date of issuance or the prize will be forfeited and may be awarded to an alternate winner. If prize or prize notification is returned as undeliverable or in the event of noncompliance with these Official Rules, prize will be forfeited and may be awarded to an alternate winner.
- General Prize Restrictions: No prize substitutions or transfer of prize permitted, except by the Sponsor. Import/Export taxes, VAT and country taxes on prizes are the sole responsibility of winners. Acceptance of a prize constitutes permission for the Sponsor and its designees to use winner’s name and likeness for advertising, promotional and other purposes in any and all media now and hereafter known without additional compensation unless prohibited by law. Winner acknowledges that neither Sponsor, Award Entities nor their directors, employees, or agents, have made nor are in any manner responsible or liable for any warranty, representation, or guarantee, express or implied, in fact or in law, relative to any prize, including but not limited to its quality, mechanical condition or fitness for a particular purpose. Any and all warranties and/or guarantees on a prize (if any) are subject to the respective manufacturers’ terms therefor, and winners agree to look solely to such manufacturers for any such warranty and/or guarantee.
11.Release, Publicity, and Privacy : By receipt of the Prize and/or, if requested, by signing an affidavit of eligibility and liability/publicity release, the Prize Winner consents to the use of his or her name, likeness, business name and address by Sponsor for advertising and promotional purposes, including but not limited to on Sponsor’s social media pages, without any additional compensation, except where prohibited. No entries will be returned. All entries become the property of Sponsor. The Prize Winner agrees to release and hold harmless Sponsor and its officers, directors, employees, affiliated companies, agents, successors and assigns from and against any claim or cause of action arising out of participation in the Award.
Sponsor assumes no responsibility for computer system, hardware, software or program malfunctions or other errors, failures, delayed computer transactions or network connections that are human or technical in nature, or for damaged, lost, late, illegible or misdirected entries; technical, hardware, software, electronic or telephone failures of any kind; lost or unavailable network connections; fraudulent, incomplete, garbled or delayed computer transmissions whether caused by Sponsor, the users, or by any of the equipment or programming associated with or utilized in this Award; or by any technical or human error that may occur in the processing of submissions or downloading, that may limit, delay or prevent an entrant’s ability to participate in the Award.
Sponsor reserves the right, in its sole discretion, to cancel or suspend this Award and award a prize from entries received up to the time of termination or suspension should virus, bugs or other causes beyond Sponsor’s control, unauthorized human intervention, malfunction, computer problems, phone line or network hardware or software malfunction, which, in the sole opinion of Sponsor, corrupt, compromise or materially affect the administration, fairness, security or proper play of the Award or proper submission of entries. Sponsor is not liable for any loss, injury or damage caused, whether directly or indirectly, in whole or in part, from downloading data or otherwise participating in this Award.
Representations and Warranties Regarding Entries: By submitting an Entry, you represent and warrant that your Entry does not and shall not comprise, contain, or describe, as determined in Sponsor’s sole discretion: (A) false statements or any misrepresentations of your affiliation with a person or entity; (B) personally identifying information about you or any other person; (C) statements or other content that is false, deceptive, misleading, scandalous, indecent, obscene, unlawful, defamatory, libelous, fraudulent, tortious, threatening, harassing, hateful, degrading, intimidating, or racially or ethnically offensive; (D) conduct that could be considered a criminal offense, could give rise to criminal or civil liability, or could violate any law; (E) any advertising, promotion or other solicitation, or any third party brand name or trademark; or (F) any virus, worm, Trojan horse, or other harmful code or component. By submitting an Entry, you represent and warrant that you own the full rights to the Entry and have obtained any and all necessary consents, permissions, approvals and licenses to submit the Entry and comply with all of these Official Rules, and that the submitted Entry is your sole original work, has not been previously published, released or distributed, and does not infringe any third-party rights or violate any laws or regulations.
12.Disputes: EACH ENTRANT AGREES THAT: (1) ANY AND ALL DISPUTES, CLAIMS, AND CAUSES OF ACTION ARISING OUT OF OR IN CONNECTION WITH THIS AWARD, OR ANY PRIZES AWARDED, SHALL BE RESOLVED INDIVIDUALLY, WITHOUT RESORTING TO ANY FORM OF CLASS ACTION, PURSUANT TO ARBITRATION CONDUCTED UNDER THE COMMERCIAL ARBITRATION RULES OF THE AMERICAN ARBITRATION ASSOCIATION THEN IN EFFECT, (2) ANY AND ALL CLAIMS, JUDGMENTS AND AWARDS SHALL BE LIMITED TO ACTUAL OUT-OF-POCKET COSTS INCURRED, INCLUDING COSTS ASSOCIATED WITH ENTERING THIS AWARD, BUT IN NO EVENT ATTORNEYS’ FEES; AND (3) UNDER NO CIRCUMSTANCES WILL ANY ENTRANT BE PERMITTED TO OBTAIN AWARDS FOR, AND ENTRANT HEREBY WAIVES ALL RIGHTS TO CLAIM, PUNITIVE, INCIDENTAL, AND CONSEQUENTIAL DAMAGES, AND ANY OTHER DAMAGES, OTHER THAN FOR ACTUAL OUT-OF-POCKET EXPENSES, AND ANY AND ALL RIGHTS TO HAVE DAMAGES MULTIPLIED OR OTHERWISE INCREASED. ALL ISSUES AND QUESTIONS CONCERNING THE CONSTRUCTION, VALIDITY, INTERPRETATION AND ENFORCEABILITY OF THESE OFFICIAL RULES, OR THE RIGHTS AND OBLIGATIONS OF ENTRANT AND SPONSOR IN CONNECTION WITH THE AWARD, SHALL BE GOVERNED BY, AND CONSTRUED IN ACCORDANCE WITH, THE LAWS OF THE STATE OF NEW JERSEY, WITHOUT GIVING EFFECT TO ANY CHOICE OF LAW OR CONFLICT OF LAW, RULES OR PROVISIONS (WHETHER OF THE STATE OF NEW JERSEY OR ANY OTHER JURISDICTION) THAT WOULD CAUSE THE APPLICATION OF THE LAWS OF ANY JURISDICTION OTHER THAN THE STATE OF NEW JERSEY. SPONSOR IS NOT RESPONSIBLE FOR ANY TYPOGRAPHICAL OR OTHER ERROR IN THE PRINTING OF THE OFFER OR ADMINISTRATION OF THE AWARD OR IN THE ANNOUNCEMENT OF THE PRIZES.
- Limitation of Liability: The Sponsor, Award Entities and their respective parents, affiliates, divisions, licensees, subsidiaries, and advertising and promotion agencies, and each of the foregoing entities’ respective employees, officers, directors, shareholders and agents (the “Released Parties”) are not responsible for incorrect or inaccurate transfer of entry information, human error, technical malfunction, lost/delayed data transmissions, omission, interruption, deletion, defect, line failures of any telephone network, computer equipment, software or any combination thereof, inability to access web sites, damage to a user’s computer system (hardware and/or software) due to participation in this Award or any other problem or error that may occur. By entering, participants agree to release and hold harmless the Released Parties from and against any and all claims, actions and/or liability for injuries, loss or damage of any kind arising from or in connection with participation in and/or liability for injuries, loss or damage of any kind, to person or property, arising from or in connection with participation in and/or entry into this Award, participation is any Award-related activity or use of any prize won. Entry materials that have been tampered with or altered are void. If for any reason this Award is not capable of running as planned, or if this Award or any website associated therewith (or any portion thereof) becomes corrupted or does not allow the proper playing of this Award and processing of entries per these rules, or if infection by computer virus, bugs, tampering, unauthorized intervention, affect the administration, security, fairness, integrity, or proper conduct of this Award, Sponsor reserves the right, at its sole discretion, to disqualify any individual implicated in such action, and/or to cancel, terminate, modify or suspend this Award or any portion thereof, or to amend these rules without notice. In the event of a dispute as to who submitted an online entry, the entry will be deemed submitted by the authorized account holder the email address submitted at the time of entry. “Authorized Account Holder” is defined as the person assigned to an email address by an Internet access provider, online service provider or other organization responsible for assigning email addresses for the domain associated with the email address in question. Any attempt by an entrant or any other individual to deliberately damage any web site or undermine the legitimate operation of the Award is a violation of criminal and civil laws and should such an attempt be made, the Sponsor reserves the right to seek damages and other remedies from any such person to the fullest extent permitted by law. This Award is governed by the laws of the State of New Jersey and all entrants hereby submit to the exclusive jurisdiction of federal or state courts located in the State of New Jersey for the resolution of all claims and disputes. Facebook, LinkedIn, Twitter, G+, YouTube, IEEE Xplore , and IEEE TV are not sponsors nor affiliated with this Award.
- Award Results and Official Rules: To obtain the identity of the prize winner and/or a copy of these Official Rules, send a self-addressed stamped envelope to Kimberly Rybczynski, IEEE, 445 Hoes Lane, Piscataway, NJ 08854-4141 USA.

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
- Bioengineering (Basel)
- PMC10740686
How Artificial Intelligence Is Shaping Medical Imaging Technology: A Survey of Innovations and Applications
Luís pinto-coelho.
1 ISEP—School of Engineering, Polytechnic Institute of Porto, 4200-465 Porto, Portugal; tp.ppi.pesi@cfl
2 INESCTEC, Campus of the Engineering Faculty of the University of Porto, 4200-465 Porto, Portugal
Associated Data
Not applicable.
The integration of artificial intelligence (AI) into medical imaging has guided in an era of transformation in healthcare. This literature review explores the latest innovations and applications of AI in the field, highlighting its profound impact on medical diagnosis and patient care. The innovation segment explores cutting-edge developments in AI, such as deep learning algorithms, convolutional neural networks, and generative adversarial networks, which have significantly improved the accuracy and efficiency of medical image analysis. These innovations have enabled rapid and accurate detection of abnormalities, from identifying tumors during radiological examinations to detecting early signs of eye disease in retinal images. The article also highlights various applications of AI in medical imaging, including radiology, pathology, cardiology, and more. AI-based diagnostic tools not only speed up the interpretation of complex images but also improve early detection of disease, ultimately delivering better outcomes for patients. Additionally, AI-based image processing facilitates personalized treatment plans, thereby optimizing healthcare delivery. This literature review highlights the paradigm shift that AI has brought to medical imaging, highlighting its role in revolutionizing diagnosis and patient care. By combining cutting-edge AI techniques and their practical applications, it is clear that AI will continue shaping the future of healthcare in profound and positive ways.
1. Introduction
Advancements in medical imaging and artificial intelligence (AI) have ushered in a new era of possibilities in the field of healthcare. The fusion of these two domains has revolutionized various aspects of medical practice, ranging from early disease detection and accurate diagnosis to personalized treatment planning and improved patient outcomes.
Medical imaging techniques such as computed tomography (CT), magnetic resonance imaging (MRI), and positron emission tomography (PET) play a pivotal role in providing clinicians with detailed and comprehensive visual information about the human body. These imaging modalities generate vast amounts of data that require efficient analysis and interpretation, and this is where AI steps in.
AI, particularly deep learning algorithms, has demonstrated remarkable capabilities in extracting valuable insights from medical images [ 1 ]. Deep learning models, trained on large datasets, are capable of recognizing complex patterns and features that may not be readily discernible to the human eye [ 2 , 3 ]. These algorithms can even provide a new perspective about what image features should be valued to support decisions [ 4 ]. One of the key advantages of AI in medical imaging is its ability to enhance the accuracy and efficiency of disease diagnosis [ 1 , 5 ]. Through this process, AI can assist healthcare professionals in detecting abnormalities, identifying specific structures, and predicting disease outcomes [ 5 , 6 ].
By leveraging machine learning algorithms, AI systems can analyze medical images with speed and precision, aiding in the identification of early-stage diseases that may be difficult to detect through traditional methods. This early detection is crucial as it can lead to timely interventions, potentially saving lives and improving treatment outcomes [ 1 , 2 , 3 ].
Furthermore, AI has opened up new possibilities in image segmentation and quantification. By employing sophisticated algorithms, AI can accurately delineate structures of interest within medical images, such as tumors, blood vessels, or cells [ 7 , 8 , 9 ]. This segmentation capability is invaluable in treatment planning, as it enables clinicians to precisely target areas for intervention, optimize surgical procedures, and deliver targeted therapies [ 10 ].
The integration of AI and medical imaging has also facilitated the development of personalized medicine. Through the analysis of medical images and patient data, AI algorithms can generate patient-specific insights, enabling tailored treatment plans that consider individual variations in anatomy, physiology, and disease characteristics. This personalized approach to healthcare enhances treatment efficacy and minimizes the risk of adverse effects, leading to improved patient outcomes and quality of life [ 1 , 11 , 12 ].
Additionally, AI has paved the way for advancements in image-guided interventions and surgical procedures. By combining preoperative imaging data with real-time imaging during surgery, AI algorithms can provide surgeons with augmented visualization, navigation assistance, and decision support. These tools enhance surgical precision, reduce procedural risks, and enable minimally invasive techniques, ultimately improving patient safety and surgical outcomes [ 13 ].
Recently several cutting-edge articles have been published covering a wide variety of topics within the scope of medical imaging and AI. Many of these outstanding advancements are directed to cancer, a major cause of severe disease and mortality. The main contributions and fields will be addressed in the next sections.
2. Methodology
The primary aim of this review is to present a comprehensive overview of the influential artificial intelligence (AI) technological advancements that are shaping the landscape of medical imaging in recent years. The construction of the article dataset followed a two-stage methodology. Initially, to identify the most pertinent AI-supported clinical imaging application, searches were conducted on major scientific article repositories. In July 2023, queries were made on PubMed, IEEE, Scopus, ScienceDirect, Web of Science, and ACM, focusing on the Title and Abstract of articles. Filters for language (English only) and year of publication (2017 and onwards) were applied. Search terms encompassed key machine learning words and expressions (e.g., “machine learning”, “artificial intelligence”, “classification”, “segmentation”) combined with clinical image-related keywords (e.g., “image”, “pixel”, “resolution”, “MRI”, “PET”, “CT”). After article retrieval, duplicates were eliminated. It is also important to mention that preprint articles, such as arXiv, bioRxiv, medRxiv, among others, were also queried as part of the Scopus indexing system. These are major open-access article archives holding highly relevant manuscripts (considering the number of citations and widespread usage) but whose content was not peer reviewed.
In the second stage, the previously identified papers and their references were utilized as seeds to construct connection maps, employing the LitMaps [ 14 ] web tool to identify the most relevant technologies. The Iramuteq software [ 15 ] was also used to generate and explore word and concept networks using some of the included natural language processing tools [ 16 ]. The selection of technologies was based on manual observation of connection maps, with a focus on identifying healthcare-related keyword groups. The use of this methodology implied some ad hoc criteria since the mentioned tools are agnostic to the underlying clinical processes and not always are able to correctly group medical areas. With the described methodology, the ultimate aim was to encompass a broad spectrum of disease handling processes and support activities, emphasizing the most promising technological approaches to date while acknowledging identified limitations. Additionally, emphasis has been given to review articles that were specifically referenced when available for specific domains, as they offer an enhanced overview within a confined area of knowledge. The final article corpus showed a distribution by year of publication as depicted in Figure 1 . It can be observed that 2023 has the highest number of review/survey articles, which can evidence the interest in the area but can also be an indicator of the diversity of involved technologies, demanding for an overview article.

Distribution of the selected articles by year of publication.
3. Technological Innovations
Mathematical models and algorithms stand at the forefront of scientific exploration, serving as powerful tools that enable us to unravel complex phenomena, make predictions, and uncover hidden patterns in vast datasets. These essential components of modern research have not only revolutionized our understanding of the natural world but have also played a pivotal role in driving technological breakthroughs that open up numerous application possibilities across various domains. The synergy between mathematical models and algorithms has not only enhanced our understanding of the world but has also been a driving force behind technological advancements that have transformed our daily lives.
The earliest multilayer perceptron networks, while representing a crucial step in the evolution of neural networks, had notable limitations. One of the primary constraints was their shallow architecture, which consisted of only a few layers, limiting their ability to model complex patterns. Besides the model expansion restrictions imposed by the limited computing power, training these networks with multiple layers was also challenging. In particular, the earliest activation functions used in neural networks, including the sigmoid and hyperbolic tangent (tanh), led to the vanishing gradient problem [ 17 ] as their gradients became exceedingly small as inputs moved away from zero. This issue impeded the efficient propagation of gradients during training, resulting in slow convergence or training failures. Furthermore, the limited output range of these functions and their symmetric nature constrained the network’s ability to represent complex, high-dimensional data. Additionally, the computational complexity of these functions, particularly the exponential calculations, hindered training and inference in large networks. These shortcomings led to the development and widespread adoption of more suitable activation functions, such as the rectified linear unit (ReLU) [ 18 ] and its variants, which successfully addressed these issues and became integral components of modern deep learning architectures [ 19 ]. For these reasons, early multilayer perceptron networks struggled to capture complex patterns in data, making them unsuitable for tasks requiring the modeling of intricate relationships, ultimately leading to the necessity of exploration of more advanced architectures and training techniques.
Improvements in the artificial neurons’ functionality, more advanced architectures, and improved training algorithms supported by graphical computational units (GPU) came to open promising possibilities. The LeNet-5 architecture, developed for the recognition of handwritten digits [ 20 ], is a fundamental milestone for convolutional neural networks (CNNs) [ 21 , 22 ].
CNNs, inspired by the biological operation of animals’ vision system, assume that the input is the representation of image data. Current architectures follow a structured sequence of layers, each with specific functions to process and extract features from the input data [ 23 ]. The journey begins with the input layer, which receives raw image data, typically represented as a grid of pixel values, often with three color channels (red, green, blue) for color images. Following the input layer, the network employs convolutional layers, which are responsible for feature extraction. These layers use convolutional operations (of several types [ 22 ]) to detect local patterns and features in the input data. Early convolutional layers focus on detecting basic features like edges, corners, and textures. After each convolution operation, activation layers with rectified linear unit (ReLU) activation functions are applied to introduce nonlinearity. ReLU units help the network learn more complex patterns and enhance its ability to model the data effectively. Pooling (Subsampling) layers come next, reducing the spatial dimensions of the feature maps while preserving important information. Max pooling and average pooling are common operations that help make the network more robust to variations in scale and position. The sequence of convolutional layers continues, with additional layers stacked to capture increasingly complex and abstract features. These deeper layers are adept at detecting higher-level patterns, shapes, and objects in the data. Similar to the earlier convolutional layers, activation layers with ReLU functions are applied after each convolution operation, maintaining nonlinearity and enhancing feature learning. Pooling (subsampling) layers may be used again, further decreasing the spatial dimensions of the feature maps and retaining essential information. At the end of this sequence, after the network has extracted the most relevant information from the input data, a special set of vectors are obtained, designated by deep features [ 24 ]. These, located deep in the network, distill data into compact, meaningful forms that are highly discriminative. Or, in other words, after the progressive extraction of information, layer after layer, raw input data is refined into more condensed and abstract representations that are imbued with semantic meaning, encapsulating essential characteristics of the input. They are highly discriminative and have lower dimensionality than the raw input data, which not only conserves computational resources but also simplifies subsequent processing, making it especially beneficial in the analysis of high-dimensional data, such as images. This process also eliminates the tedious and error-prone process of handcrafted feature selection, leading to optimized feature sets and to the possibility of building the so-called “end-to-end” systems. Deep features can also help mitigate overfitting, a common challenge in machine learning, since by learning relevant representations, they prevent models from memorizing the training data and encourage more robust generalization.
Another great advantage of deep feature extraction pipelines is the possibility of using transfer learning techniques. In this case, a deep feature extraction network previously successfully developed on one task or dataset can be transferred and fine-tuned to another related task, significantly reducing the need for large, labeled datasets and speeding up model training. This versatility is a game changer in many applications.
After this extraction front end, continuing with the processing pipeline and moving towards the end of the network, fully connected layers are introduced. These layers come after the convolutional and pooling layers and play a pivotal role in feature aggregation and classification. The deep features extracted by the previous layers are flattened and processed through one or more fully connected layers.
Finally, the output layer emerges as the last layer of the network. The number of neurons in this layer corresponds to the number of classes in a classification task or the number of output units in a regression task. For classification tasks, a sigmoid or a softmax activation function is typically used to calculate class probabilities, providing the final output of the CNN [ 25 , 26 ]. A sigmoid function is commonly employed in binary classification, producing a single probability score indicating the likelihood of belonging to the positive class. The softmax function is favored for its ability to transform raw output scores into probability distributions across multiple classes. This conversion ensures that the computed probabilities represent the likelihood of the input belonging to each class, with the sum of probabilities equating to one, thereby constituting a valid probability distribution. Beyond this interpretability, both functions are differentiable, a critical attribute for the application of gradient-based optimization algorithms like backpropagation during training.
The described structured sequence of layers, from the input layer to the output layer, captures the hierarchical feature learning process in a CNN, allowing it to excel in image classification tasks (among others). Specific CNN architectures may introduce variations, additional components, or specialized layers based on the network’s design goals and requirements.
3.1. Transformers
CNNs are well suited for grid-like data, such as images, where local patterns can be captured efficiently. However, they struggle with sequential data because they lack a mechanism for modeling dependencies between distant elements (for example, in distinct time instants or far in the image). Also, CNNs do not inherently model the position or order of elements within the data. They rely on shared weight filters, which makes them translation invariant but can be problematic when absolute spatial relationships are important [ 27 ]. To overcome these limitations (handling sequential data, modeling long-range dependencies, incorporating positional information, and addressing tasks involving multimodal data, among others), transformers were introduced [ 28 ]. In the context of machine learning applied to images, transformers are a type of neural network architecture that extends the transformer model, originally designed for natural language processing [ 28 ], to handle computer vision tasks. These models are often referred to as vision transformers (ViTs) or image transformers [ 29 ] and come to introduce performance benefits, especially in noisy conditions [ 30 , 31 ]. In clinical settings, applications cover diagnosis and prognosis [ 32 ], encompassing classification, segmentation, and reconstruction tasks in distinct stages [ 31 , 33 ].
In vision transformers (ViT), the initial image undergoes a transformation process, wherein it is divided into a sequence of patches, as can be observed in Figure 2 . Each of these patches is associated with a positional encoding technique, which captures and encodes the spatial positions of the patches, thus preserving spatial information. These patches, together with a class token, are then input into a transformer model to perform multi-head self-attention (MHSA) and generate embeddings that represent the learned characteristics of the patches. The class token’s state in the ViT’s output underscores a pivotal aspect of the model’s architecture since it acts as a global aggregator of information from all patches, offering a comprehensive representation of the entire image. The token’s state is dynamically updated during processing, reflecting a holistic understanding that encapsulates both local details and also the broader context of the image. Finally, a multilayer perceptron (MLP) is employed for the purpose of classifying the learned image representation. Notably, in addition to using raw images, it is also possible to supply feature maps generated by convolutional neural networks (CNNs) as input into a vision transformer for the purpose of establishing relational mappings [ 34 ]. It is also possible to use the transformer’s encoding technique to explore the model’s explainability [ 35 ].

Pipeline for applying the transformer’s technique to images.
The attention mechanism is a fundamental component in transformers. It plays a pivotal role in enabling the model to selectively focus on different parts of the input data with varying degrees of attention. At its core, the attention mechanism allows the model to assign varying levels of importance to different elements within the input data. This means the model can “pay attention” to specific elements while processing the data, prioritizing those that are most relevant to the task at hand. This selective attention enhances the model’s ability to capture essential information and relationships within the input. The mechanism operates as follows: First, the input data is organized into a sequence of elements, such as tokens in a sentence for NLP or patches in an image for computer vision. Then, the mechanism introduces three sets of learnable parameters: query (Q), key (K), and value (V). The query represents the element of interest, while the key and value pairs are associated with each element in the input sequence. For each element in the input sequence, the attention mechanism calculates an attention score, reflecting the similarity between the query and the key for that element. The method used to measure this similarity can vary, with techniques like dot product and scaled dot product being common choices. These attention scores represent how relevant each element is to the query. The next step involves applying the softmax function to the attention scores. This converts them into weights that sum to one, effectively determining the importance of each input element concerning the query. The higher the weight, the more attention the model allocates to that specific element in the input data. Finally, the attention mechanism computes a weighted sum of the values, using the attention weights. The resulting output is a combination of information from all input elements, with elements more relevant to the query receiving higher weight in the final representation [ 36 , 37 ].
The attention mechanism can be used in various ways (attention gate [ 38 ], mixed attention [ 39 ], among others in the medical field), with one prominent variant being self-attention. In self-attention, the query, key, and value all originate from the same input sequence. This allows the architecture to model relationships and dependencies between elements within the same sequence, making it particularly useful for tasks that involve capturing long-range dependencies and context [ 7 , 40 , 41 ].
The original ViT architecture, as in Figure 3 a, was enhanced with the hierarchical vision transformer using shifted windows (SWIN transformer) [ 42 ] where a hierarchical partitioning of the image into patches is used. This means that the image is first divided into smaller patches, and then these patches are merged together as the network goes deeper, as in Figure 3 b. This hierarchical approach allows SWIN to capture both local and global features in the image, which can improve its performance on a variety of tasks. In the SWIN transformer, images of different resolutions belonging to outputs of different stages can be used to facilitate segmentation tasks.

Comparison of architecture operation when going deep in the network.
Another key difference between SWIN and ViT is that SWIN uses a shifted window self-attention mechanism, as depicted in Figure 4 . This means that the self-attention operation is only applied to a local window of patches, or in other words, to a limited number of neighbor patches (as represented in green in Figure 4 ) rather than the entire image. Then, in a second stage, the attention window focus location is shifted to a different location (by patch cyclic shifting). This shifted window approach comes to reduce the computational load and complexity of the self-attention operation, which can improve the efficiency of the SWIN architecture. These differences, when compared with the original ViT, allow a more efficient and scalable architecture, which were further refined in SWIN v2 [ 43 ].

Shifted window’s mechanism for the self-attention mechanism in the SWIN transformer.
The transformer-based approach has received a lot of attention due to its effectiveness, still with improvement opportunities [ 44 ]. The described innovations have been crucial in advancing the state of the art in medical image processing, covering machine learning tasks, such as classification, segmentation, synthesis (image or video), detection, and captioning [ 34 , 45 ]. By enhancing the model’s ability to focus on relevant information and understand complex relationships within the data, the attention mechanism represents a significant step in the improvement of the quality and effectiveness of various deep learning applications in the medical field.
Within the broad category of computer vision and artificial intelligence, the YOLO algorithm [ 46 ], which stands for “you only look once”, has gained a lot of popularity due to its performance in real-time object detection tasks. In the medical imaging field, the term “YOLO” is sometimes used more broadly to refer to implementations or systems that use one of the versions of the YOLO algorithm. It approaches object detection as a regression problem, predicting bounding box coordinates and class probabilities directly from the input image in a single pass through its underlying neural network (composed of backbone, neck, and head sections). This single-pass processing, where the image is divided into a grid for simultaneous predictions, distinguishes YOLO from other approaches and contributes to its exceptional speed. Postprediction, nonmaximum suppression is applied to filter redundant and low-confidence predictions, ensuring that each object is detected only once. In the medical field, YOLO has been used for a variety of imaging tasks, including cytology automation [ 47 ], detecting lung nodules in CT scans [ 48 ], segmentation of structures [ 49 ], detecting breast cancer in mammograms [ 50 ], or to track needles in ultrasound sequences [ 51 ], among others. YOLO’s fast and accurate object detection capabilities make it an excellent choice for many medical imaging applications.
Finally, it is noteworthy to highlight the emergence of hybrid approaches that combine the aforementioned algorithms, as observed in instances like TransU-net [ 52 ] or ViT-YOLO [ 53 ]. These combinations aim to leverage the strengths of each individual algorithm, with the objective of achieving performance enhancements. It is important to acknowledge, however, that these approaches are still in an early stage of development and are not explored here.
3.2. Generative Models
Generative models are a class of machine learning models that can generate new data based on training data. Other generative models include generative adversarial networks (GANs), variational autoencoders (VAEs), and flow-based models. Each can produce high-quality images.
Generative adversarial networks, or GANs, are a class of machine learning models introduced in 2014 [ 54 ] that excel at generating data, often in the form of images, but applicable to other data types like text or audio as well. GANs consist of two neural networks: a generator and a discriminator. The generator creates synthetic data from random noise and aims to produce data that are indistinguishable from real data, while the discriminator tries to distinguish between real and fake data, as represented in Figure 5 . Through an adversarial training process, these networks compete, with the generator continually improving its ability to create realistic data and the discriminator enhancing its capacity to identify real from fake data.

Architecture overview for a generative adversarial network for images.
GANs have revolutionized the field of data generation, a highly valued resource due to the data avidity of modern machine learning systems, due to the lack of data in some areas and due to data protection and security constraints. These networks offer a highly effective way to create synthetic data that closely resemble real data. This is highly valuable, especially when dealing with limited datasets, as GANs can help augment training data for various machine learning tasks. For instance, in medical imaging, where obtaining large, diverse datasets can be challenging, GANs enable researchers to generate additional, realistic medical images for training diagnostic models, ultimately improving the accuracy of disease detection [ 55 ]. A recent study by Armanious et al. proposed a new framework called MedGAN [ 56 ] for medical image-to-image translation that operates on the image level in an end-to-end manner. MedGAN builds upon recent advances in the field of GANs by merging the adversarial framework with a new combination of nonadversarial losses. The framework utilizes a discriminator network as a trainable feature extractor which penalizes the discrepancy between the translated medical images and the desired modalities. Style-transfer losses are also utilized to match the textures and fine structures of the desired target images to the translated images. Additionally, a new generator architecture, titled CasNet, enhances the sharpness of the translated medical outputs through progressive refinement via encoder–decoder pairs. MedGAN was applied to three different tasks: PET–CT translation, correction of MR motion artefacts, and PET image denoising. Perceptual analysis by radiologists and quantitative evaluations illustrate that MedGAN outperforms other existing translation approaches.
Generative adversarial networks (GANs) have been a promising tool in the field of medical image analysis [ 57 ], particularly in image-to-image translation. Skandarani et al. [ 58 ] conducted an empirical study on GANs for medical image synthesis. The results revealed that GANs are far from being equal as some are ill-suited for medical imaging applications while others are much better off. The top-performing GANs are capable of generating realistic-looking medical images by FID standards that can fool trained experts in a visual Turing test and comply with some metrics [ 58 ]. The introduction of these models into clinical practice has been cautious [ 59 ], but the advantages and performance that have been successively achieved with their development have allowed GANs to become a successful technology.
Along with GANs, variational autoencoders (VAEs) are a popular technique for image generation. While both models are capable of generating images, they differ in their approach and training methodology. VAEs are a type of generative model that learns to encode the fundamental information of the input data into a latent space. The encoder network maps the input data to a latent space, which is then decoded by the decoder network to generate the output image. VAEs are trained using a probabilistic approach that maximizes the likelihood of the input data given the latent space. VAEs are better suited for applications that require probabilistic modeling, such as image reconstruction and denoising. This approach is capable of generating high-quality images but may suffer from blurry outputs [ 60 , 61 , 62 ].
Diffusion models constitute another class of generative models employed in image synthesis, functioning by iteratively transforming a base distribution into a target distribution through a series of diffusion steps [ 63 ]. These models leverage the concept of image diffusion, wherein the generation process unfolds progressively by adding noise to the image iteratively. Typically, the generation process commences with a simple distribution, such as a Gaussian, and refines it over multiple steps to approximate the desired complex distribution of real images. The iterative nature of diffusion models allows them to capture intricate structures and nuanced details present in medical images, where they can outperform GAN [ 64 , 65 ]. They can also be applied to video data [ 66 , 67 ].
Flow-based generative models represent a distinct approach in variational inference and natural image generation, recently gaining attention in the realm of computer vision [ 68 ]. The foundational concept, introduced in [ 69 ], centers around the utilization of a (normalizing) flow—a sequence of invertible mappings—to construct the transformation of a probability density, approximating a posterior distribution. The process commences with an initial variable, progressively mapping it to a variable characterized by a simple distribution (such as an isotropic Gaussian). This is achieved by iteratively applying the change of variable rule, akin to the inference mechanism in an encoder network. In the context of image generation, the initial variable is the real image governed by an unknown probability function. Through the employment of a well-designed inference network, the flow undergoes training to learn an accurate mapping. Importantly, the invertibility of the flow-based model facilitates the straightforward generation of synthetic images. This is accomplished by sampling from the simple distribution and navigating through the map in reverse. Comparative to alternative generative models and autoregressive models, flow-based methods offer a notable advantage by enabling tractable and accurate log-likelihood evaluation throughout the training process [ 70 ]. Simultaneously, they afford an efficient and exact sampling process from the simple prior distribution during testing. Image modality transfer [ 71 ] and 3D data augmentation [ 72 ] are promising areas in the medical field.
GANs are highly popular for magnetic resonance applications due to their ability to generate additional datasets and also due to the existing datasets that can support the training of effective models [ 73 ]. Reconstruction and segmentation tasks are also an important field of application. Here, the adversarial training plays a crucial role in imposing robust constraints on both the shape and texture of the generator’s output [ 73 ]. In some cases, GANs can be preferred over VAE due easier optimal model optimization [ 74 ]. In many applications, a balance must be found between the ability to generate high-quality samples, achieve fast sampling (inference), and exhibit mode diversity [ 75 ].
Overall, generative approaches are vital in machine learning for medical images due to their capacity to generate realistic data, drive innovation in image generation and manipulation, facilitate image-to-image translation, and open up creative opportunities for content generation across various domains.
3.3. Deep Learning Techniques and Performance Optimization
Medical imaging techniques are based on different physical principles, each with their benefits and limitations. The ability to deal with such diverse modalities is also an important aspect to be addressed by AI. In [ 76 ], a set of “tricks” are presented to improve the performance of deep learning models for multimodal image classification tasks. The authors start by emphasizing the increasing importance of multimodal image classification, which involves utilizing information from multiple modalities, such as images, text, and other data sources. For this, they also address the challenges specific to multimodal datasets, including data preprocessing, feature extraction, data imbalance, heterogeneity of modalities, data fusion, and model optimization. As defined by the authors, a “bag of tricks” or techniques can enhance the effectiveness of these models in handling multimodal data. These tricks can focus on the data, covering feature alignment, modality-specific preprocessing, and class balancing techniques, and also on the processing, using architectural modifications, training strategies, and regularization techniques. For the evaluation of such systems, benchmarking approaches are also presented and explored. These are valuable insights for researchers and practitioners working in the field of multimodal image classification.
4. Applications
AI-based imaging techniques can be divided in eight distinct categories: acquisition, preprocessing, feature extraction, registration, classification, object localization, segmentation, and visualization. These can also be organized in the clinical process pipeline broadly encompassing prevention, diagnostics, planning, therapy, prognostic, and monitoring. It is also possible to focus on the human organ or physiological process under focus. Using this last perspective, groups have been created using the associated keywords of the selected papers, and their relative expression has been calculated, as in Figure 6 . Notably, lungs emerge as the primary focus, likely attributed to the aftermath of the recent COVID-19 pandemic and the availability of novel, untapped datasets. The significance of the affected organ in human life should also be a pivotal factor driving researchers’ interest in each domain.

Number of publications per area of interest (showing the first six highest ranked, normalized to 100).
4.1. Medical Image Analysis for Disease Detection and Diagnosis
Medical image analysis for disease detection and diagnosis is a rapidly evolving field that holds immense potential for improving healthcare outcomes. By harnessing advanced computational techniques and machine learning algorithms, medical professionals are now able to extract invaluable insights from various medical imaging modalities [ 76 , 77 ].
Artificial intelligence is an area where great progress has been observed, and the number of techniques applicable to medical image processing has been increasing significantly. In this context of diversity, review articles where different techniques are presented and compared are useful. For example, in the area of automated retinal disease assessment (ARDA), AI can be used to help healthcare workers in the early detection, screening, diagnosis, and grading of retinal diseases such as diabetic retinopathy (DR), retinopathy of prematurity (RoP), and age-related macular degeneration (AMD), as shown in the comprehensive survey presented in [ 77 ]. The authors highlight the significance of medical image modalities, such as optical coherence tomography (OCT), fundus photography, and fluorescein angiography, in capturing detailed retinal images for diagnostic purposes and explain how AI can cope with these distinct information sources, either isolated or combined. The limitations and subjectivity of traditional manual examination and interpretation methods are emphasized, leading to the exploration of AI-based solutions. For this, an overview of the utilization of deep learning models is presented, and the most promising results in the detection and classification of retinal diseases, including age-related macular degeneration (AMD), diabetic retinopathy, and glaucoma, are thoroughly covered. The role of AI in facilitating the analysis of large-scale retinal datasets and the development of computer-aided diagnostic systems is also highlighted. However, AI is not always a perfect solution, and the challenges and limitations of AI-based approaches are also covered, addressing issues related to data availability, model interpretability, and regulatory considerations. Given the significant interest in this field and the promising results that AI has yielded, other studies have also emerged to cover various topics related to eye image analysis [ 78 , 79 ].
Another area of great interest is brain imaging, whose techniques play a crucial role in understanding the intricate workings of the human brain and in diagnosing neurological disorders. Methods such as magnetic resonance imaging (MRI), functional MRI (fMRI), positron emission tomography (PET), or electroencephalography signals (EEG) provide valuable insights into brain structure, function, and connectivity. However, the analysis of these complex data, be it images or signals, requires sophisticated tools and expertise. Again, artificial intelligence (AI) comes into play. The synergy between brain imaging and AI has the potential to revolutionize neuroscience and improve patient care by unlocking deeper insights into the intricacies of the human brain. In [ 80 ], a powerful combination of deep learning techniques and the sine–cosine fitness grey wolf optimization (SCFGWO) algorithm is used on the detection and classification of brain tumors. It addresses the importance of accurate tumor detection and classification as well as the associated challenges. Complexity and variability are tackled by convolutional neural networks (CNNs) that can automatically learn and extract relevant features for tumor analysis. In this case, the SCFGWO algorithm is used to fine-tune the parameters of the CNN leading to an optimized performance. Metrics, such as accuracy, sensitivity, specificity, and F1-score, are compared with other existing approaches to showcase the effectiveness and benefits of the proposed method in brain tumor detection and classification. The advantages and limitations of the proposed approach and the potential impact of the research in clinical practice are also mentioned.
Lung imaging has been a subject of extensive research interest [ 81 , 82 ], primarily due to the aggressive nature of lung cancer and its tendency to be detected at an advanced stage, leading to high mortality rates among cancer patients. In this context, accurate segmentation of lung fields in medical imaging plays a crucial role in the detection and analysis of lung diseases. In a recent study [ 83 ], the authors focused on segmenting lung fields in chest X-ray images using a combination of superpixel resizing and encoder–decoder segmentation networks. The study effectively addresses the challenges associated with lung field segmentation, including anatomical variations, image artifacts, and overlapping structures. It emphasizes the potential of deep learning techniques and the utilization of encoder–decoder architectures for semantic segmentation tasks. The proposed method, which combines superpixel resizing with an encoder–decoder segmentation network, demonstrates a high level of effectiveness compared to other approaches, as assessed using evaluation metrics such as the Dice similarity coefficient, Jaccard index, sensitivity, specificity, and accuracy.
More recently, the interest in lung imaging has been reinforced due to its importance in the diagnosis and monitoring of COVID-19 disease. In a notable study [ 84 ], the authors delve into the data-driven nature of AI and its need for high-quality data. They specifically focus on the generation of synthetic data, which involves creating artificial instances that closely mimic real data. In fact, by using the proposed approach, the synthetic images are nearly indistinguishable from read images when compared using the structural similarity index (SSIM), peak signal-to-noise ratio (PSNR), and the Fréchet inception distance (FID). In this case, lung CT for COVID-19 diagnosis is used as an application example where this proposed approach has shown to be successful. The problem is tackled by means of a new regularization strategy, which refers to a technique used to prevent overfitting in ML models. This strategy does not require making significant changes to the underlying neural network architecture, making it easier to implement. Furthermore, the proposed method’s efficacy extends beyond lung CT for COVID-19 diagnosis and can be easily adapted to other image types or imaging modalities. Consequently, future research endeavors can explore its applicability to diverse diseases and investigate its relevance to emerging AI topics, such as zero-shot or few-shot learning.
Breast cancer, the second most reported cancer worldwide, must be diagnosed as early as possible for a good prognostic. In this case, medical imaging is paramount for disease prevention and diagnosis. The effectiveness of an AI-based approach is evaluated in [ 85 ]. The authors present a novel investigation that constructs and evaluates two computer-aided detection (CAD) systems for digital mammograms. The objective was to differentiate between malignant and benign breast lesions by employing two state-of-the-art approaches based on radiomics (with features such as intensity, shape, and texture) and deep transfer learning concepts and technologies (with deep features). Two CAD systems were trained and assessed using a sizable and diverse dataset of 3000 images. The findings of this study indicate that deep transfer learning can effectively extract meaningful features from medical images, even with limited training data, offering more discriminatory information than traditional handcrafted radiomics features. However, explainability, a desired characteristic in artificial intelligence and in medical decision systems in particular, must be further explored to fully unravel the mysteries of these “black-box” models.
Still, concerning breast imaging, and addressing the typical high data needs of machine learning systems, a study was made to compare and optimize models using small datasets [ 86 ]. The article discusses the challenges associated with limited data, such as overfitting and model generalization. Distinct CNN architectures, such as AlexNet, VGGNet, and ResNet, are trained using small datasets. The authors discuss strategies to mitigate these limitations, such as data augmentation techniques, transfer learning, and model regularization. With these premises, a multiclass classifier, based on the BI-RADS lexicon on the INBreast dataset [ 87 ], was developed. Compared with the literature, the model was able to improve the state-of-the-art results. This comes to reinforce that discriminative fine-tuning works well with state-of-the-art CNN models and that it is possible to achieve excellent performance even on small datasets.
Radiomics and artificial intelligence (AI) play pivotal roles in advancing breast cancer imaging, offering a range of applications across the diagnostic spectrum. These technologies contribute significantly to risk stratification, aiding in the determination of cancer recurrence risks and providing valuable insights to guide treatment decisions [ 88 , 89 ]. Moreover, AI algorithms leverage radiomics features extracted from diverse medical imaging modalities, such as mammography, ultrasound, magnetic resonance imaging (MRI), and positron emission tomography (PET), to enhance the accuracy of detecting and classifying breast lesions [ 88 , 89 ]. For treatment planning, radiomics furnishes critical information regarding treatment effectiveness, facilitating the prediction of treatment responses and the formulation of personalized treatment plans [ 90 ]. Additionally, radiomics serves as a powerful tool for prognosis, enabling the prediction of outcomes such as disease-free survival and recurrence risk in breast cancer patients [ 91 ]. Furthermore, the robustness of MRI-based radiomics features against interobserver segmentation variability has been highlighted, indicating their potential for future breast MRI-based radiomics research [ 92 ].
Liver cancer is the third most common cause of death from cancer worldwide [ 93 ], and its incidence has been growing. Again, the development of the disease is often asymptomatic, making screening and early detection crucial for a good prognosis. In [ 8 ], the authors focus on the segmentation of liver lesions in CT images of the LiTS dataset [ 94 ]. As a novelty, the paper proposes an intelligent decision system for segmenting liver and hepatic tumors by integrating four efficient neural networks (ResNet152, ResNeXt101, DenseNet201, and InceptionV3). These classifiers are independently operated, and a final result is obtained by postprocess to eliminate artifacts. The obtained results were better than those obtained by the individual networks. In fact, concerning liver and pancreatic images, the use of AI algorithms is already a reality for speeding up repetitive tasks, such as segmentation, acquiring new quantitative parameters, such as lesion volume and tumor burden, improving image quality, reducing scanning time, and optimizing imaging acquisition [ 95 ].
Diabetic retinopathy (DR) is a significant cause of blindness globally, and early detection and intervention can help change the outcomes of the disease. AI techniques, including deep learning and convolutional neural networks (CNN), have been applied to the analysis of retinal images for DR screening and diagnosis [ 96 ]. Some studies have shown promising results in detecting referable diabetic retinopathy (rDR) using AI algorithms with high sensitivity and specificity compared to human graders [ 97 ], while reducing the associated human resources. For example, a study using a deep learning-based AI system achieved 97.05% sensitivity, 93.4% specificity, and 99.1% area under the curve (AUC) in classifying rDR as moderate or worse diabetic retinopathy, referable diabetic macular edema, or both [ 97 ]. Nevertheless, there are also shortcomings, such as the lack of standards for development and evaluation and the limited scope of application [ 98 ].
AI can also help in the detection and prediction of age-related macular degeneration (AMD). AI-based systems can screen for AMD and predict which patients are likely to progress to late-stage AMD within two years [ 99 ]. AI algorithms can provide analyses to assist physicians in diagnosing conditions based on specific features extrapolated from retinal images [ 100 ].
Yet in this area, optical coherence tomography (OCT) is a valuable tool in diagnosing various eye conditions and is where artificial intelligence (AI) can successfully be used. AI-assisted OCT has several advantages and applications in ophthalmology for diagnosis, monitoring, and disease-progression estimation (e.g., for glaucoma, macular edema, or age-related macular degeneration) [ 101 ]. AI-assisted OCT can provide more accurate and sensitive results compared to traditional methods [ 102 ]. For example, an OCT-AI-based telemedicine platform achieved a sensitivity of 96.6% and specificity of 98.8% for detecting urgent cases, and a sensitivity of 98.5% and specificity of 96.2% for detecting both urgent and routine cases [ 103 ].
These tools can lead to more efficient and objective ways of diagnosing and managing eye conditions.
4.2. Imaging and Modeling Techniques for Surgical Planning and Intervention
Imaging and 3D modeling techniques, coupled with the power of artificial intelligence (AI), have revolutionized the field of surgical planning and intervention, offering numerous advantages to both patients and healthcare professionals. By leveraging the capabilities of AI, medical imaging data, such as CT scans and MRI images, can be transformed into detailed three-dimensional models that provide an enhanced understanding of a patient’s anatomy. This newfound precision and depth of information allow surgeons to plan complex procedures with greater accuracy, improving patient outcomes and minimizing risks. Furthermore, AI-powered algorithms can analyze vast amounts of medical data, assisting surgeons in real-time during procedures, guiding them with valuable insights, and enabling personalized surgical interventions. For example, in [ 49 ], a new deep learning (DL)-based tool for segmenting anatomical structures of the left heart from echocardiographic images is proposed. It results from a combination of the YOLOv7 algorithm and U-net, specifically addressing segmentation of echocardiographic images into LVendo, LVepi, and LA.
Additionally, the integration of 3D printing technology with imaging and 3D modeling techniques further amplifies the advantages of surgical planning and intervention. With 3D printing, these intricate anatomical models can be translated into physical objects, allowing surgeons to hold and examine patient-specific replicas before the actual procedure. This tangible representation aids in comprehending complex anatomical structures, identifying potential challenges, and refining surgical strategies. Surgeons can also utilize 3D-printed surgical guides and implants, customized to fit each patient’s unique anatomy, thereby enhancing precision and reducing operative time.
These benefits are described and explored in [ 104 ], covering the operative workflow involved in the process of creating 3D-printed models of the heart using computed tomography (CT) scans. The authors begin by emphasizing the importance of accurate anatomical models in surgical planning, particularly in complex cardiac cases. They also discuss how 3D printing technology has gained prominence in the medical field, allowing for the creation of patient-specific anatomical models. In their developments, they thoroughly describe the operative workflow for generating 3D-printed heart models. Throughout the process, the challenges and limitations of the operative workflow from CT to 3D printing of the heart are covered. They also discuss factors such as cost, time, expertise required, and the need for validation studies to ensure the accuracy and reliability of the printed models.
A similar topic is presented in [ 105 ]. Here the authors focus specifically on coronary artery bypass graft (CABG) procedures and describe the feasibility of using a 3D modeling and printing process to create surgical guides, contributing to the success of the surgery and enhancing patient outcomes. In this paper, the authors also discuss the choice of materials for the 3D-printed guide, considering biocompatibility and sterility requirements. In addition, a case study that demonstrates the successful application of the workflow in a real clinical scenario is presented.
The combination of AI-driven imaging, 3D modeling, and 3D printing technologies revolutionizes surgical planning and intervention, empowering healthcare professionals with unparalleled tools to improve patient outcomes, create personalized solutions, and redefine the future of surgical practice. These advancements in imaging and 3D modeling techniques, driven by AI, are driving a new era of surgical precision and innovation in healthcare.
4.3. Image and Model Enhancement for Improved Analysis
Decision-making and diagnosis are important purposes for clinical applications, but AI can also play an important role in other applications of the clinical process. For example, in [ 106 ] the authors focus on the application of colorization techniques to medical images, with the goal of enhancing the visual interpretation and analysis by adding chromatic information. The authors highlight the importance of color in medical imaging as it can provide additional information for diagnosis, treatment planning, and educational purposes. They also address the challenges associated with medical image colorization, including the large variability in image characteristics and the need for robust and accurate colorization methods. The proposed method utilizes a spatial mask-guided colorization with a generative adversarial network (SMCGAN) technique to focus on relevant regions of the medical image while preserving important structural information during the process. The evaluation was based on a dataset from the Visible Human Project [ 107 ] and from the prostate dataset NCI-ISBI 2013 [ 108 ]. With the presented experimental setup and evaluation metrics used for performance assessment, the proposed technique was able to outperform the state-of-the-art GAN-based image colorization approaches with an average improvement of 8.48% in the peak signal-to-noise ratio (PSNR) metric.
In complex healthcare scenarios, it is crucial for clinicians and practitioners to understand the reasoning behind AI models’ predictions and recommendations. Explainable AI (XAI) plays a pivotal role in the domain of medical imaging techniques for decision support, where transparency and interpretability are paramount. In [ 9 ], the authors address the problem of nuclei detection in histopathology images, which is a crucial task in digital pathology for diagnosing and studying diseases. They specifically propose a technique called NDG-CAM (nuclei detection in histopathology images with semantic segmentation networks and Grad-CAM). Grad-CAM (gradient-weighted class activation mapping) [ 109 ] is a technique used in computer vision and deep learning to visualize and interpret the regions of an image that are most influential in the prediction made by a convolutional neural network. Hence, in the proposed methodology, the semantic segmentation network aims to accurately segment the nuclei regions in histopathology images, while Grad-CAM helps visualize the important regions that contribute to the model’s predictions, helping to improve the accuracy and interpretability of nuclei detection. The authors compare the performance of their method with other existing nuclei detection methods, demonstrating that NDG-CAM achieves improved accuracy while providing interpretable results.
Still with the purpose of making AI provide human understandable results, the authors in [ 110 ] focus on the development of an open-source COVID-19 CT dataset that includes automatic lung tissue classification for radiomics analysis. The challenges associated with COVID-19 research, including the importance of large-scale datasets and efficient analysis methods are covered. The potential of radiomics, which involves extracting quantitative features from medical images, in aiding COVID-19 diagnosis, prognosis, and treatment planning, are also mentioned. The proposed dataset consists of CT scans from COVID-19 patients, which are annotated with labels indicating different lung tissue regions, such as ground-glass opacities, consolidations, and normal lung tissue.
Novel machine learning techniques are also being used to enhance the resolution and quality of medical images [ 111 ]. These techniques aim to recover fine details and structures that are lost or blurred in low-resolution images, which can improve the diagnosis and treatment of various diseases. One of the novel machine learning techniques is based on GANs. For example, Bing at al. [ 112 ] propose the use of an improved squeeze-and-excitation block that selectively amplifies the important features and suppresses the nonimportant ones in the feature maps. A simplified EDSR (enhanced deep super-resolution) model to generate high-resolution images from low-resolution inputs is also proposed, along with a new fusion loss function. The proposed method was evaluated on public medical image datasets and compared with state-of-the-art deep learning-based methods, such as SRGAN, EDSR, VDSR, and D-DBPN. The results show that the proposed method achieves better visual quality and preserves more details, especially for high upscaling factors.
Vision transformers, with their ability to treat images as sequences of tokens and to learn global dependencies among them, can capture long-range and complex patterns in images, which can benefit super-resolution tasks. Zhu et al. [ 113 ] propose the use of vision transformers with residual dense connections and local feature fusion. This method proposes an efficient vision transformer architecture that can achieve high-quality single-image super-resolution for various medical modalities, such as MRI, CT, and X-ray. The key idea is to use residual dense blocks to enhance the feature extraction and representation capabilities of the vision transformer and to use local feature fusion to combine the low-level and high-level features for better reconstruction. Moreover, this method also introduces a novel perceptual loss function that incorporates prior knowledge of medical image segmentation to improve the image quality of desired aspects, such as edges, textures, and organs. In another work, Wei et al. [ 114 ] propose to adapt the SWIN transformer, which is a hierarchical vision transformer that uses shifted windows to capture local and global information, to the task of automatic medical image segmentation. The high-resolution SWIN transformer uses a U-net-like architecture that consists of an encoder and a decoder. The encoder converts the high-resolution input image into low-resolution feature maps using a sequence of SWIN transformer blocks, and the decoder gradually generates high-resolution representations from low-resolution feature maps using upsampling and skip connections. The high-resolution SWIN transformer can achieve state-of-the-art results on several medical image segmentation datasets, such as BraTS, LiTS, and KiTS (details below).
In addition, perceptual loss functions can be used to further enhance generative techniques. These are designed to measure the similarity between images in terms of their semantic content and visual quality rather than their pixel-wise differences. Perceptual loss functions can be derived from pretrained models, such as image classifiers or segmenters, that capture high-level features of images. By optimizing the perceptual loss functions, the super-resolution models can generate images that preserve the important structures and details of the original images while avoiding artifacts and distortions [ 112 , 115 ].
Medical images often suffer from noise, artifacts, and limited resolution due to the physical constraints of the imaging devices. Therefore, developing effective and efficient methods for medical image super-resolution is a challenging and promising research topic, searching to obtain previously unachievable details and resolution [ 116 , 117 ].
4.4. Medical Imaging Datasets
Numerous advancements outlined above have arisen through machine learning public challenges. These initiatives provided supporting materials in the form of datasets (which are often expensive and time consuming to collect) and, at times, baseline algorithms, contributing to the facilitation of various research studies aimed at the development and evaluation of novel algorithms. The promotion of a competitive objective was pivotal for promoting the development of a scientific community around a given topic. In Table 1 , some popular datasets are presented.
Examples of datasets with medical images.
| Name | Description | Reference |
|---|---|---|
| BRATS | The Multimodal Brain Tumor Segmentation Benchmark (BRATS) is an annual challenge that aims to compare different algorithms for brain tumor segmentation. The dataset, which has received several enhancements over the years, consists of preoperative multimodal MRI scans of glioblastoma and lower-grade glioma with ground truth labels and survival data for participants to segment and predict the tumor. | [ ] |
| KiTS | The Kidney Tumor Segmentation Benchmark (KiTS) is a dataset used to evaluate and compare algorithms for kidney tumor segmentation. The dataset consists of CT scans of the kidneys and kidney tumors, with 300 scans in total. The data and segmentations are provided by various clinical sites around the world. | [ ] |
| LiTS | The Liver Tumor Segmentation Benchmark (LiTS) is a dataset used to evaluate and compare liver tumor segmentation algorithms. The dataset consists of CT scans of the liver and liver tumors, with 130 scans in the training set and 70 scans in the test set. The data and segmentations are provided by various clinical sites around the world. | [ ] |
| MURA | The Musculoskeletal Radiographs (MURA) dataset is a large dataset of musculoskeletal radiographs containing 40,561 images from 14,863 studies. Each study is manually labeled by radiologists as either normal or abnormal. | [ ] |
| MedPix | A free online medical image database with over 59,000 indexed and curated images from over 12,000 patients. | [ ] |
| NIH Chest X-rays | A large dataset of chest X-ray images containing over 112,000 images from more than 30,000 unique patients. The images are labeled with 14 common disease labels. | [ ] |
5. Conclusions
Cutting-edge techniques that push the limits of current knowledge have been covered in this editorial. For those focused on the AI aspects of technology, evolutions have been reported in all stages of the medical imaging machine learning pipeline. As mentioned, the data-driven nature of these techniques requires that special attention is given to it. Beyond a high-quality dataset [ 110 ], attention can be given to the generation of more data [ 84 ] and better data [ 83 ]. The training process can be optimized to deal with small datasets [ 86 ], or techniques can be used to improve the parameter optimization process [ 80 ]. To better understand the models’ operating, we can use explainable AI techniques [ 9 ]. We can also focus on generating a better output by combining several classifiers [ 8 ] or by adding useful information, such as colors [ 106 ]. Many of the involved challenges throughout the process can address using a “bag of tricks” [ 76 ]. The advantages of using AI in medical imaging applications is explored in [ 77 ], and its ability to perform better than feature-based approaches is covered in [ 85 ]. Finally, applications of AI to 3D modeling and physical object generation are covered in [ 104 , 105 ].
The field of medical imaging and AI is evolving rapidly, driven by ongoing research and technological advancements. Researchers are continuously exploring novel algorithms, architectures, and methodologies to further enhance the capabilities of AI in medical imaging. Additionally, collaborations between clinicians, computer scientists, and industry professionals are vital in translating research findings into practical applications that can benefit patients worldwide.
In conclusion, the fusion of medical imaging and AI has brought about significant advancements in healthcare. From early disease detection to personalized diagnosis and therapy, AI has demonstrated its potential to revolutionize medical practice. By harnessing the power of AI, medical professionals can leverage the wealth of information contained within medical images to provide accurate diagnoses, tailor treatment plans, and improve patient outcomes. As technology continues to advance, we can expect even more groundbreaking innovations that will further transform the landscape of medical imaging and AI in the years to come.
Funding Statement
This research received no external funding.
Institutional Review Board Statement
Informed consent statement, data availability statement, conflicts of interest.
The author declares no conflict of interest.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content.
Authors writing articles containing math equations rely on using LaTeX, the industry standard for producing readable mathematics. IEEE authors can benefit from using Overleaf, which supports collaborative writing in LaTeX code or a visual editor. Now anyone can create and edit complex, beautifully formatted technical documents with ease.
Discover the Overleaf editor
Additional Resources
- Free online introduction to LaTeX (3 parts)
- Overleaf and LaTeX Resources feature new features and updates, webinars, Overleaf documentation, and the premium features guide
- IEEE Author Center for step-by-step guidance on the writing and publishing process
- Tools for IEEE Authors , which include the IEEE Publication Recommender to find the right periodical or conference for your research, and the IEEE Reference Preparation Assistant to verify your reference list
IEEE Official Templates

IEEE Community Templates

Get in touch
Have you checked our knowledge base ?
Message sent! Our team will review it and reply by email.
Email:
IEEE Article Templates
IEEE article templates let you quickly format your article and prepare a draft for peer review. Templates help with the placement of specific elements, such as the author list. They also provide guidance on stylistic elements such as abbreviations and acronyms.
Use the interactive IEEE Template Selector to find the template you need by following a few easy prompts and then downloading your template.
- Chinese (Simplified)
- Chinese (Traditional)
- License Manager Portal
Email Address*
IEEE P2020: Automotive System Image Quality
|
| |
| 2023: IEEE 2020-2024 undergoing comment resolution and recirculation
|
The IEEE‐SA P2020 working group on automotive imaging standards was established in order to address the considerable ambiguity in measurement of image quality of automotive imaging systems, both human and computer vision based. This white paper outlines the goals, achievements, rationale and plans of the subgroup, which has started to work on development of a new standard.Image quality plays a crucial role for both automotive viewing and automotive computer vision applications and today’s image evaluation approaches do not necessarily meet the needs of such applications.
Currently there is not a consistent approach within the industry to measure automotive image quality. The IEEE P2020 working group is attempting to remedy these deficiencies by connecting people in the field, identifying gaps in existing standards, and working to address these by creating a coherent set of key performance indicators by which camera systems and components may be evaluated in a manner consistent with their intended use. This white paper provides an overview of current activities including initial gap analysis and details of what may be expected from the full standard when published.
Download the P2020 White Paper
- New IEEE P2020 Automotive Image Quality White Paper
- Sharpness: What is it and How it is Measured
- Noise in photographic images
- Stray Light (Flare) Solutions
- Imatest Ultra-High Illumination Flickering LED Lightbox
- Contrast Detection Probability
IEEE Account
- Change Username/Password
- Update Address
Purchase Details
- Payment Options
- Order History
- View Purchased Documents
Profile Information
- Communications Preferences
- Profession and Education
- Technical Interests
- US & Canada: +1 800 678 4333
- Worldwide: +1 732 981 0060
- Contact & Support
- About IEEE Xplore
- Accessibility
- Terms of Use
- Nondiscrimination Policy
- Privacy & Opting Out of Cookies
A not-for-profit organization, IEEE is the world's largest technical professional organization dedicated to advancing technology for the benefit of humanity. © Copyright 2024 IEEE - All rights reserved. Use of this web site signifies your agreement to the terms and conditions.
IMAGES
VIDEO
COMMENTS
This paper comprehensively overviews image and signal processing, including their fundamentals, advanced techniques, and applications. Image processing involves analyzing and manipulating digital images, while signal processing focuses on analyzing and interpreting signals in various domains. The fundamentals encompass digital signal representation, Fourier analysis, wavelet transforms ...
2024 IEEE NSS MIC RTSD, 26 OCT - 2 NOV 2024, Tampa, Florida, USA. Contact Us. Call for Papers. Special Issue on Advancements in Foundation Models for Medical Imaging (Submission Deadline: July 1, 2024. No extension.) Announcement. Search for next IEEE TMI Editor-in-Chief (Open to Applications till July 31st, 2024) A Publication of. Sponsor ...
Ankylosing Spondylitis (AS) is a chronic inflammat ory disease that affects the axial spine and peripheral joints, manifesting through symptoms such as spinal stiffness, back pain, and joint involvement. Medical imaging, particularly X-rays and MRIs, is essential for diagnosing AS and monitoring its progression. Recent advancements in artificial intelligence (AI), especially deep learning ...
Recent advancements in thermal imaging sensor technology have resulted in the use of thermal cameras in a variety of applications, including automotive, industrial, medical, defense and space, agriculture, and other related fields. Thermal imaging, unlike RGB imaging, does not rely on background light, and the technique is nonintrusive while also protecting privacy. This review article focuses ...
The 2025 IEEE International Symposium on Biomedical Imaging (ISBI) Call for Papers is now open! ISBI 2025 will be held in Houston, Texas, United States, from 14-17 April 2024. This vibrant setting provides unparalleled opportunities to bridge the gap between cutting-edge biomedical imaging technologies and frontline clinicians, ultimately enhancing patient care.
The focus of the journal is on unifying the sciences of medicine, biology, and imaging. It emphasizes the common ground where instrumentation, hardware, software, mathematics, physics, biology, and medicine interact through new analysis methods. Strong application papers that describe novel methods are particularly encouraged.
IEEE Access Editor-in-Chief: Michael Pecht, Professor and Director, CALCE, University of Maryland. Paper submission: Contact Associate Editor and submit manuscript to: http: // ieee.atyponrex.com /journal /ieee -access. For inquiries regarding this Special Section, please contact: [email protected].
General Program 61876032, the Key-Area Research and Development Pro-gram of Guangdong Province, China (No. 2018B010111001), the National ... 2 PUBLISHED IN IEEE TRANSACTIONS ON MEDICAL IMAGING, VOL. 40, NO. 10, OCTOBER 2021 necessitating rapid algorithm development. However, it is more
IEEE Photonics Journal is an online-only rapid publication archival journal of top quality research at the forefront of photonics. Photonics integrates quantum electronics and optics to accelerate progress in the generation of novel photon sources and in their utilization in emerging applications at the micro and nano scales spanning from the far-infrared/THz to the x-ray region of the ...
Foundation models, e.g., ChatGPT/GPT-4/GPT-4V, at the forefront of artificial intelligence (AI) and deep learning, represent a pivotal leap in the domain of computational intelligence. This special issue aims to explore and showcase cutting-edge research in the development and application of foundation models for medical imaging within the field of healthcare. Οriginal and innovative ...
With the rapid evolution of the field of computer science, automatic diagnosis of medical images has become possible. This paper introduces the latest research progress and application of deep learning in the medical field. First of all, this paper introduces several common diseases, including the Alzheimer's disease, lung cancer, breast cancer, glaucoma, and diabetic eye disease, etc ...
IEEE TRANSACTIONS ON MEDICAL IMAGING, VOL. XX, NO. XX, XXXX 2020 1 Reading Radiology Imaging Like The Radiologist ... Considerable progress has been made in research on image captioning, with most frameworks adopting an ... PREPARATION OF PAPERS FOR IEEE TRANSACTIONS ON MEDICAL IMAGING 3 With the development of attention mechanisms [9], trans- ...
This review introduces the machine learning algorithms as applied to medical image analysis, focusing on convolutional neural networks, and emphasizing clinical aspects of the field. The advantage of machine learning in an era of medical big data is that significant hierarchal relationships within the data can be discovered algorithmically ...
Submit Your Article. After checking that your article complies with the target journal's submission guidelines, you are ready to submit. Click the Submit Your Manuscript button on the journal's home page on IEEE Xplore. You will be taken to the journal's online submission system, which will walk you through the submission process.
Lung imaging has been a subject of extensive research interest [81,82], primarily due to the aggressive nature of lung cancer and its tendency to be detected at an advanced stage, leading to high mortality rates among cancer patients. In this context, accurate segmentation of lung fields in medical imaging plays a crucial role in the detection ...
The advent of magnetic resonance imaging (MRI) and functional magnetic resonance imaging (fMRI) of the brain has changed forever conventional patient diagnosis and treatment in medicine. Instead of employing invasive procedures, now physicians can not just literally see internal body structures but also understand and map more clearly brain functions related to specific tasks, feelings, and ...
IEEE template by Michael Shell. IEEE Conference Template Official. This demo file is intended to serve as a "starter file'' for IEEE conference papers produced under LaTeX. This is one of a number of templates using the IEEE style that are available on Overleaf to help you get started - use the tags below to find more.
Find the right IEEE article template for your target publication. Please select your publication type below. Transactions, Journals and Letters. Magazines. Conferences. Use the IEEE Publication Recommender if you don't know where you want to publish. Contact & Support. Accessibility.
IEEE article templates let you quickly format your article and prepare a draft for peer review. Templates help with the placement of specific elements, such as the author list. They also provide guidance on stylistic elements such as abbreviations and acronyms. Use the interactive IEEE Template Selector to find the template you need by ...
This paper reviews state-of-the-art research solutions across the spectrum of medical imaging informatics, discusses clinical translation, and provides future directions for advancing clinical practice. More specifically, it summarizes advances in medical imaging acquisition technologies for different modalities, highlighting the necessity for efficient medical data management strategies in ...
IEEE 2020-2024 draft standard. Technical Committee: IEEE-SA Working Group P2020: Publication: 2023: IEEE 2020-2024 undergoing comment resolution and recirculation. October 2018: IEEE P2020 Automtive Imaging White Paper
However, image enhancement technology is also affected by viewing conditions, imaging mode and working tasks, so appropriate methods should be selected appropriately. This paper introduces several commonly used image enhancement algorithms, with emphasis on spatial domain processing. The process of image enhancement is a contradictory one.
This paper first expounds the research status for artificial intelligence technology in medical imaging diagnosis, and illustrates the importance of computer-aided diagnosis with examples; Secondly, the current bottlenecks in the development of computer-aided diagnosis technology are analyzed in detail from the aspects of technology, industry and application; Finally, based on the previous ...
By analyzing 58 research papers, with a particular emphasis on the most frequently cited papers from each year up to 2023, we shed light on the field's current state, identifying key advancements and challenges. ... IEEE is the world's largest technical professional organization dedicated to advancing technology for the benefit of humanity ...
This paper proposes a hybrid RF/FSO system based on RIS reflection to interfere with eavesdroppers in FSO eavesdropping scenarios, and analyzes and optimizes the physical layer security performance of this communication system. In this work, the RF link experiences Nakagama-m distribution, there is a single-antenna eavesdropper E1 trying to eavesdrop on the RF link information, and the RIS ...